API Reference Guide#
Introduction#
rocBLAS is the AMD library for Basic Linear Algebra Subprograms (BLAS) on the ROCm platform . It is implemented in the HIP programming language and optimized for AMD GPUs.
The aim of rocBLAS is to provide:
Functionality similar to Legacy BLAS, adapted to run on GPUs
High-performance robust implementation
rocBLAS is written in C++17 and HIP. It uses the AMD ROCm runtime to run on GPU devices.
The rocBLAS API is a thin C99 API using the Hourglass Pattern. It contains:
[Level1], [Level2], and [Level3] BLAS functions, with batched and strided_batched versions
Extensions to Legacy BLAS, including functions for mixed precision
Auxiliary functions
Device Memory functions
Note
The official rocBLAS API is the C99 API defined in rocblas.h. Therefore the use of any other public symbols is discouraged. All other C/C++ interfaces may not follow a deprecation model and so can change without warning from one release to the next.
rocBLAS array storage format is column major and one based. This is to maintain compatibility with the Legacy BLAS code, which is written in Fortran.
rocBLAS calls the AMD library Tensile for Level 3 BLAS matrix multiplication.
rocBLAS API and Legacy BLAS Functions#
rocBLAS is initialized by calling rocblas_create_handle, and it is terminated by calling rocblas_destroy_handle. The rocblas_handle is persistent, and it contains:
HIP stream
Temporary device work space
Mode for enabling or disabling logging (default is logging disabled)
rocBLAS functions run on the host, and they call HIP to launch rocBLAS kernels that run on the device in a HIP stream. The kernels are asynchronous unless:
The function returns a scalar result from device to host
Temporary device memory is allocated
In both cases above, the launch can be made asynchronous by:
Use rocblas_pointer_mode_device to keep the scalar result on the device. Note that it is only the following Level1 BLAS functions that return a scalar result: Xdot, Xdotu, Xnrm2, Xasum, iXamax, iXamin.
Use the provided device memory functions to allocate device memory that persists in the handle. Note that most rocBLAS functions do not allocate temporary device memory.
Before calling a rocBLAS function, arrays must be copied to the device. Integer scalars like m, n, k are stored on the host. Floating point scalars like alpha and beta can be on host or device.
Error handling is by returning a rocblas_status. Functions conform to the Legacy BLAS argument checking.
Rules for Obtaining rocBLAS API from Legacy BLAS#
The Legacy BLAS routine name is changed to lowercase and prefixed by rocblas_. For example: Legacy BLAS routine SSCAL, scales a vector by a constant, is converted to rocblas_sscal.
A first argument rocblas_handle handle is added to all rocBLAS functions.
Input arguments are declared with the const modifier.
Character arguments are replaced with enumerated types defined in rocblas_types.h. They are passed by value on the host.
Array arguments are passed by reference on the device.
Scalar arguments are passed by value on the host with the following exceptions. See the section Pointer Mode for more information on these exceptions:
Scalar values alpha and beta are passed by reference on either the host or the device.
Where Legacy BLAS functions have return values, the return value is instead added as the last function argument. It is returned by reference on either the host or the device. This applies to the following functions: xDOT, xDOTU, xNRM2, xASUM, IxAMAX, IxAMIN.
The return value of all functions is rocblas_status, defined in rocblas_types.h. It is used to check for errors.
Example Code#
Below is a simple example code for calling function rocblas_sscal:
#include <iostream>
#include <vector>
#include "hip/hip_runtime_api.h"
#include "rocblas.h"
using namespace std;
int main()
{
rocblas_int n = 10240;
float alpha = 10.0;
vector<float> hx(n);
vector<float> hz(n);
float* dx;
rocblas_handle handle;
rocblas_create_handle(&handle);
// allocate memory on device
hipMalloc(&dx, n * sizeof(float));
// Initial Data on CPU,
srand(1);
for( int i = 0; i < n; ++i )
{
hx[i] = rand() % 10 + 1; //generate a integer number between [1, 10]
}
// copy array from host memory to device memory
hipMemcpy(dx, hx.data(), sizeof(float) * n, hipMemcpyHostToDevice);
// call rocBLAS function
rocblas_status status = rocblas_sscal(handle, n, &alpha, dx, 1);
// check status for errors
if(status == rocblas_status_success)
{
cout << "status == rocblas_status_success" << endl;
}
else
{
cout << "rocblas failure: status = " << status << endl;
}
// copy output from device memory to host memory
hipMemcpy(hx.data(), dx, sizeof(float) * n, hipMemcpyDeviceToHost);
hipFree(dx);
rocblas_destroy_handle(handle);
return 0;
}
LP64 Interface#
The rocBLAS library is LP64, so rocblas_int arguments are 32 bit and rocblas_long arguments are 64 bit.
Column-major Storage and 1 Based Indexing#
rocBLAS uses column-major storage for 2D arrays, and 1-based indexing for the functions xMAX and xMIN. This is the same as Legacy BLAS and cuBLAS.
If you need row-major and 0-based indexing (used in C language arrays), download the file cblas.tgz from the Netlib Repository. Look at the CBLAS functions that provide a thin interface to Legacy BLAS. They convert from row-major, 0 based, to column-major, 1 based. This is done by swapping the order of function arguments. It is not necessary to transpose matrices.
Pointer Mode#
The auxiliary functions rocblas_set_pointer and rocblas_get_pointer are used to set and get the value of the state variable rocblas_pointer_mode. This variable is stored in rocblas_handle. If rocblas_pointer_mode == rocblas_pointer_mode_host, then scalar parameters must be allocated on the host. If rocblas_pointer_mode == rocblas_pointer_mode_device, then scalar parameters must be allocated on the device.
There are two types of scalar parameter:
Scaling parameters like alpha and beta used in functions like axpy, gemv, gemm 2
Scalar results from functions amax, amin, asum, dot, nrm2
For scalar parameters like alpha and beta when rocblas_pointer_mode == rocblas_pointer_mode_host, they can be allocated on the host heap or stack. The kernel launch is asynchronous, and if they are on the heap, they can be freed after the return from the kernel launch. When rocblas_pointer_mode == rocblas_pointer_mode_device they must not be changed till the kernel completes.
For scalar results, when rocblas_pointer_mode == rocblas_pointer_mode_host, then the function blocks the CPU till the GPU has copied the result back to the host. When rocblas_pointer_mode == rocblas_pointer_mode_device the function will return after the asynchronous launch. Similarly to vector and matrix results, the scalar result is only available when the kernel has completed execution.
Asynchronous API#
rocBLAS functions will be asynchronous unless:
The function needs to allocate device memory
The function returns a scalar result from GPU to CPU
The order of operations in the asynchronous functions is as in the figure below. The argument checking, calculation of process grid, and kernel launch take very little time. The asynchronous kernel running on the GPU does not block the CPU. After the kernel launch, the CPU keeps processing the next instructions.
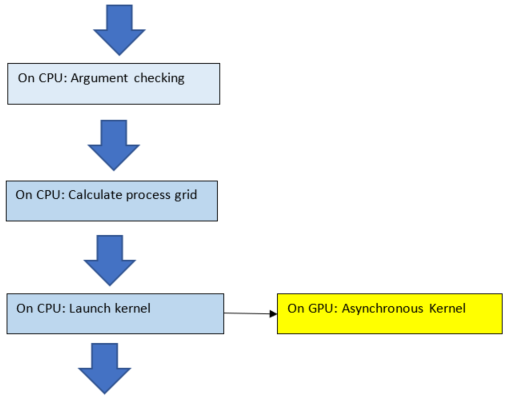
Fig. 1 Order of operations in asynchronous functions#
The above order of operations will change if there is logging or the function is synchronous. Logging requires system calls, and the program must wait for them to complete before executing the next instruction. See the Logging section for more information.
Note
The default is no logging.
If the cpu needs to allocate device memory, it must wait till this is complete before executing the next instruction. See the Device Memory Allocation section for more information.
Note
Memory can be preallocated. This will make the function asynchronous, as it removes the need for the function to allocate memory.
The following functions copy a scalar result from GPU to CPU if rocblas_pointer_mode == rocblas_pointer_mode_host: asum, dot, max, min, nrm2.
This makes the function synchronous, as the program must wait for the copy before executing the next instruction. See the section on Pointer Mode for more information.
Note
Set rocblas_pointer_mode to rocblas_pointer_mode_device makes the function asynchronous by keeping the result on the GPU.
The order of operations with logging, device memory allocation, and return of a scalar result is as in the figure below:
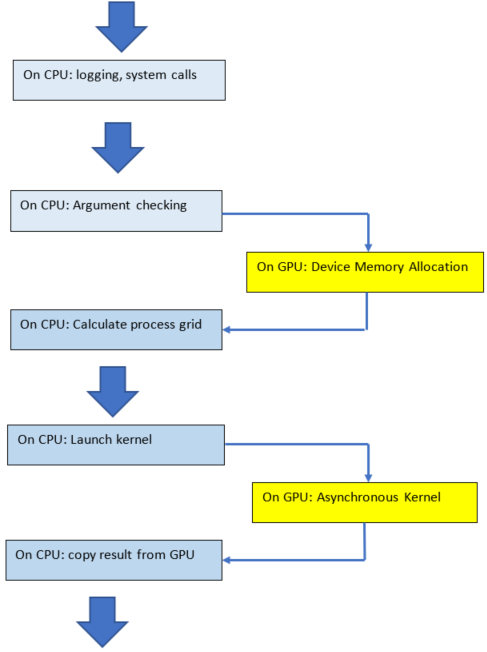
Fig. 2 Code blocks in synchronous function call#
Complex Number Data Types#
Data types for rocBLAS complex numbers in the API are a special case. For C compiler users, gcc, and other non-hipcc compiler users, these types are exposed as a struct with x and y components and identical memory layout to std::complex for float and double precision. Internally a templated C++ class is defined, but it should be considered deprecated for external use. For simplified usage with Hipified code there is an option to interpret the API as using hipFloatComplex and hipDoubleComplex types (i.e. typedef hipFloatComplex rocblas_float_complex). This is provided for users to avoid casting when using the hip complex types in their code. As the memory layout is consistent across all three types, it is safe to cast arguments to API calls between the 3 types: hipFloatComplex, std::complex<float>, and rocblas_float_complex, as well as for the double precision variants. To expose the API as using the hip defined complex types, user can use either a compiler define or inlined #define ROCM_MATHLIBS_API_USE_HIP_COMPLEX before including the header file <rocblas.h>. Thus the API is compatible with both forms, but recompilation is required to avoid casting if switching to pass in the hip complex types. Most device memory pointers are passed with void* types to hip utility functions (e.g. hipMemcpy), so uploading memory from std::complex arrays or hipFloatComplex arrays requires no changes regardless of complex data type API choice.
MI100 (gfx908) Considerations#
On nodes with the MI100 (gfx908), MFMA (Matrix-Fused-Multiply-Add) instructions are available to substantially speed up matrix operations. This hardware feature is used in all gemm and gemm-based functions in rocBLAS with 32-bit or shorter base datatypes with an associated 32-bit compute_type (f32_r, i32_r, or f32_c as appropriate).
Specifically, rocBLAS takes advantage of MI100’s MFMA instructions for three real base types f16_r, bf16_r, and f32_r with compute_type f32_r, one integral base type i8_r with compute_type i32_r, and one complex base type f32_c with compute_type f32_c. In summary, all GEMM APIs and APIs for GEMM-based functions using these five base types and their associated compute_type (explicit or implicit) take advantage of MI100’s MFMA instructions.
Note
The use of MI100’s MFMA instructions is automatic. There is no user control for on/off.
Not all problem sizes may select MFMA-based kernels; additional tuning may be needed to get good performance.
MI200 (gfx90a) Considerations#
On nodes with the MI200 (gfx90a), MFMA_F64 instructions are available to substantially speed up double precision matrix operations. This hardware feature is used in all GEMM and GEMM-based functions in rocBLAS with 64-bit floating-point datatype, namely DGEMM, ZGEMM, DTRSM, ZTRSM, DTRMM, ZTRMM, DSYRKX, and ZSYRKX.
The MI200 MFMA_F16, MFMA_BF16 and MFMA_BF16_1K instructions flush subnormal input/output data (“denorms”) to zero. It is observed that certain use cases utilizing the HPA (High Precision Accumulate) HGEMM kernels where a_type=b_type=c_type=d_type=f16_r and compute_type=f32_r do not tolerate the MI200’s flush-denorms-to-zero behavior well due to F16’s limited exponent range. An alternate implementation of the HPA HGEMM kernel utilizing the MFMA_BF16_1K instruction is provided which, takes advantage of BF16’s much larger exponent range, albeit with reduced accuracy. To select the alternate implementation of HPA HGEMM with the gemm_ex/gemm_strided_batched_ex functions, for the flags argument, use the enum value of rocblas_gemm_flags_fp16_alt_impl.
Note
The use of MI200’s MFMA instructions (including MFMA_F64) is automatic. There is no user control for on/off.
Not all problem sizes may select MFMA-based kernels; additional tuning may be needed to get good performance.
Deprecations by version#
Announced in rocBLAS 2.45#
Replace is_complex by rocblas_is_complex#
From rocBLAS 3.0 the trait is_complex for rocblas complex types has been removed. Replace with rocblas_is_complex
Replace truncate with rocblas_truncate#
From rocBLAS 3.0 enum truncate_t and the value truncate has been removed and replaced by rocblas_truncate_t and rocblas_truncate, respectively.
Announced in rocBLAS 2.46#
Remove ability for hipBLAS to set rocblas_int8_type_for_hipblas#
From rocBLAS 3.0 remove enum rocblas_int8_type_for_hipblas and the functions rocblas_get_int8_type_for_hipblas and rocblas_set_int8_type_for_hipblas. These are used by hipBLAS to select either int8_t or packed_int8x4 datatype. In hipBLAS the option to use packed_int8x4 will be removed, only int8_t will be available.
Announced in rocBLAS 3.0#
Replace Legacy BLAS in-place trmm functions with trmm functions that support both in-place and out-of-place functionality#
Use of the deprecated Legacy BLAS in-place trmm functions will give deprecation warnings telling you to compile with -DROCBLAS_V3 and use the new in-place and out-of-place trmm functions.
Note that there are no deprecation warnings for the rocBLAS Fortran API.
The Legacy BLAS in-place trmm calculates B <- alpha * op(A) * B. Matrix B is replaced in-place by triangular matrix A multiplied by matrix B. The prototype in the include file rocblas-functions.h is:
rocblas_status rocblas_strmm(rocblas_handle handle,
rocblas_side side,
rocblas_fill uplo,
rocblas_operation transA,
rocblas_diagonal diag,
rocblas_int m,
rocblas_int n,
const float* alpha,
const float* A,
rocblas_int lda,
float* B,
rocblas_int ldb);
rocBLAS 3.0 deprecates the legacy BLAS trmm functionality and replaces it with C <- alpha * op(A) * B. The prototype is:
rocblas_status rocblas_strmm(rocblas_handle handle,
rocblas_side side,
rocblas_fill uplo,
rocblas_operation transA,
rocblas_diagonal diag,
rocblas_int m,
rocblas_int n,
const float* alpha,
const float* A,
rocblas_int lda,
const float* B,
rocblas_int ldb,
float* C,
rocblas_int ldc);
The new API provides the legacy BLAS in-place functionality if you set pointer C equal to pointer B and ldc equal to ldb.
There are similar deprecations for the _batched and _strided_batched versions of trmm.
Remove rocblas_gemm_ext2#
rocblas_gemm_ext2 is deprecated and it will be removed in the next major release of rocBLAS.
Removal of rocblas_query_int8_layout_flag#
rocblas_query_int8_layout_flag will be removed and support will end for the rocblas_gemm_flags_pack_int8x4 enum in rocblas_gemm_flags in a future release. rocblas_int8_type_for_hipblas will remain until rocblas_query_int8_layout_flag is removed.
Remove user_managed mode from rocblas_handle#
From rocBLAS 4.0, the schemes for allocating temporary device memory would be reduced to two from four.
Existing four schemes are:
rocblas_managed
user_managed, preallocate
user_managed, manual
user_owned
From rocBLAS 4.0, the two schemes would be rocblas_managed and user_owned. The functionality of user_managed ( both preallocate and manual) would be combined into rocblas_managed scheme.
Due to this the following APIs would be affected:
rocblas_is_user_managing_device_memory() will be removed.
rocblas_set_device_memory_size() will be replaced by a future function rocblas_increase_device_memory_size(), this new API would allow users to increase the device memory pool size at runtime.
Announced in rocBLAS 3.1#
Removal of __STDC_WANT_IEC_60559_TYPES_EXT__ define#
Prior to rocBLAS 4.0, __STDC_WANT_IEC_60559_TYPES_EXT__ was defined in rocblas.h, or more specifically rocblas-types.h, before including float.h. From rocBLAS 4.0, this define will be removed. Users who want ISO/IEC TS 18661-3:2015 functionality must define __STDC_WANT_IEC_60559_TYPES_EXT__ before including float.h and rocblas.h.
Removed in rocBLAS 4.0#
rocblas_gemm_ext2 removed#
As announced earlier, rocblas_gemm_ext2 was removed in 4.0.
Using rocBLAS API#
This section describes how to use the rocBLAS library API.
rocBLAS Datatypes#
rocblas_handle#
-
typedef struct _rocblas_handle *rocblas_handle#
rocblas_handle is a structure holding the rocblas library context. It must be initialized using rocblas_create_handle(), and the returned handle must be passed to all subsequent library function calls. It should be destroyed at the end using rocblas_destroy_handle().
rocblas_int#
-
typedef int32_t rocblas_int#
To specify whether int32 is used for LP64 or int64 is used for ILP64.
rocblas_stride#
-
typedef int64_t rocblas_stride#
Stride between matrices or vectors in strided_batched functions.
rocblas_half#
-
struct rocblas_half#
Structure definition for rocblas_half.
rocblas_bfloat16#
-
struct rocblas_bfloat16#
Struct to represent a 16 bit Brain floating-point number.
rocblas_float_complex#
-
struct rocblas_float_complex#
Struct to represent a complex number with single precision real and imaginary parts.
rocblas_double_complex#
-
struct rocblas_double_complex#
Struct to represent a complex number with double precision real and imaginary parts.
rocBLAS Enumeration#
Enumeration constants have numbering that is consistent with CBLAS, ACML, most standard C BLAS libraries
rocblas_operation#
-
enum rocblas_operation#
Used to specify whether the matrix is to be transposed or not.
Parameter constants. numbering is consistent with CBLAS, ACML and most standard C BLAS libraries
Values:
-
enumerator rocblas_operation_none#
Operate with the matrix.
-
enumerator rocblas_operation_transpose#
Operate with the transpose of the matrix.
-
enumerator rocblas_operation_conjugate_transpose#
Operate with the conjugate transpose of the matrix.
-
enumerator rocblas_operation_none#
rocblas_fill#
rocblas_diagonal#
rocblas_side#
-
enum rocblas_side#
Indicates the side matrix A is located relative to matrix B during multiplication.
Values:
-
enumerator rocblas_side_left#
Multiply general matrix by symmetric, Hermitian, or triangular matrix on the left.
-
enumerator rocblas_side_right#
Multiply general matrix by symmetric, Hermitian, or triangular matrix on the right.
-
enumerator rocblas_side_both#
-
enumerator rocblas_side_left#
rocblas_status#
-
enum rocblas_status#
rocblas status codes definition
Values:
-
enumerator rocblas_status_success#
Success
-
enumerator rocblas_status_invalid_handle#
Handle not initialized, invalid or null
-
enumerator rocblas_status_not_implemented#
Function is not implemented
-
enumerator rocblas_status_invalid_pointer#
Invalid pointer argument
-
enumerator rocblas_status_invalid_size#
Invalid size argument
-
enumerator rocblas_status_memory_error#
Failed internal memory allocation, copy or dealloc
-
enumerator rocblas_status_internal_error#
Other internal library failure
-
enumerator rocblas_status_perf_degraded#
Performance degraded due to low device memory
-
enumerator rocblas_status_size_query_mismatch#
Unmatched start/stop size query
-
enumerator rocblas_status_size_increased#
Queried device memory size increased
-
enumerator rocblas_status_size_unchanged#
Queried device memory size unchanged
-
enumerator rocblas_status_invalid_value#
Passed argument not valid
-
enumerator rocblas_status_continue#
Nothing preventing function to proceed
-
enumerator rocblas_status_check_numerics_fail#
Will be set if the vector/matrix has a NaN/Infinity/denormal value
-
enumerator rocblas_status_success#
rocblas_datatype#
-
enum rocblas_datatype#
Indicates the precision width of data stored in a blas type.
Parameter constants. Numbering continues into next free decimal range but not shared with other BLAS libraries
Values:
-
enumerator rocblas_datatype_f16_r#
16-bit floating point, real
-
enumerator rocblas_datatype_f32_r#
32-bit floating point, real
-
enumerator rocblas_datatype_f64_r#
64-bit floating point, real
-
enumerator rocblas_datatype_f16_c#
16-bit floating point, complex
-
enumerator rocblas_datatype_f32_c#
32-bit floating point, complex
-
enumerator rocblas_datatype_f64_c#
64-bit floating point, complex
-
enumerator rocblas_datatype_i8_r#
8-bit signed integer, real
-
enumerator rocblas_datatype_u8_r#
8-bit unsigned integer, real
-
enumerator rocblas_datatype_i32_r#
32-bit signed integer, real
-
enumerator rocblas_datatype_u32_r#
32-bit unsigned integer, real
-
enumerator rocblas_datatype_i8_c#
8-bit signed integer, complex
-
enumerator rocblas_datatype_u8_c#
8-bit unsigned integer, complex
-
enumerator rocblas_datatype_i32_c#
32-bit signed integer, complex
-
enumerator rocblas_datatype_u32_c#
32-bit unsigned integer, complex
-
enumerator rocblas_datatype_bf16_r#
16-bit bfloat, real
-
enumerator rocblas_datatype_bf16_c#
16-bit bfloat, complex
-
enumerator rocblas_datatype_invalid#
Invalid datatype value, do not use
-
enumerator rocblas_datatype_f16_r#
rocblas_pointer_mode#
-
enum rocblas_pointer_mode#
Indicates if scalar pointers are on host or device. This is used for scalars alpha and beta and for scalar function return values.
Values:
-
enumerator rocblas_pointer_mode_host#
Scalar values affected by this variable are located on the host.
-
enumerator rocblas_pointer_mode_device#
Scalar values affected by this variable are located on the device.
-
enumerator rocblas_pointer_mode_host#
rocblas_atomics_mode#
-
enum rocblas_atomics_mode#
Indicates if atomics operations are allowed. Not allowing atomic operations may generally improve determinism and repeatability of results at a cost of performance.
Values:
-
enumerator rocblas_atomics_not_allowed#
Algorithms will refrain from atomics where applicable.
-
enumerator rocblas_atomics_allowed#
Algorithms will take advantage of atomics where applicable.
-
enumerator rocblas_atomics_not_allowed#
rocblas_layer_mode#
-
enum rocblas_layer_mode#
Indicates if layer is active with bitmask.
Values:
-
enumerator rocblas_layer_mode_none#
No logging will take place.
-
enumerator rocblas_layer_mode_log_trace#
A line containing the function name and value of arguments passed will be printed with each rocBLAS function call.
-
enumerator rocblas_layer_mode_log_bench#
Outputs a line each time a rocBLAS function is called, this line can be used with rocblas-bench to make the same call again.
-
enumerator rocblas_layer_mode_log_profile#
Outputs a YAML description of each rocBLAS function called, along with its arguments and number of times it was called.
-
enumerator rocblas_layer_mode_none#
rocblas_gemm_algo#
rocblas_gemm_flags#
-
enum rocblas_gemm_flags#
Control flags passed into gemm algorithms invoked by Tensile Host.
Values:
-
enumerator rocblas_gemm_flags_none#
Default empty flags.
-
enumerator rocblas_gemm_flags_pack_int8x4#
Before ROCm 4.2, this flags is not implemented and rocblas uses packed-Int8x4 by default. After ROCm 4.2, set flag is neccesary if we want packed-Int8x4. Default (0x0) uses unpacked. As of rocBLAS 3.0 in ROCm 5.6, rocblas_gemm_flags_pack_int8x4 is deprecated and support will be removed in a future release.
-
enumerator rocblas_gemm_flags_use_cu_efficiency#
Select the gemm problem with the highest efficiency per compute unit used. Useful for running multiple smaller problems simultaneously. This takes precedence over the performance metric set in rocblas_handle and currently only works for gemm_*_ex problems.
-
enumerator rocblas_gemm_flags_fp16_alt_impl#
Select an alternate implementation for the MI200 FP16 HPA (High Precision Accumulate) GEMM kernel utilizing the BF16 matrix instructions with reduced accuracy in cases where computation cannot tolerate the FP16 matrix instructions flushing subnormal FP16 input/output data to zero. See the “MI200 (gfx90a) Considerations” section for more details.
-
enumerator rocblas_gemm_flags_check_solution_index#
-
enumerator rocblas_gemm_flags_fp16_alt_impl_rnz#
-
enumerator rocblas_gemm_flags_none#
rocBLAS Helper functions#
Auxiliary Functions#
-
rocblas_status rocblas_create_handle(rocblas_handle *handle)#
Create handle.
-
rocblas_status rocblas_destroy_handle(rocblas_handle handle)#
Destroy handle.
-
rocblas_status rocblas_set_stream(rocblas_handle handle, hipStream_t stream)#
Set stream for handle.
-
rocblas_status rocblas_get_stream(rocblas_handle handle, hipStream_t *stream)#
Get stream [0] from handle.
-
rocblas_status rocblas_set_pointer_mode(rocblas_handle handle, rocblas_pointer_mode pointer_mode)#
Set rocblas_pointer_mode.
-
rocblas_status rocblas_get_pointer_mode(rocblas_handle handle, rocblas_pointer_mode *pointer_mode)#
Get rocblas_pointer_mode.
-
rocblas_status rocblas_set_atomics_mode(rocblas_handle handle, rocblas_atomics_mode atomics_mode)#
Set rocblas_atomics_mode.
-
rocblas_status rocblas_get_atomics_mode(rocblas_handle handle, rocblas_atomics_mode *atomics_mode)#
Get rocblas_atomics_mode.
-
rocblas_status rocblas_query_int8_layout_flag(rocblas_handle handle, rocblas_gemm_flags *flag)#
Query the preferable supported int8 input layout for gemm.
Indicates the supported int8 input layout for gemm according to the device. If the device supports packed-int8x4 (1) only, output flag is rocblas_gemm_flags_pack_int8x4 and users must bitwise-or your flag with rocblas_gemm_flags_pack_int8x4. If output flag is rocblas_gemm_flags_none (0), then unpacked int8 is preferable and suggested.
- Parameters:
handle – [in] [rocblas_handle] the handle of device
flag – [out] pointer to rocblas_gemm_flags
-
rocblas_pointer_mode rocblas_pointer_to_mode(void *ptr)#
Indicates whether the pointer is on the host or device.
-
rocblas_status rocblas_set_vector(rocblas_int n, rocblas_int elem_size, const void *x, rocblas_int incx, void *y, rocblas_int incy)#
Copy vector from host to device.
- Parameters:
n – [in] [rocblas_int] number of elements in the vector
elem_size – [in] [rocblas_int] number of bytes per element in the matrix
x – [in] pointer to vector on the host
incx – [in] [rocblas_int] specifies the increment for the elements of the vector
y – [out] pointer to vector on the device
incy – [in] [rocblas_int] specifies the increment for the elements of the vector
-
rocblas_status rocblas_get_vector(rocblas_int n, rocblas_int elem_size, const void *x, rocblas_int incx, void *y, rocblas_int incy)#
Copy vector from device to host.
- Parameters:
n – [in] [rocblas_int] number of elements in the vector
elem_size – [in] [rocblas_int] number of bytes per element in the matrix
x – [in] pointer to vector on the device
incx – [in] [rocblas_int] specifies the increment for the elements of the vector
y – [out] pointer to vector on the host
incy – [in] [rocblas_int] specifies the increment for the elements of the vector
-
rocblas_status rocblas_set_matrix(rocblas_int rows, rocblas_int cols, rocblas_int elem_size, const void *a, rocblas_int lda, void *b, rocblas_int ldb)#
Copy matrix from host to device.
- Parameters:
rows – [in] [rocblas_int] number of rows in matrices
cols – [in] [rocblas_int] number of columns in matrices
elem_size – [in] [rocblas_int] number of bytes per element in the matrix
a – [in] pointer to matrix on the host
lda – [in] [rocblas_int] specifies the leading dimension of A, lda >= rows
b – [out] pointer to matrix on the GPU
ldb – [in] [rocblas_int] specifies the leading dimension of B, ldb >= rows
-
rocblas_status rocblas_get_matrix(rocblas_int rows, rocblas_int cols, rocblas_int elem_size, const void *a, rocblas_int lda, void *b, rocblas_int ldb)#
Copy matrix from device to host.
- Parameters:
rows – [in] [rocblas_int] number of rows in matrices
cols – [in] [rocblas_int] number of columns in matrices
elem_size – [in] [rocblas_int] number of bytes per element in the matrix
a – [in] pointer to matrix on the GPU
lda – [in] [rocblas_int] specifies the leading dimension of A, lda >= rows
b – [out] pointer to matrix on the host
ldb – [in] [rocblas_int] specifies the leading dimension of B, ldb >= rows
-
rocblas_status rocblas_set_vector_async(rocblas_int n, rocblas_int elem_size, const void *x, rocblas_int incx, void *y, rocblas_int incy, hipStream_t stream)#
Asynchronously copy vector from host to device.
rocblas_set_vector_async copies a vector from pinned host memory to device memory asynchronously. Memory on the host must be allocated with hipHostMalloc or the transfer will be synchronous.
- Parameters:
n – [in] [rocblas_int] number of elements in the vector
elem_size – [in] [rocblas_int] number of bytes per element in the matrix
x – [in] pointer to vector on the host
incx – [in] [rocblas_int] specifies the increment for the elements of the vector
y – [out] pointer to vector on the device
incy – [in] [rocblas_int] specifies the increment for the elements of the vector
stream – [in] specifies the stream into which this transfer request is queued
-
rocblas_status rocblas_set_matrix_async(rocblas_int rows, rocblas_int cols, rocblas_int elem_size, const void *a, rocblas_int lda, void *b, rocblas_int ldb, hipStream_t stream)#
Asynchronously copy matrix from host to device.
rocblas_set_matrix_async copies a matrix from pinned host memory to device memory asynchronously. Memory on the host must be allocated with hipHostMalloc or the transfer will be synchronous.
- Parameters:
rows – [in] [rocblas_int] number of rows in matrices
cols – [in] [rocblas_int] number of columns in matrices
elem_size – [in] [rocblas_int] number of bytes per element in the matrix
a – [in] pointer to matrix on the host
lda – [in] [rocblas_int] specifies the leading dimension of A, lda >= rows
b – [out] pointer to matrix on the GPU
ldb – [in] [rocblas_int] specifies the leading dimension of B, ldb >= rows
stream – [in] specifies the stream into which this transfer request is queued
-
rocblas_status rocblas_get_matrix_async(rocblas_int rows, rocblas_int cols, rocblas_int elem_size, const void *a, rocblas_int lda, void *b, rocblas_int ldb, hipStream_t stream)#
asynchronously copy matrix from device to host
rocblas_get_matrix_async copies a matrix from device memory to pinned host memory asynchronously. Memory on the host must be allocated with hipHostMalloc or the transfer will be synchronous.
- Parameters:
rows – [in] [rocblas_int] number of rows in matrices
cols – [in] [rocblas_int] number of columns in matrices
elem_size – [in] [rocblas_int] number of bytes per element in the matrix
a – [in] pointer to matrix on the GPU
lda – [in] [rocblas_int] specifies the leading dimension of A, lda >= rows
b – [out] pointer to matrix on the host
ldb – [in] [rocblas_int] specifies the leading dimension of B, ldb >= rows
stream – [in] specifies the stream into which this transfer request is queued
-
void rocblas_initialize(void)#
Initialize rocBLAS on the current HIP device, to avoid costly startup time at the first call on that device.
Calling
rocblas_initialize()allows upfront initialization including device specific kernel setup. Otherwise this function is automatically called on the first function call that requires these initializations (mainly GEMM).
-
const char *rocblas_status_to_string(rocblas_status status)#
BLAS Auxiliary API
rocblas_status_to_string
Returns string representing rocblas_status value
- Parameters:
status – [in] [rocblas_status] rocBLAS status to convert to string
Device Memory Allocation Functions#
-
rocblas_status rocblas_start_device_memory_size_query(rocblas_handle handle)#
Indicates that subsequent rocBLAS kernel calls should collect the optimal device memory size in bytes for their given kernel arguments and keep track of the maximum. Each kernel call can reuse temporary device memory on the same stream so the maximum is collected. Returns rocblas_status_size_query_mismatch if another size query is already in progress; returns rocblas_status_success otherwise
- Parameters:
handle – [in] rocblas handle
-
rocblas_status rocblas_stop_device_memory_size_query(rocblas_handle handle, size_t *size)#
Stops collecting optimal device memory size information. Returns rocblas_status_size_query_mismatch if a collection is not underway; rocblas_status_invalid_handle if handle is nullptr; rocblas_status_invalid_pointer if size is nullptr; rocblas_status_success otherwise
- Parameters:
handle – [in] rocblas handle
size – [out] maximum of the optimal sizes collected
-
rocblas_status rocblas_get_device_memory_size(rocblas_handle handle, size_t *size)#
Gets the current device memory size for the handle. Returns rocblas_status_invalid_handle if handle is nullptr; rocblas_status_invalid_pointer if size is nullptr; rocblas_status_success otherwise
- Parameters:
handle – [in] rocblas handle
size – [out] current device memory size for the handle
-
rocblas_status rocblas_set_device_memory_size(rocblas_handle handle, size_t size)#
Changes the size of allocated device memory at runtime.
Any previously allocated device memory managed by the handle is freed.
If size > 0 sets the device memory size to the specified size (in bytes). If size == 0, frees the memory allocated so far, and lets rocBLAS manage device memory in the future, expanding it when necessary. Returns rocblas_status_invalid_handle if handle is nullptr; rocblas_status_invalid_pointer if size is nullptr; rocblas_status_success otherwise
- Parameters:
handle – [in] rocblas handle
size – [in] size of allocated device memory
-
rocblas_status rocblas_set_workspace(rocblas_handle handle, void *addr, size_t size)#
Sets the device workspace for the handle to use.
Any previously allocated device memory managed by the handle is freed.
Returns rocblas_status_invalid_handle if handle is nullptr; rocblas_status_success otherwise
- Parameters:
handle – [in] rocblas handle
addr – [in] address of workspace memory
size – [in] size of workspace memory
-
bool rocblas_is_managing_device_memory(rocblas_handle handle)#
Returns true when device memory in handle is managed by rocBLAS
- Parameters:
handle – [in] rocblas handle
-
bool rocblas_is_user_managing_device_memory(rocblas_handle handle)#
Returns true when device memory in handle is managed by the user
- Parameters:
handle – [in] rocblas handle
For more detailed informationt, refer to sections rocBLAS Beta Features and Device Memory Allocation.
Build Information Functions#
-
rocblas_status rocblas_get_version_string_size(size_t *len)#
Queries the minimum buffer size for a successful call to rocblas_get_version_string.
- Parameters:
len – [out] pointer to size_t for storing the length
-
rocblas_status rocblas_get_version_string(char *buf, size_t len)#
Loads char* buf with the rocblas library version. size_t len is the maximum length of char* buf.
- Parameters:
buf – [inout] pointer to buffer for version string
len – [in] length of buf
rocBLAS Level-1 functions#
rocblas_iXamax + batched, strided_batched#
-
rocblas_status rocblas_isamax(rocblas_handle handle, rocblas_int n, const float *x, rocblas_int incx, rocblas_int *result)#
-
rocblas_status rocblas_idamax(rocblas_handle handle, rocblas_int n, const double *x, rocblas_int incx, rocblas_int *result)#
-
rocblas_status rocblas_icamax(rocblas_handle handle, rocblas_int n, const rocblas_float_complex *x, rocblas_int incx, rocblas_int *result)#
-
rocblas_status rocblas_izamax(rocblas_handle handle, rocblas_int n, const rocblas_double_complex *x, rocblas_int incx, rocblas_int *result)#
BLAS Level 1 API
amax finds the first index of the element of maximum magnitude of a vector x.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] the number of elements in x.
x – [in] device pointer storing vector x.
incx – [in] [rocblas_int] specifies the increment for the elements of y.
result – [inout] device pointer or host pointer to store the amax index. return is 0.0 if n, incx<=0.
-
rocblas_status rocblas_isamax_batched(rocblas_handle handle, rocblas_int n, const float *const x[], rocblas_int incx, rocblas_int batch_count, rocblas_int *result)#
-
rocblas_status rocblas_idamax_batched(rocblas_handle handle, rocblas_int n, const double *const x[], rocblas_int incx, rocblas_int batch_count, rocblas_int *result)#
-
rocblas_status rocblas_icamax_batched(rocblas_handle handle, rocblas_int n, const rocblas_float_complex *const x[], rocblas_int incx, rocblas_int batch_count, rocblas_int *result)#
-
rocblas_status rocblas_izamax_batched(rocblas_handle handle, rocblas_int n, const rocblas_double_complex *const x[], rocblas_int incx, rocblas_int batch_count, rocblas_int *result)#
BLAS Level 1 API
amax_batched finds the first index of the element of maximum magnitude of each vector x_i in a batch, for i = 1, …, batch_count.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] number of elements in each vector x_i.
x – [in] device array of device pointers storing each vector x_i.
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i. incx must be > 0.
batch_count – [in] [rocblas_int] number of instances in the batch. Must be > 0.
result – [out] device or host array of pointers of batch_count size for results. return is 0 if n, incx<=0.
-
rocblas_status rocblas_isamax_strided_batched(rocblas_handle handle, rocblas_int n, const float *x, rocblas_int incx, rocblas_stride stridex, rocblas_int batch_count, rocblas_int *result)#
-
rocblas_status rocblas_idamax_strided_batched(rocblas_handle handle, rocblas_int n, const double *x, rocblas_int incx, rocblas_stride stridex, rocblas_int batch_count, rocblas_int *result)#
-
rocblas_status rocblas_icamax_strided_batched(rocblas_handle handle, rocblas_int n, const rocblas_float_complex *x, rocblas_int incx, rocblas_stride stridex, rocblas_int batch_count, rocblas_int *result)#
-
rocblas_status rocblas_izamax_strided_batched(rocblas_handle handle, rocblas_int n, const rocblas_double_complex *x, rocblas_int incx, rocblas_stride stridex, rocblas_int batch_count, rocblas_int *result)#
BLAS Level 1 API
amax_strided_batched finds the first index of the element of maximum magnitude of each vector x_i in a batch, for i = 1, …, batch_count.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] number of elements in each vector x_i.
x – [in] device pointer to the first vector x_1.
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i. incx must be > 0.
stridex – [in] [rocblas_stride] specifies the pointer increment between one x_i and the next x_(i + 1).
batch_count – [in] [rocblas_int] number of instances in the batch.
result – [out] device or host pointer for storing contiguous batch_count results. return is 0 if n <= 0, incx<=0.
rocblas_iXamin + batched, strided_batched#
-
rocblas_status rocblas_isamin(rocblas_handle handle, rocblas_int n, const float *x, rocblas_int incx, rocblas_int *result)#
-
rocblas_status rocblas_idamin(rocblas_handle handle, rocblas_int n, const double *x, rocblas_int incx, rocblas_int *result)#
-
rocblas_status rocblas_icamin(rocblas_handle handle, rocblas_int n, const rocblas_float_complex *x, rocblas_int incx, rocblas_int *result)#
-
rocblas_status rocblas_izamin(rocblas_handle handle, rocblas_int n, const rocblas_double_complex *x, rocblas_int incx, rocblas_int *result)#
BLAS Level 1 API
amin finds the first index of the element of minimum magnitude of a vector x.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] the number of elements in x.
x – [in] device pointer storing vector x.
incx – [in] [rocblas_int] specifies the increment for the elements of y.
result – [inout] device pointer or host pointer to store the amin index. return is 0.0 if n, incx<=0.
-
rocblas_status rocblas_isamin_batched(rocblas_handle handle, rocblas_int n, const float *const x[], rocblas_int incx, rocblas_int batch_count, rocblas_int *result)#
-
rocblas_status rocblas_idamin_batched(rocblas_handle handle, rocblas_int n, const double *const x[], rocblas_int incx, rocblas_int batch_count, rocblas_int *result)#
-
rocblas_status rocblas_icamin_batched(rocblas_handle handle, rocblas_int n, const rocblas_float_complex *const x[], rocblas_int incx, rocblas_int batch_count, rocblas_int *result)#
-
rocblas_status rocblas_izamin_batched(rocblas_handle handle, rocblas_int n, const rocblas_double_complex *const x[], rocblas_int incx, rocblas_int batch_count, rocblas_int *result)#
BLAS Level 1 API
amin_batched finds the first index of the element of minimum magnitude of each vector x_i in a batch, for i = 1, …, batch_count.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] number of elements in each vector x_i.
x – [in] device array of device pointers storing each vector x_i.
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i. incx must be > 0.
batch_count – [in] [rocblas_int] number of instances in the batch. Must be > 0.
result – [out] device or host pointers to array of batch_count size for results. return is 0 if n, incx<=0.
-
rocblas_status rocblas_isamin_strided_batched(rocblas_handle handle, rocblas_int n, const float *x, rocblas_int incx, rocblas_stride stridex, rocblas_int batch_count, rocblas_int *result)#
-
rocblas_status rocblas_idamin_strided_batched(rocblas_handle handle, rocblas_int n, const double *x, rocblas_int incx, rocblas_stride stridex, rocblas_int batch_count, rocblas_int *result)#
-
rocblas_status rocblas_icamin_strided_batched(rocblas_handle handle, rocblas_int n, const rocblas_float_complex *x, rocblas_int incx, rocblas_stride stridex, rocblas_int batch_count, rocblas_int *result)#
-
rocblas_status rocblas_izamin_strided_batched(rocblas_handle handle, rocblas_int n, const rocblas_double_complex *x, rocblas_int incx, rocblas_stride stridex, rocblas_int batch_count, rocblas_int *result)#
BLAS Level 1 API
amin_strided_batched finds the first index of the element of minimum magnitude of each vector x_i in a batch, for i = 1, …, batch_count.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] number of elements in each vector x_i.
x – [in] device pointer to the first vector x_1.
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i. incx must be > 0.
stridex – [in] [rocblas_stride] specifies the pointer increment between one x_i and the next x_(i + 1).
batch_count – [in] [rocblas_int] number of instances in the batch.
result – [out] device or host pointer to array for storing contiguous batch_count results. return is 0 if n <= 0, incx<=0.
rocblas_Xasum + batched, strided_batched#
-
rocblas_status rocblas_sasum(rocblas_handle handle, rocblas_int n, const float *x, rocblas_int incx, float *result)#
-
rocblas_status rocblas_dasum(rocblas_handle handle, rocblas_int n, const double *x, rocblas_int incx, double *result)#
-
rocblas_status rocblas_scasum(rocblas_handle handle, rocblas_int n, const rocblas_float_complex *x, rocblas_int incx, float *result)#
-
rocblas_status rocblas_dzasum(rocblas_handle handle, rocblas_int n, const rocblas_double_complex *x, rocblas_int incx, double *result)#
BLAS Level 1 API
asum computes the sum of the magnitudes of elements of a real vector x, or the sum of magnitudes of the real and imaginary parts of elements if x is a complex vector.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] the number of elements in x and y.
x – [in] device pointer storing vector x.
incx – [in] [rocblas_int] specifies the increment for the elements of x. incx must be > 0.
result – [inout] device pointer or host pointer to store the asum product. return is 0.0 if n <= 0.
-
rocblas_status rocblas_sasum_batched(rocblas_handle handle, rocblas_int n, const float *const x[], rocblas_int incx, rocblas_int batch_count, float *results)#
-
rocblas_status rocblas_dasum_batched(rocblas_handle handle, rocblas_int n, const double *const x[], rocblas_int incx, rocblas_int batch_count, double *results)#
-
rocblas_status rocblas_scasum_batched(rocblas_handle handle, rocblas_int n, const rocblas_float_complex *const x[], rocblas_int incx, rocblas_int batch_count, float *results)#
-
rocblas_status rocblas_dzasum_batched(rocblas_handle handle, rocblas_int n, const rocblas_double_complex *const x[], rocblas_int incx, rocblas_int batch_count, double *results)#
BLAS Level 1 API
asum_batched computes the sum of the magnitudes of the elements in a batch of real vectors x_i, or the sum of magnitudes of the real and imaginary parts of elements if x_i is a complex vector, for i = 1, …, batch_count.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] number of elements in each vector x_i.
x – [in] device array of device pointers storing each vector x_i.
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i. incx must be > 0.
results – [out] device array or host array of batch_count size for results. return is 0.0 if n, incx<=0.
batch_count – [in] [rocblas_int] number of instances in the batch.
-
rocblas_status rocblas_sasum_strided_batched(rocblas_handle handle, rocblas_int n, const float *x, rocblas_int incx, rocblas_stride stridex, rocblas_int batch_count, float *results)#
-
rocblas_status rocblas_dasum_strided_batched(rocblas_handle handle, rocblas_int n, const double *x, rocblas_int incx, rocblas_stride stridex, rocblas_int batch_count, double *results)#
-
rocblas_status rocblas_scasum_strided_batched(rocblas_handle handle, rocblas_int n, const rocblas_float_complex *x, rocblas_int incx, rocblas_stride stridex, rocblas_int batch_count, float *results)#
-
rocblas_status rocblas_dzasum_strided_batched(rocblas_handle handle, rocblas_int n, const rocblas_double_complex *x, rocblas_int incx, rocblas_stride stridex, rocblas_int batch_count, double *results)#
BLAS Level 1 API
asum_strided_batched computes the sum of the magnitudes of elements of a real vectors x_i, or the sum of magnitudes of the real and imaginary parts of elements if x_i is a complex vector, for i = 1, …, batch_count.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] number of elements in each vector x_i.
x – [in] device pointer to the first vector x_1.
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i. incx must be > 0.
stridex – [in] [rocblas_stride] stride from the start of one vector (x_i) and the next one (x_i+1). There are no restrictions placed on stride_x. However, ensure that stride_x is of appropriate size. For a typical case this means stride_x >= n * incx.
results – [out] device pointer or host pointer to array for storing contiguous batch_count results. return is 0.0 if n, incx<=0.
batch_count – [in] [rocblas_int] number of instances in the batch.
rocblas_Xaxpy + batched, strided_batched#
-
rocblas_status rocblas_saxpy(rocblas_handle handle, rocblas_int n, const float *alpha, const float *x, rocblas_int incx, float *y, rocblas_int incy)#
-
rocblas_status rocblas_daxpy(rocblas_handle handle, rocblas_int n, const double *alpha, const double *x, rocblas_int incx, double *y, rocblas_int incy)#
-
rocblas_status rocblas_haxpy(rocblas_handle handle, rocblas_int n, const rocblas_half *alpha, const rocblas_half *x, rocblas_int incx, rocblas_half *y, rocblas_int incy)#
-
rocblas_status rocblas_caxpy(rocblas_handle handle, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *x, rocblas_int incx, rocblas_float_complex *y, rocblas_int incy)#
-
rocblas_status rocblas_zaxpy(rocblas_handle handle, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *x, rocblas_int incx, rocblas_double_complex *y, rocblas_int incy)#
BLAS Level 1 API
axpy computes constant alpha multiplied by vector x, plus vector y:
y := alpha * x + y
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] the number of elements in x and y.
alpha – [in] device pointer or host pointer to specify the scalar alpha.
x – [in] device pointer storing vector x.
incx – [in] [rocblas_int] specifies the increment for the elements of x.
y – [out] device pointer storing vector y.
incy – [inout] [rocblas_int] specifies the increment for the elements of y.
-
rocblas_status rocblas_saxpy_batched(rocblas_handle handle, rocblas_int n, const float *alpha, const float *const x[], rocblas_int incx, float *const y[], rocblas_int incy, rocblas_int batch_count)#
-
rocblas_status rocblas_daxpy_batched(rocblas_handle handle, rocblas_int n, const double *alpha, const double *const x[], rocblas_int incx, double *const y[], rocblas_int incy, rocblas_int batch_count)#
-
rocblas_status rocblas_haxpy_batched(rocblas_handle handle, rocblas_int n, const rocblas_half *alpha, const rocblas_half *const x[], rocblas_int incx, rocblas_half *const y[], rocblas_int incy, rocblas_int batch_count)#
-
rocblas_status rocblas_caxpy_batched(rocblas_handle handle, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *const x[], rocblas_int incx, rocblas_float_complex *const y[], rocblas_int incy, rocblas_int batch_count)#
-
rocblas_status rocblas_zaxpy_batched(rocblas_handle handle, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *const x[], rocblas_int incx, rocblas_double_complex *const y[], rocblas_int incy, rocblas_int batch_count)#
BLAS Level 1 API
axpy_batched compute y := alpha * x + y over a set of batched vectors.
- Parameters:
handle – [in] rocblas_handle handle to the rocblas library context queue.
n – [in] rocblas_int
alpha – [in] specifies the scalar alpha.
x – [in] pointer storing vector x on the GPU.
incx – [in] rocblas_int specifies the increment for the elements of x.
y – [out] pointer storing vector y on the GPU.
incy – [inout] rocblas_int specifies the increment for the elements of y.
batch_count – [in] rocblas_int number of instances in the batch.
-
rocblas_status rocblas_saxpy_strided_batched(rocblas_handle handle, rocblas_int n, const float *alpha, const float *x, rocblas_int incx, rocblas_stride stridex, float *y, rocblas_int incy, rocblas_stride stridey, rocblas_int batch_count)#
-
rocblas_status rocblas_daxpy_strided_batched(rocblas_handle handle, rocblas_int n, const double *alpha, const double *x, rocblas_int incx, rocblas_stride stridex, double *y, rocblas_int incy, rocblas_stride stridey, rocblas_int batch_count)#
-
rocblas_status rocblas_haxpy_strided_batched(rocblas_handle handle, rocblas_int n, const rocblas_half *alpha, const rocblas_half *x, rocblas_int incx, rocblas_stride stridex, rocblas_half *y, rocblas_int incy, rocblas_stride stridey, rocblas_int batch_count)#
-
rocblas_status rocblas_caxpy_strided_batched(rocblas_handle handle, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *x, rocblas_int incx, rocblas_stride stridex, rocblas_float_complex *y, rocblas_int incy, rocblas_stride stridey, rocblas_int batch_count)#
-
rocblas_status rocblas_zaxpy_strided_batched(rocblas_handle handle, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *x, rocblas_int incx, rocblas_stride stridex, rocblas_double_complex *y, rocblas_int incy, rocblas_stride stridey, rocblas_int batch_count)#
BLAS Level 1 API
axpy_strided_batched compute y := alpha * x + y over a set of strided batched vectors.
- Parameters:
handle – [in] rocblas_handle handle to the rocblas library context queue.
n – [in] rocblas_int.
alpha – [in] specifies the scalar alpha.
x – [in] pointer storing vector x on the GPU.
incx – [in] rocblas_int specifies the increment for the elements of x.
stridex – [in] rocblas_stride specifies the increment between vectors of x.
y – [out] pointer storing vector y on the GPU.
incy – [inout] rocblas_int specifies the increment for the elements of y.
stridey – [in] rocblas_stride specifies the increment between vectors of y.
batch_count – [in] rocblas_int number of instances in the batch.
rocblas_Xcopy + batched, strided_batched#
-
rocblas_status rocblas_scopy(rocblas_handle handle, rocblas_int n, const float *x, rocblas_int incx, float *y, rocblas_int incy)#
-
rocblas_status rocblas_dcopy(rocblas_handle handle, rocblas_int n, const double *x, rocblas_int incx, double *y, rocblas_int incy)#
-
rocblas_status rocblas_ccopy(rocblas_handle handle, rocblas_int n, const rocblas_float_complex *x, rocblas_int incx, rocblas_float_complex *y, rocblas_int incy)#
-
rocblas_status rocblas_zcopy(rocblas_handle handle, rocblas_int n, const rocblas_double_complex *x, rocblas_int incx, rocblas_double_complex *y, rocblas_int incy)#
BLAS Level 1 API
copy copies each element x[i] into y[i], for i = 1 , … , n:
y := x
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] the number of elements in x to be copied to y.
x – [in] device pointer storing vector x.
incx – [in] [rocblas_int] specifies the increment for the elements of x.
y – [out] device pointer storing vector y.
incy – [in] [rocblas_int] specifies the increment for the elements of y.
-
rocblas_status rocblas_scopy_batched(rocblas_handle handle, rocblas_int n, const float *const x[], rocblas_int incx, float *const y[], rocblas_int incy, rocblas_int batch_count)#
-
rocblas_status rocblas_dcopy_batched(rocblas_handle handle, rocblas_int n, const double *const x[], rocblas_int incx, double *const y[], rocblas_int incy, rocblas_int batch_count)#
-
rocblas_status rocblas_ccopy_batched(rocblas_handle handle, rocblas_int n, const rocblas_float_complex *const x[], rocblas_int incx, rocblas_float_complex *const y[], rocblas_int incy, rocblas_int batch_count)#
-
rocblas_status rocblas_zcopy_batched(rocblas_handle handle, rocblas_int n, const rocblas_double_complex *const x[], rocblas_int incx, rocblas_double_complex *const y[], rocblas_int incy, rocblas_int batch_count)#
BLAS Level 1 API
copy_batched copies each element x_i[j] into y_i[j], for j = 1 , … , n; i = 1 , … , batch_count:
y_i := x_i, where (x_i, y_i) is the i-th instance of the batch. x_i and y_i are vectors.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] the number of elements in each x_i to be copied to y_i.
x – [in] device array of device pointers storing each vector x_i.
incx – [in] [rocblas_int] specifies the increment for the elements of each vector x_i.
y – [out] device array of device pointers storing each vector y_i.
incy – [in] [rocblas_int] specifies the increment for the elements of each vector y_i.
batch_count – [in] [rocblas_int] number of instances in the batch.
-
rocblas_status rocblas_scopy_strided_batched(rocblas_handle handle, rocblas_int n, const float *x, rocblas_int incx, rocblas_stride stridex, float *y, rocblas_int incy, rocblas_stride stridey, rocblas_int batch_count)#
-
rocblas_status rocblas_dcopy_strided_batched(rocblas_handle handle, rocblas_int n, const double *x, rocblas_int incx, rocblas_stride stridex, double *y, rocblas_int incy, rocblas_stride stridey, rocblas_int batch_count)#
-
rocblas_status rocblas_ccopy_strided_batched(rocblas_handle handle, rocblas_int n, const rocblas_float_complex *x, rocblas_int incx, rocblas_stride stridex, rocblas_float_complex *y, rocblas_int incy, rocblas_stride stridey, rocblas_int batch_count)#
-
rocblas_status rocblas_zcopy_strided_batched(rocblas_handle handle, rocblas_int n, const rocblas_double_complex *x, rocblas_int incx, rocblas_stride stridex, rocblas_double_complex *y, rocblas_int incy, rocblas_stride stridey, rocblas_int batch_count)#
BLAS Level 1 API
copy_strided_batched copies each element x_i[j] into y_i[j], for j = 1 , … , n; i = 1 , … , batch_count:
y_i := x_i, where (x_i, y_i) is the i-th instance of the batch. x_i and y_i are vectors.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] the number of elements in each x_i to be copied to y_i.
x – [in] device pointer to the first vector (x_1) in the batch.
incx – [in] [rocblas_int] specifies the increments for the elements of vectors x_i.
stridex – [in] [rocblas_stride] stride from the start of one vector (x_i) and the next one (x_i+1). There are no restrictions placed on stride_x. However, the user should take care to ensure that stride_x is of appropriate size. For a typical case, this means stride_x >= n * incx.
y – [out] device pointer to the first vector (y_1) in the batch.
incy – [in] [rocblas_int] specifies the increment for the elements of vectors y_i.
stridey – [in] [rocblas_stride] stride from the start of one vector (y_i) and the next one (y_i+1). There are no restrictions placed on stride_y, However, ensure that stride_y is of appropriate size, for a typical case this means stride_y >= n * incy. stridey should be non zero.
batch_count – [in] [rocblas_int] number of instances in the batch.
rocblas_Xdot + batched, strided_batched#
-
rocblas_status rocblas_sdot(rocblas_handle handle, rocblas_int n, const float *x, rocblas_int incx, const float *y, rocblas_int incy, float *result)#
-
rocblas_status rocblas_ddot(rocblas_handle handle, rocblas_int n, const double *x, rocblas_int incx, const double *y, rocblas_int incy, double *result)#
-
rocblas_status rocblas_hdot(rocblas_handle handle, rocblas_int n, const rocblas_half *x, rocblas_int incx, const rocblas_half *y, rocblas_int incy, rocblas_half *result)#
-
rocblas_status rocblas_bfdot(rocblas_handle handle, rocblas_int n, const rocblas_bfloat16 *x, rocblas_int incx, const rocblas_bfloat16 *y, rocblas_int incy, rocblas_bfloat16 *result)#
-
rocblas_status rocblas_cdotu(rocblas_handle handle, rocblas_int n, const rocblas_float_complex *x, rocblas_int incx, const rocblas_float_complex *y, rocblas_int incy, rocblas_float_complex *result)#
-
rocblas_status rocblas_cdotc(rocblas_handle handle, rocblas_int n, const rocblas_float_complex *x, rocblas_int incx, const rocblas_float_complex *y, rocblas_int incy, rocblas_float_complex *result)#
-
rocblas_status rocblas_zdotu(rocblas_handle handle, rocblas_int n, const rocblas_double_complex *x, rocblas_int incx, const rocblas_double_complex *y, rocblas_int incy, rocblas_double_complex *result)#
-
rocblas_status rocblas_zdotc(rocblas_handle handle, rocblas_int n, const rocblas_double_complex *x, rocblas_int incx, const rocblas_double_complex *y, rocblas_int incy, rocblas_double_complex *result)#
BLAS Level 1 API
dot(u) performs the dot product of vectors x and y:
result = x * y;
dotc performs the dot product of the conjugate of complex vector x and complex vector y.
result = conjugate (x) * y;
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] the number of elements in x and y.
x – [in] device pointer storing vector x.
incx – [in] [rocblas_int] specifies the increment for the elements of y.
y – [in] device pointer storing vector y.
incy – [in] [rocblas_int] specifies the increment for the elements of y.
result – [inout] device pointer or host pointer to store the dot product. return is 0.0 if n <= 0.
-
rocblas_status rocblas_sdot_batched(rocblas_handle handle, rocblas_int n, const float *const x[], rocblas_int incx, const float *const y[], rocblas_int incy, rocblas_int batch_count, float *result)#
-
rocblas_status rocblas_ddot_batched(rocblas_handle handle, rocblas_int n, const double *const x[], rocblas_int incx, const double *const y[], rocblas_int incy, rocblas_int batch_count, double *result)#
-
rocblas_status rocblas_hdot_batched(rocblas_handle handle, rocblas_int n, const rocblas_half *const x[], rocblas_int incx, const rocblas_half *const y[], rocblas_int incy, rocblas_int batch_count, rocblas_half *result)#
-
rocblas_status rocblas_bfdot_batched(rocblas_handle handle, rocblas_int n, const rocblas_bfloat16 *const x[], rocblas_int incx, const rocblas_bfloat16 *const y[], rocblas_int incy, rocblas_int batch_count, rocblas_bfloat16 *result)#
-
rocblas_status rocblas_cdotu_batched(rocblas_handle handle, rocblas_int n, const rocblas_float_complex *const x[], rocblas_int incx, const rocblas_float_complex *const y[], rocblas_int incy, rocblas_int batch_count, rocblas_float_complex *result)#
-
rocblas_status rocblas_cdotc_batched(rocblas_handle handle, rocblas_int n, const rocblas_float_complex *const x[], rocblas_int incx, const rocblas_float_complex *const y[], rocblas_int incy, rocblas_int batch_count, rocblas_float_complex *result)#
-
rocblas_status rocblas_zdotu_batched(rocblas_handle handle, rocblas_int n, const rocblas_double_complex *const x[], rocblas_int incx, const rocblas_double_complex *const y[], rocblas_int incy, rocblas_int batch_count, rocblas_double_complex *result)#
-
rocblas_status rocblas_zdotc_batched(rocblas_handle handle, rocblas_int n, const rocblas_double_complex *const x[], rocblas_int incx, const rocblas_double_complex *const y[], rocblas_int incy, rocblas_int batch_count, rocblas_double_complex *result)#
BLAS Level 1 API
dot_batched(u) performs a batch of dot products of vectors x and y:
result_i = x_i * y_i;
dotc_batched performs a batch of dot products of the conjugate of complex vector x and complex vector y
result_i = conjugate (x_i) * y_i; where (x_i, y_i) is the i-th instance of the batch. x_i and y_i are vectors, for i = 1, ..., batch_count.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] the number of elements in each x_i and y_i.
x – [in] device array of device pointers storing each vector x_i.
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i.
y – [in] device array of device pointers storing each vector y_i.
incy – [in] [rocblas_int] specifies the increment for the elements of each y_i.
batch_count – [in] [rocblas_int] number of instances in the batch.
result – [inout] device array or host array of batch_count size to store the dot products of each batch. return 0.0 for each element if n <= 0.
-
rocblas_status rocblas_sdot_strided_batched(rocblas_handle handle, rocblas_int n, const float *x, rocblas_int incx, rocblas_stride stridex, const float *y, rocblas_int incy, rocblas_stride stridey, rocblas_int batch_count, float *result)#
-
rocblas_status rocblas_ddot_strided_batched(rocblas_handle handle, rocblas_int n, const double *x, rocblas_int incx, rocblas_stride stridex, const double *y, rocblas_int incy, rocblas_stride stridey, rocblas_int batch_count, double *result)#
-
rocblas_status rocblas_hdot_strided_batched(rocblas_handle handle, rocblas_int n, const rocblas_half *x, rocblas_int incx, rocblas_stride stridex, const rocblas_half *y, rocblas_int incy, rocblas_stride stridey, rocblas_int batch_count, rocblas_half *result)#
-
rocblas_status rocblas_bfdot_strided_batched(rocblas_handle handle, rocblas_int n, const rocblas_bfloat16 *x, rocblas_int incx, rocblas_stride stridex, const rocblas_bfloat16 *y, rocblas_int incy, rocblas_stride stridey, rocblas_int batch_count, rocblas_bfloat16 *result)#
-
rocblas_status rocblas_cdotu_strided_batched(rocblas_handle handle, rocblas_int n, const rocblas_float_complex *x, rocblas_int incx, rocblas_stride stridex, const rocblas_float_complex *y, rocblas_int incy, rocblas_stride stridey, rocblas_int batch_count, rocblas_float_complex *result)#
-
rocblas_status rocblas_cdotc_strided_batched(rocblas_handle handle, rocblas_int n, const rocblas_float_complex *x, rocblas_int incx, rocblas_stride stridex, const rocblas_float_complex *y, rocblas_int incy, rocblas_stride stridey, rocblas_int batch_count, rocblas_float_complex *result)#
-
rocblas_status rocblas_zdotu_strided_batched(rocblas_handle handle, rocblas_int n, const rocblas_double_complex *x, rocblas_int incx, rocblas_stride stridex, const rocblas_double_complex *y, rocblas_int incy, rocblas_stride stridey, rocblas_int batch_count, rocblas_double_complex *result)#
-
rocblas_status rocblas_zdotc_strided_batched(rocblas_handle handle, rocblas_int n, const rocblas_double_complex *x, rocblas_int incx, rocblas_stride stridex, const rocblas_double_complex *y, rocblas_int incy, rocblas_stride stridey, rocblas_int batch_count, rocblas_double_complex *result)#
BLAS Level 1 API
dot_strided_batched(u) performs a batch of dot products of vectors x and y:
result_i = x_i * y_i;
dotc_strided_batched performs a batch of dot products of the conjugate of complex vector x and complex vector y
result_i = conjugate (x_i) * y_i; where (x_i, y_i) is the i-th instance of the batch. x_i and y_i are vectors, for i = 1, ..., batch_count.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] the number of elements in each x_i and y_i.
x – [in] device pointer to the first vector (x_1) in the batch.
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i.
stridex – [in] [rocblas_stride] stride from the start of one vector (x_i) and the next one (x_i+1).
y – [in] device pointer to the first vector (y_1) in the batch.
incy – [in] [rocblas_int] specifies the increment for the elements of each y_i.
stridey – [in] [rocblas_stride] stride from the start of one vector (y_i) and the next one (y_i+1).
batch_count – [in] [rocblas_int] number of instances in the batch.
result – [inout] device array or host array of batch_count size to store the dot products of each batch. return 0.0 for each element if n <= 0.
rocblas_Xnrm2 + batched, strided_batched#
-
rocblas_status rocblas_snrm2(rocblas_handle handle, rocblas_int n, const float *x, rocblas_int incx, float *result)#
-
rocblas_status rocblas_dnrm2(rocblas_handle handle, rocblas_int n, const double *x, rocblas_int incx, double *result)#
-
rocblas_status rocblas_scnrm2(rocblas_handle handle, rocblas_int n, const rocblas_float_complex *x, rocblas_int incx, float *result)#
-
rocblas_status rocblas_dznrm2(rocblas_handle handle, rocblas_int n, const rocblas_double_complex *x, rocblas_int incx, double *result)#
BLAS Level 1 API
nrm2 computes the euclidean norm of a real or complex vector:
result := sqrt( x'*x ) for real vectors result := sqrt( x**H*x ) for complex vectors
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] the number of elements in x.
x – [in] device pointer storing vector x.
incx – [in] [rocblas_int] specifies the increment for the elements of y.
result – [inout] device pointer or host pointer to store the nrm2 product. return is 0.0 if n, incx<=0.
-
rocblas_status rocblas_snrm2_batched(rocblas_handle handle, rocblas_int n, const float *const x[], rocblas_int incx, rocblas_int batch_count, float *results)#
-
rocblas_status rocblas_dnrm2_batched(rocblas_handle handle, rocblas_int n, const double *const x[], rocblas_int incx, rocblas_int batch_count, double *results)#
-
rocblas_status rocblas_scnrm2_batched(rocblas_handle handle, rocblas_int n, const rocblas_float_complex *const x[], rocblas_int incx, rocblas_int batch_count, float *results)#
-
rocblas_status rocblas_dznrm2_batched(rocblas_handle handle, rocblas_int n, const rocblas_double_complex *const x[], rocblas_int incx, rocblas_int batch_count, double *results)#
BLAS Level 1 API
nrm2_batched computes the euclidean norm over a batch of real or complex vectors:
result := sqrt( x_i'*x_i ) for real vectors x, for i = 1, ..., batch_count result := sqrt( x_i**H*x_i ) for complex vectors x, for i = 1, ..., batch_count
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] number of elements in each x_i.
x – [in] device array of device pointers storing each vector x_i.
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i. incx must be > 0.
batch_count – [in] [rocblas_int] number of instances in the batch.
results – [out] device pointer or host pointer to array of batch_count size for nrm2 results. return is 0.0 for each element if n <= 0, incx<=0.
-
rocblas_status rocblas_snrm2_strided_batched(rocblas_handle handle, rocblas_int n, const float *x, rocblas_int incx, rocblas_stride stridex, rocblas_int batch_count, float *results)#
-
rocblas_status rocblas_dnrm2_strided_batched(rocblas_handle handle, rocblas_int n, const double *x, rocblas_int incx, rocblas_stride stridex, rocblas_int batch_count, double *results)#
-
rocblas_status rocblas_scnrm2_strided_batched(rocblas_handle handle, rocblas_int n, const rocblas_float_complex *x, rocblas_int incx, rocblas_stride stridex, rocblas_int batch_count, float *results)#
-
rocblas_status rocblas_dznrm2_strided_batched(rocblas_handle handle, rocblas_int n, const rocblas_double_complex *x, rocblas_int incx, rocblas_stride stridex, rocblas_int batch_count, double *results)#
BLAS Level 1 API
nrm2_strided_batched computes the euclidean norm over a batch of real or complex vectors:
result := sqrt( x_i'*x_i ) for real vectors x, for i = 1, ..., batch_count result := sqrt( x_i**H*x_i ) for complex vectors, for i = 1, ..., batch_count
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] number of elements in each x_i.
x – [in] device pointer to the first vector x_1.
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i. incx must be > 0.
stridex – [in] [rocblas_stride] stride from the start of one vector (x_i) and the next one (x_i+1). There are no restrictions placed on stride_x. However, ensure that stride_x is of appropriate size. For a typical case this means stride_x >= n * incx.
batch_count – [in] [rocblas_int] number of instances in the batch.
results – [out] device pointer or host pointer to array for storing contiguous batch_count results. return is 0.0 for each element if n <= 0, incx<=0.
rocblas_Xrot + batched, strided_batched#
-
rocblas_status rocblas_srot(rocblas_handle handle, rocblas_int n, float *x, rocblas_int incx, float *y, rocblas_int incy, const float *c, const float *s)#
-
rocblas_status rocblas_drot(rocblas_handle handle, rocblas_int n, double *x, rocblas_int incx, double *y, rocblas_int incy, const double *c, const double *s)#
-
rocblas_status rocblas_crot(rocblas_handle handle, rocblas_int n, rocblas_float_complex *x, rocblas_int incx, rocblas_float_complex *y, rocblas_int incy, const float *c, const rocblas_float_complex *s)#
-
rocblas_status rocblas_csrot(rocblas_handle handle, rocblas_int n, rocblas_float_complex *x, rocblas_int incx, rocblas_float_complex *y, rocblas_int incy, const float *c, const float *s)#
-
rocblas_status rocblas_zrot(rocblas_handle handle, rocblas_int n, rocblas_double_complex *x, rocblas_int incx, rocblas_double_complex *y, rocblas_int incy, const double *c, const rocblas_double_complex *s)#
-
rocblas_status rocblas_zdrot(rocblas_handle handle, rocblas_int n, rocblas_double_complex *x, rocblas_int incx, rocblas_double_complex *y, rocblas_int incy, const double *c, const double *s)#
BLAS Level 1 API
rot applies the Givens rotation matrix defined by c=cos(alpha) and s=sin(alpha) to vectors x and y. Scalars c and s may be stored in either host or device memory. Location is specified by calling rocblas_set_pointer_mode.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] number of elements in the x and y vectors.
x – [inout] device pointer storing vector x.
incx – [in] [rocblas_int] specifies the increment between elements of x.
y – [inout] device pointer storing vector y.
incy – [in] [rocblas_int] specifies the increment between elements of y.
c – [in] device pointer or host pointer storing scalar cosine component of the rotation matrix.
s – [in] device pointer or host pointer storing scalar sine component of the rotation matrix.
-
rocblas_status rocblas_srot_batched(rocblas_handle handle, rocblas_int n, float *const x[], rocblas_int incx, float *const y[], rocblas_int incy, const float *c, const float *s, rocblas_int batch_count)#
-
rocblas_status rocblas_drot_batched(rocblas_handle handle, rocblas_int n, double *const x[], rocblas_int incx, double *const y[], rocblas_int incy, const double *c, const double *s, rocblas_int batch_count)#
-
rocblas_status rocblas_crot_batched(rocblas_handle handle, rocblas_int n, rocblas_float_complex *const x[], rocblas_int incx, rocblas_float_complex *const y[], rocblas_int incy, const float *c, const rocblas_float_complex *s, rocblas_int batch_count)#
-
rocblas_status rocblas_csrot_batched(rocblas_handle handle, rocblas_int n, rocblas_float_complex *const x[], rocblas_int incx, rocblas_float_complex *const y[], rocblas_int incy, const float *c, const float *s, rocblas_int batch_count)#
-
rocblas_status rocblas_zrot_batched(rocblas_handle handle, rocblas_int n, rocblas_double_complex *const x[], rocblas_int incx, rocblas_double_complex *const y[], rocblas_int incy, const double *c, const rocblas_double_complex *s, rocblas_int batch_count)#
-
rocblas_status rocblas_zdrot_batched(rocblas_handle handle, rocblas_int n, rocblas_double_complex *const x[], rocblas_int incx, rocblas_double_complex *const y[], rocblas_int incy, const double *c, const double *s, rocblas_int batch_count)#
BLAS Level 1 API
rot_batched applies the Givens rotation matrix defined by c=cos(alpha) and s=sin(alpha) to batched vectors x_i and y_i, for i = 1, …, batch_count. Scalars c and s may be stored in either host or device memory. Location is specified by calling rocblas_set_pointer_mode.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] number of elements in each x_i and y_i vectors.
x – [inout] device array of deivce pointers storing each vector x_i.
incx – [in] [rocblas_int] specifies the increment between elements of each x_i.
y – [inout] device array of device pointers storing each vector y_i.
incy – [in] [rocblas_int] specifies the increment between elements of each y_i.
c – [in] device pointer or host pointer to scalar cosine component of the rotation matrix.
s – [in] device pointer or host pointer to scalar sine component of the rotation matrix.
batch_count – [in] [rocblas_int] the number of x and y arrays, i.e. the number of batches.
-
rocblas_status rocblas_srot_strided_batched(rocblas_handle handle, rocblas_int n, float *x, rocblas_int incx, rocblas_stride stride_x, float *y, rocblas_int incy, rocblas_stride stride_y, const float *c, const float *s, rocblas_int batch_count)#
-
rocblas_status rocblas_drot_strided_batched(rocblas_handle handle, rocblas_int n, double *x, rocblas_int incx, rocblas_stride stride_x, double *y, rocblas_int incy, rocblas_stride stride_y, const double *c, const double *s, rocblas_int batch_count)#
-
rocblas_status rocblas_crot_strided_batched(rocblas_handle handle, rocblas_int n, rocblas_float_complex *x, rocblas_int incx, rocblas_stride stride_x, rocblas_float_complex *y, rocblas_int incy, rocblas_stride stride_y, const float *c, const rocblas_float_complex *s, rocblas_int batch_count)#
-
rocblas_status rocblas_csrot_strided_batched(rocblas_handle handle, rocblas_int n, rocblas_float_complex *x, rocblas_int incx, rocblas_stride stride_x, rocblas_float_complex *y, rocblas_int incy, rocblas_stride stride_y, const float *c, const float *s, rocblas_int batch_count)#
-
rocblas_status rocblas_zrot_strided_batched(rocblas_handle handle, rocblas_int n, rocblas_double_complex *x, rocblas_int incx, rocblas_stride stride_x, rocblas_double_complex *y, rocblas_int incy, rocblas_stride stride_y, const double *c, const rocblas_double_complex *s, rocblas_int batch_count)#
-
rocblas_status rocblas_zdrot_strided_batched(rocblas_handle handle, rocblas_int n, rocblas_double_complex *x, rocblas_int incx, rocblas_stride stride_x, rocblas_double_complex *y, rocblas_int incy, rocblas_stride stride_y, const double *c, const double *s, rocblas_int batch_count)#
BLAS Level 1 API
rot_strided_batched applies the Givens rotation matrix defined by c=cos(alpha) and s=sin(alpha) to strided batched vectors x_i and y_i, for i = 1, …, batch_count. Scalars c and s may be stored in either host or device memory, location is specified by calling rocblas_set_pointer_mode.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] number of elements in each x_i and y_i vectors.
x – [inout] device pointer to the first vector x_1.
incx – [in] [rocblas_int] specifies the increment between elements of each x_i.
stride_x – [in] [rocblas_stride] specifies the increment from the beginning of x_i to the beginning of x_(i+1).
y – [inout] device pointer to the first vector y_1.
incy – [in] [rocblas_int] specifies the increment between elements of each y_i.
stride_y – [in] [rocblas_stride] specifies the increment from the beginning of y_i to the beginning of y_(i+1)
c – [in] device pointer or host pointer to scalar cosine component of the rotation matrix.
s – [in] device pointer or host pointer to scalar sine component of the rotation matrix.
batch_count – [in] [rocblas_int] the number of x and y arrays, i.e. the number of batches.
rocblas_Xrotg + batched, strided_batched#
-
rocblas_status rocblas_srotg(rocblas_handle handle, float *a, float *b, float *c, float *s)#
-
rocblas_status rocblas_drotg(rocblas_handle handle, double *a, double *b, double *c, double *s)#
-
rocblas_status rocblas_crotg(rocblas_handle handle, rocblas_float_complex *a, rocblas_float_complex *b, float *c, rocblas_float_complex *s)#
-
rocblas_status rocblas_zrotg(rocblas_handle handle, rocblas_double_complex *a, rocblas_double_complex *b, double *c, rocblas_double_complex *s)#
BLAS Level 1 API
rotg creates the Givens rotation matrix for the vector (a b). Scalars a, b, c, and s may be stored in either host or device memory, location is specified by calling rocblas_set_pointer_mode. The computation uses the formulas
sigma = sgn(a) if |a| > |b| = sgn(b) if |b| >= |a| r = sigma*sqrt( a**2 + b**2 ) c = 1; s = 0 if r = 0 c = a/r; s = b/r if r != 0
The subroutine also computes
z = s if |a| > |b|, = 1/c if |b| >= |a| and c != 0 = 1 if c = 0
This allows c and s to be reconstructed from z as follows:
If z = 1, set c = 0, s = 1. If |z| < 1, set c = sqrt(1 - z**2) and s = z. If |z| > 1, set c = 1/z and s = sqrt( 1 - c**2).
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
a – [inout] pointer to a, an element in vector (a,b), overwritten with r.
b – [inout] pointer to b, an element in vector (a,b), overwritten with z.
c – [out] pointer to c, cosine element of Givens rotation.
s – [out] pointer to s, sine element of Givens rotation.
-
rocblas_status rocblas_srotg_batched(rocblas_handle handle, float *const a[], float *const b[], float *const c[], float *const s[], rocblas_int batch_count)#
-
rocblas_status rocblas_drotg_batched(rocblas_handle handle, double *const a[], double *const b[], double *const c[], double *const s[], rocblas_int batch_count)#
-
rocblas_status rocblas_crotg_batched(rocblas_handle handle, rocblas_float_complex *const a[], rocblas_float_complex *const b[], float *const c[], rocblas_float_complex *const s[], rocblas_int batch_count)#
-
rocblas_status rocblas_zrotg_batched(rocblas_handle handle, rocblas_double_complex *const a[], rocblas_double_complex *const b[], double *const c[], rocblas_double_complex *const s[], rocblas_int batch_count)#
BLAS Level 1 API
rotg_batched creates the Givens rotation matrix for the batched vectors (a_i b_i), for i = 1, …, batch_count. a, b, c, and s are host pointers to an array of device pointers on the device, where each device pointer points to a scalar value of a_i, b_i, c_i, or s_i.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
a – [inout] a, overwritten with r.
b – [inout] b overwritten with z.
c – [out] cosine element of Givens rotation for the batch.
s – [out] sine element of Givens rotation for the batch.
batch_count – [in] [rocblas_int] number of batches (length of arrays a, b, c, and s).
-
rocblas_status rocblas_srotg_strided_batched(rocblas_handle handle, float *a, rocblas_stride stride_a, float *b, rocblas_stride stride_b, float *c, rocblas_stride stride_c, float *s, rocblas_stride stride_s, rocblas_int batch_count)#
-
rocblas_status rocblas_drotg_strided_batched(rocblas_handle handle, double *a, rocblas_stride stride_a, double *b, rocblas_stride stride_b, double *c, rocblas_stride stride_c, double *s, rocblas_stride stride_s, rocblas_int batch_count)#
-
rocblas_status rocblas_crotg_strided_batched(rocblas_handle handle, rocblas_float_complex *a, rocblas_stride stride_a, rocblas_float_complex *b, rocblas_stride stride_b, float *c, rocblas_stride stride_c, rocblas_float_complex *s, rocblas_stride stride_s, rocblas_int batch_count)#
-
rocblas_status rocblas_zrotg_strided_batched(rocblas_handle handle, rocblas_double_complex *a, rocblas_stride stride_a, rocblas_double_complex *b, rocblas_stride stride_b, double *c, rocblas_stride stride_c, rocblas_double_complex *s, rocblas_stride stride_s, rocblas_int batch_count)#
BLAS Level 1 API
rotg_strided_batched creates the Givens rotation matrix for the strided batched vectors (a_i b_i), for i = 1, …, batch_count. a, b, c, and s are host pointers to arrays a, b, c, s on the device.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
a – [inout] host pointer to first single input vector element a_1 on the device, overwritten with r.
stride_a – [in] [rocblas_stride] distance between elements of a in batch (distance between a_i and a_(i + 1)).
b – [inout] host pointer to first single input vector element b_1 on the device, overwritten with z.
stride_b – [in] [rocblas_stride] distance between elements of b in batch (distance between b_i and b_(i + 1)).
c – [out] host pointer to first single cosine element of Givens rotations c_1 on the device.
stride_c – [in] [rocblas_stride] distance between elements of c in batch (distance between c_i and c_(i + 1)).
s – [out] host pointer to first single sine element of Givens rotations s_1 on the device.
stride_s – [in] [rocblas_stride] distance between elements of s in batch (distance between s_i and s_(i + 1)).
batch_count – [in] [rocblas_int] number of batches (length of arrays a, b, c, and s).
rocblas_Xrotm + batched, strided_batched#
-
rocblas_status rocblas_srotm(rocblas_handle handle, rocblas_int n, float *x, rocblas_int incx, float *y, rocblas_int incy, const float *param)#
-
rocblas_status rocblas_drotm(rocblas_handle handle, rocblas_int n, double *x, rocblas_int incx, double *y, rocblas_int incy, const double *param)#
BLAS Level 1 API
rotm applies the modified Givens rotation matrix defined by param to vectors x and y.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] number of elements in the x and y vectors.
x – [inout] device pointer storing vector x.
incx – [in] [rocblas_int] specifies the increment between elements of x.
y – [inout] device pointer storing vector y.
incy – [in] [rocblas_int] specifies the increment between elements of y.
param – [in] device vector or host vector of 5 elements defining the rotation.
param[0] = flag param[1] = H11 param[2] = H21 param[3] = H12 param[4] = H22 The flag parameter defines the form of H: flag = -1 => H = ( H11 H12 H21 H22 ) flag = 0 => H = ( 1.0 H12 H21 1.0 ) flag = 1 => H = ( H11 1.0 -1.0 H22 ) flag = -2 => H = ( 1.0 0.0 0.0 1.0 ) param may be stored in either host or device memory, location is specified by calling rocblas_set_pointer_mode.
-
rocblas_status rocblas_srotm_batched(rocblas_handle handle, rocblas_int n, float *const x[], rocblas_int incx, float *const y[], rocblas_int incy, const float *const param[], rocblas_int batch_count)#
-
rocblas_status rocblas_drotm_batched(rocblas_handle handle, rocblas_int n, double *const x[], rocblas_int incx, double *const y[], rocblas_int incy, const double *const param[], rocblas_int batch_count)#
BLAS Level 1 API
rotm_batched applies the modified Givens rotation matrix defined by param_i to batched vectors x_i and y_i, for i = 1, …, batch_count.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] number of elements in the x and y vectors.
x – [inout] device array of device pointers storing each vector x_i.
incx – [in] [rocblas_int] specifies the increment between elements of each x_i.
y – [inout] device array of device pointers storing each vector y_1.
incy – [in] [rocblas_int] specifies the increment between elements of each y_i.
param – [in] device array of device vectors of 5 elements defining the rotation.
param[0] = flag param[1] = H11 param[2] = H21 param[3] = H12 param[4] = H22 The flag parameter defines the form of H: flag = -1 => H = ( H11 H12 H21 H22 ) flag = 0 => H = ( 1.0 H12 H21 1.0 ) flag = 1 => H = ( H11 1.0 -1.0 H22 ) flag = -2 => H = ( 1.0 0.0 0.0 1.0 ) param may ONLY be stored on the device for the batched version of this function.
batch_count – [in] [rocblas_int] the number of x and y arrays, i.e. the number of batches.
-
rocblas_status rocblas_srotm_strided_batched(rocblas_handle handle, rocblas_int n, float *x, rocblas_int incx, rocblas_stride stride_x, float *y, rocblas_int incy, rocblas_stride stride_y, const float *param, rocblas_stride stride_param, rocblas_int batch_count)#
-
rocblas_status rocblas_drotm_strided_batched(rocblas_handle handle, rocblas_int n, double *x, rocblas_int incx, rocblas_stride stride_x, double *y, rocblas_int incy, rocblas_stride stride_y, const double *param, rocblas_stride stride_param, rocblas_int batch_count)#
BLAS Level 1 API
rotm_strided_batched applies the modified Givens rotation matrix defined by param_i to strided batched vectors x_i and y_i, for i = 1, …, batch_count
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] number of elements in the x and y vectors.
x – [inout] device pointer pointing to first strided batched vector x_1.
incx – [in] [rocblas_int] specifies the increment between elements of each x_i.
stride_x – [in] [rocblas_stride] specifies the increment between the beginning of x_i and x_(i + 1)
y – [inout] device pointer pointing to first strided batched vector y_1.
incy – [in] [rocblas_int] specifies the increment between elements of each y_i.
stride_y – [in] [rocblas_stride] specifies the increment between the beginning of y_i and y_(i + 1).
param – [in] device pointer pointing to first array of 5 elements defining the rotation (param_1).
param[0] = flag param[1] = H11 param[2] = H21 param[3] = H12 param[4] = H22 The flag parameter defines the form of H: flag = -1 => H = ( H11 H12 H21 H22 ) flag = 0 => H = ( 1.0 H12 H21 1.0 ) flag = 1 => H = ( H11 1.0 -1.0 H22 ) flag = -2 => H = ( 1.0 0.0 0.0 1.0 ) param may ONLY be stored on the device for the strided_batched version of this function.
stride_param – [in] [rocblas_stride] specifies the increment between the beginning of param_i and param_(i + 1).
batch_count – [in] [rocblas_int] the number of x and y arrays, i.e. the number of batches.
rocblas_Xrotmg + batched, strided_batched#
-
rocblas_status rocblas_srotmg(rocblas_handle handle, float *d1, float *d2, float *x1, const float *y1, float *param)#
-
rocblas_status rocblas_drotmg(rocblas_handle handle, double *d1, double *d2, double *x1, const double *y1, double *param)#
BLAS Level 1 API
rotmg creates the modified Givens rotation matrix for the vector (d1 * x1, d2 * y1). Parameters may be stored in either host or device memory. Location is specified by calling rocblas_set_pointer_mode:
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
d1 – [inout] device pointer or host pointer to input scalar that is overwritten.
d2 – [inout] device pointer or host pointer to input scalar that is overwritten.
x1 – [inout] device pointer or host pointer to input scalar that is overwritten.
y1 – [in] device pointer or host pointer to input scalar.
param – [out] device vector or host vector of five elements defining the rotation.
param[0] = flag param[1] = H11 param[2] = H21 param[3] = H12 param[4] = H22 The flag parameter defines the form of H: flag = -1 => H = ( H11 H12 H21 H22 ) flag = 0 => H = ( 1.0 H12 H21 1.0 ) flag = 1 => H = ( H11 1.0 -1.0 H22 ) flag = -2 => H = ( 1.0 0.0 0.0 1.0 ) param may be stored in either host or device memory. Location is specified by calling rocblas_set_pointer_mode.
-
rocblas_status rocblas_srotmg_batched(rocblas_handle handle, float *const d1[], float *const d2[], float *const x1[], const float *const y1[], float *const param[], rocblas_int batch_count)#
-
rocblas_status rocblas_drotmg_batched(rocblas_handle handle, double *const d1[], double *const d2[], double *const x1[], const double *const y1[], double *const param[], rocblas_int batch_count)#
BLAS Level 1 API
rotmg_batched creates the modified Givens rotation matrix for the batched vectors (d1_i * x1_i, d2_i * y1_i), for i = 1, …, batch_count. Parameters may be stored in either host or device memory. Location is specified by calling rocblas_set_pointer_mode:
If the pointer mode is set to rocblas_pointer_mode_host, then this function blocks the CPU until the GPU has finished and the results are available in host memory.
If the pointer mode is set to rocblas_pointer_mode_device, then this function returns immediately and synchronization is required to read the results.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
d1 – [inout] device batched array or host batched array of input scalars that is overwritten.
d2 – [inout] device batched array or host batched array of input scalars that is overwritten.
x1 – [inout] device batched array or host batched array of input scalars that is overwritten.
y1 – [in] device batched array or host batched array of input scalars.
param – [out] device batched array or host batched array of vectors of 5 elements defining the rotation.
param[0] = flag param[1] = H11 param[2] = H21 param[3] = H12 param[4] = H22 The flag parameter defines the form of H: flag = -1 => H = ( H11 H12 H21 H22 ) flag = 0 => H = ( 1.0 H12 H21 1.0 ) flag = 1 => H = ( H11 1.0 -1.0 H22 ) flag = -2 => H = ( 1.0 0.0 0.0 1.0 ) param may be stored in either host or device memory. Location is specified by calling rocblas_set_pointer_mode.
batch_count – [in] [rocblas_int] the number of instances in the batch.
-
rocblas_status rocblas_srotmg_strided_batched(rocblas_handle handle, float *d1, rocblas_stride stride_d1, float *d2, rocblas_stride stride_d2, float *x1, rocblas_stride stride_x1, const float *y1, rocblas_stride stride_y1, float *param, rocblas_stride stride_param, rocblas_int batch_count)#
-
rocblas_status rocblas_drotmg_strided_batched(rocblas_handle handle, double *d1, rocblas_stride stride_d1, double *d2, rocblas_stride stride_d2, double *x1, rocblas_stride stride_x1, const double *y1, rocblas_stride stride_y1, double *param, rocblas_stride stride_param, rocblas_int batch_count)#
BLAS Level 1 API
rotmg_strided_batched creates the modified Givens rotation matrix for the strided batched vectors (d1_i * x1_i, d2_i * y1_i), for i = 1, …, batch_count. Parameters may be stored in either host or device memory. Location is specified by calling rocblas_set_pointer_mode:
If the pointer mode is set to rocblas_pointer_mode_host, then this function blocks the CPU until the GPU has finished and the results are available in host memory.
If the pointer mode is set to rocblas_pointer_mode_device, then this function returns immediately and synchronization is required to read the results.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
d1 – [inout] device strided_batched array or host strided_batched array of input scalars that is overwritten.
stride_d1 – [in] [rocblas_stride] specifies the increment between the beginning of d1_i and d1_(i+1).
d2 – [inout] device strided_batched array or host strided_batched array of input scalars that is overwritten.
stride_d2 – [in] [rocblas_stride] specifies the increment between the beginning of d2_i and d2_(i+1).
x1 – [inout] device strided_batched array or host strided_batched array of input scalars that is overwritten.
stride_x1 – [in] [rocblas_stride] specifies the increment between the beginning of x1_i and x1_(i+1).
y1 – [in] device strided_batched array or host strided_batched array of input scalars.
stride_y1 – [in] [rocblas_stride] specifies the increment between the beginning of y1_i and y1_(i+1).
param – [out] device strided_batched array or host strided_batched array of vectors of 5 elements defining the rotation.
param[0] = flag param[1] = H11 param[2] = H21 param[3] = H12 param[4] = H22 The flag parameter defines the form of H: flag = -1 => H = ( H11 H12 H21 H22 ) flag = 0 => H = ( 1.0 H12 H21 1.0 ) flag = 1 => H = ( H11 1.0 -1.0 H22 ) flag = -2 => H = ( 1.0 0.0 0.0 1.0 ) param may be stored in either host or device memory. Location is specified by calling rocblas_set_pointer_mode.
stride_param – [in] [rocblas_stride] specifies the increment between the beginning of param_i and param_(i + 1).
batch_count – [in] [rocblas_int] the number of instances in the batch.
rocblas_Xscal + batched, strided_batched#
-
rocblas_status rocblas_sscal(rocblas_handle handle, rocblas_int n, const float *alpha, float *x, rocblas_int incx)#
-
rocblas_status rocblas_dscal(rocblas_handle handle, rocblas_int n, const double *alpha, double *x, rocblas_int incx)#
-
rocblas_status rocblas_cscal(rocblas_handle handle, rocblas_int n, const rocblas_float_complex *alpha, rocblas_float_complex *x, rocblas_int incx)#
-
rocblas_status rocblas_zscal(rocblas_handle handle, rocblas_int n, const rocblas_double_complex *alpha, rocblas_double_complex *x, rocblas_int incx)#
-
rocblas_status rocblas_csscal(rocblas_handle handle, rocblas_int n, const float *alpha, rocblas_float_complex *x, rocblas_int incx)#
-
rocblas_status rocblas_zdscal(rocblas_handle handle, rocblas_int n, const double *alpha, rocblas_double_complex *x, rocblas_int incx)#
BLAS Level 1 API
scal scales each element of vector x with scalar alpha:
x := alpha * x
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] the number of elements in x.
alpha – [in] device pointer or host pointer for the scalar alpha.
x – [inout] device pointer storing vector x.
incx – [in] [rocblas_int] specifies the increment for the elements of x.
-
rocblas_status rocblas_sscal_batched(rocblas_handle handle, rocblas_int n, const float *alpha, float *const x[], rocblas_int incx, rocblas_int batch_count)#
-
rocblas_status rocblas_dscal_batched(rocblas_handle handle, rocblas_int n, const double *alpha, double *const x[], rocblas_int incx, rocblas_int batch_count)#
-
rocblas_status rocblas_cscal_batched(rocblas_handle handle, rocblas_int n, const rocblas_float_complex *alpha, rocblas_float_complex *const x[], rocblas_int incx, rocblas_int batch_count)#
-
rocblas_status rocblas_zscal_batched(rocblas_handle handle, rocblas_int n, const rocblas_double_complex *alpha, rocblas_double_complex *const x[], rocblas_int incx, rocblas_int batch_count)#
-
rocblas_status rocblas_csscal_batched(rocblas_handle handle, rocblas_int n, const float *alpha, rocblas_float_complex *const x[], rocblas_int incx, rocblas_int batch_count)#
-
rocblas_status rocblas_zdscal_batched(rocblas_handle handle, rocblas_int n, const double *alpha, rocblas_double_complex *const x[], rocblas_int incx, rocblas_int batch_count)#
BLAS Level 1 API
scal_batched scales each element of vector x_i with scalar alpha, for i = 1, … , batch_count:
x_i := alpha * x_i, where (x_i) is the i-th instance of the batch.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] the number of elements in each x_i.
alpha – [in] host pointer or device pointer for the scalar alpha.
x – [inout] device array of device pointers storing each vector x_i.
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i.
batch_count – [in] [rocblas_int] specifies the number of batches in x.
-
rocblas_status rocblas_sscal_strided_batched(rocblas_handle handle, rocblas_int n, const float *alpha, float *x, rocblas_int incx, rocblas_stride stride_x, rocblas_int batch_count)#
-
rocblas_status rocblas_dscal_strided_batched(rocblas_handle handle, rocblas_int n, const double *alpha, double *x, rocblas_int incx, rocblas_stride stride_x, rocblas_int batch_count)#
-
rocblas_status rocblas_cscal_strided_batched(rocblas_handle handle, rocblas_int n, const rocblas_float_complex *alpha, rocblas_float_complex *x, rocblas_int incx, rocblas_stride stride_x, rocblas_int batch_count)#
-
rocblas_status rocblas_zscal_strided_batched(rocblas_handle handle, rocblas_int n, const rocblas_double_complex *alpha, rocblas_double_complex *x, rocblas_int incx, rocblas_stride stride_x, rocblas_int batch_count)#
-
rocblas_status rocblas_csscal_strided_batched(rocblas_handle handle, rocblas_int n, const float *alpha, rocblas_float_complex *x, rocblas_int incx, rocblas_stride stride_x, rocblas_int batch_count)#
-
rocblas_status rocblas_zdscal_strided_batched(rocblas_handle handle, rocblas_int n, const double *alpha, rocblas_double_complex *x, rocblas_int incx, rocblas_stride stride_x, rocblas_int batch_count)#
BLAS Level 1 API
scal_strided_batched scales each element of vector x_i with scalar alpha, for i = 1, … , batch_count:
x_i := alpha * x_i, where (x_i) is the i-th instance of the batch.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] the number of elements in each x_i.
alpha – [in] host pointer or device pointer for the scalar alpha.
x – [inout] device pointer to the first vector (x_1) in the batch.
incx – [in] [rocblas_int] specifies the increment for the elements of x.
stride_x – [in] [rocblas_stride] stride from the start of one vector (x_i) and the next one (x_i+1). There are no restrictions placed on stride_x. However, ensure that stride_x is of appropriate size, for a typical case this means stride_x >= n * incx.
batch_count – [in] [rocblas_int] specifies the number of batches in x.
rocblas_Xswap + batched, strided_batched#
-
rocblas_status rocblas_sswap(rocblas_handle handle, rocblas_int n, float *x, rocblas_int incx, float *y, rocblas_int incy)#
-
rocblas_status rocblas_dswap(rocblas_handle handle, rocblas_int n, double *x, rocblas_int incx, double *y, rocblas_int incy)#
-
rocblas_status rocblas_cswap(rocblas_handle handle, rocblas_int n, rocblas_float_complex *x, rocblas_int incx, rocblas_float_complex *y, rocblas_int incy)#
-
rocblas_status rocblas_zswap(rocblas_handle handle, rocblas_int n, rocblas_double_complex *x, rocblas_int incx, rocblas_double_complex *y, rocblas_int incy)#
BLAS Level 1 API
swap interchanges vectors x and y:
y := x; x := y
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] the number of elements in x and y.
x – [inout] device pointer storing vector x.
incx – [in] [rocblas_int] specifies the increment for the elements of x.
y – [inout] device pointer storing vector y.
incy – [in] [rocblas_int] specifies the increment for the elements of y.
-
rocblas_status rocblas_sswap_batched(rocblas_handle handle, rocblas_int n, float *const x[], rocblas_int incx, float *const y[], rocblas_int incy, rocblas_int batch_count)#
-
rocblas_status rocblas_dswap_batched(rocblas_handle handle, rocblas_int n, double *const x[], rocblas_int incx, double *const y[], rocblas_int incy, rocblas_int batch_count)#
-
rocblas_status rocblas_cswap_batched(rocblas_handle handle, rocblas_int n, rocblas_float_complex *const x[], rocblas_int incx, rocblas_float_complex *const y[], rocblas_int incy, rocblas_int batch_count)#
-
rocblas_status rocblas_zswap_batched(rocblas_handle handle, rocblas_int n, rocblas_double_complex *const x[], rocblas_int incx, rocblas_double_complex *const y[], rocblas_int incy, rocblas_int batch_count)#
BLAS Level 1 API
swap_batched interchanges vectors x_i and y_i, for i = 1 , … , batch_count:
y_i := x_i; x_i := y_i
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] the number of elements in each x_i and y_i.
x – [inout] device array of device pointers storing each vector x_i.
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i.
y – [inout] device array of device pointers storing each vector y_i.
incy – [in] [rocblas_int] specifies the increment for the elements of each y_i.
batch_count – [in] [rocblas_int] number of instances in the batch.
-
rocblas_status rocblas_sswap_strided_batched(rocblas_handle handle, rocblas_int n, float *x, rocblas_int incx, rocblas_stride stridex, float *y, rocblas_int incy, rocblas_stride stridey, rocblas_int batch_count)#
-
rocblas_status rocblas_dswap_strided_batched(rocblas_handle handle, rocblas_int n, double *x, rocblas_int incx, rocblas_stride stridex, double *y, rocblas_int incy, rocblas_stride stridey, rocblas_int batch_count)#
-
rocblas_status rocblas_cswap_strided_batched(rocblas_handle handle, rocblas_int n, rocblas_float_complex *x, rocblas_int incx, rocblas_stride stridex, rocblas_float_complex *y, rocblas_int incy, rocblas_stride stridey, rocblas_int batch_count)#
-
rocblas_status rocblas_zswap_strided_batched(rocblas_handle handle, rocblas_int n, rocblas_double_complex *x, rocblas_int incx, rocblas_stride stridex, rocblas_double_complex *y, rocblas_int incy, rocblas_stride stridey, rocblas_int batch_count)#
BLAS Level 1 API
swap_strided_batched interchanges vectors x_i and y_i, for i = 1 , … , batch_count:
y_i := x_i; x_i := y_i
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] the number of elements in each x_i and y_i.
x – [inout] device pointer to the first vector x_1.
incx – [in] [rocblas_int] specifies the increment for the elements of x.
stridex – [in] [rocblas_stride] stride from the start of one vector (x_i) and the next one (x_i+1). There are no restrictions placed on stride_x. However, ensure that stride_x is of appropriate size. For a typical case this means stride_x >= n * incx.
y – [inout] device pointer to the first vector y_1.
incy – [in] [rocblas_int] specifies the increment for the elements of y.
stridey – [in] [rocblas_stride] stride from the start of one vector (y_i) and the next one (y_i+1). There are no restrictions placed on stride_x. However, ensure that stride_y is of appropriate size. For a typical case this means stride_y >= n * incy. stridey should be non zero.
batch_count – [in] [rocblas_int] number of instances in the batch.
rocBLAS Level-2 functions#
rocblas_Xgbmv + batched, strided_batched#
-
rocblas_status rocblas_sgbmv(rocblas_handle handle, rocblas_operation trans, rocblas_int m, rocblas_int n, rocblas_int kl, rocblas_int ku, const float *alpha, const float *A, rocblas_int lda, const float *x, rocblas_int incx, const float *beta, float *y, rocblas_int incy)#
-
rocblas_status rocblas_dgbmv(rocblas_handle handle, rocblas_operation trans, rocblas_int m, rocblas_int n, rocblas_int kl, rocblas_int ku, const double *alpha, const double *A, rocblas_int lda, const double *x, rocblas_int incx, const double *beta, double *y, rocblas_int incy)#
-
rocblas_status rocblas_cgbmv(rocblas_handle handle, rocblas_operation trans, rocblas_int m, rocblas_int n, rocblas_int kl, rocblas_int ku, const rocblas_float_complex *alpha, const rocblas_float_complex *A, rocblas_int lda, const rocblas_float_complex *x, rocblas_int incx, const rocblas_float_complex *beta, rocblas_float_complex *y, rocblas_int incy)#
-
rocblas_status rocblas_zgbmv(rocblas_handle handle, rocblas_operation trans, rocblas_int m, rocblas_int n, rocblas_int kl, rocblas_int ku, const rocblas_double_complex *alpha, const rocblas_double_complex *A, rocblas_int lda, const rocblas_double_complex *x, rocblas_int incx, const rocblas_double_complex *beta, rocblas_double_complex *y, rocblas_int incy)#
BLAS Level 2 API
gbmv performs one of the matrix-vector operations:
y := alpha*A*x + beta*y, or y := alpha*A**T*x + beta*y, or y := alpha*A**H*x + beta*y, where alpha and beta are scalars, x and y are vectors and A is an m by n banded matrix with kl sub-diagonals and ku super-diagonals.
Note that the empty elements which do not correspond to data will not be referenced.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
trans – [in] [rocblas_operation] indicates whether matrix A is tranposed (conjugated) or not.
m – [in] [rocblas_int] number of rows of matrix A.
n – [in] [rocblas_int] number of columns of matrix A.
kl – [in] [rocblas_int] number of sub-diagonals of A.
ku – [in] [rocblas_int] number of super-diagonals of A.
alpha – [in] device pointer or host pointer to scalar alpha.
A – [in] device pointer storing banded matrix A. Leading (kl + ku + 1) by n part of the matrix contains the coefficients of the banded matrix. The leading diagonal resides in row (ku + 1) with the first super-diagonal above on the RHS of row ku. The first sub-diagonal resides below on the LHS of row ku + 2. This propagates up and down across sub/super-diagonals.
Ex: (m = n = 7; ku = 2, kl = 2) 1 2 3 0 0 0 0 0 0 3 3 3 3 3 4 1 2 3 0 0 0 0 2 2 2 2 2 2 5 4 1 2 3 0 0 ----> 1 1 1 1 1 1 1 0 5 4 1 2 3 0 4 4 4 4 4 4 0 0 0 5 4 1 2 0 5 5 5 5 5 0 0 0 0 0 5 4 1 2 0 0 0 0 0 0 0 0 0 0 0 5 4 1 0 0 0 0 0 0 0
lda – [in] [rocblas_int] specifies the leading dimension of A. Must be >= (kl + ku + 1).
x – [in] device pointer storing vector x.
incx – [in] [rocblas_int] specifies the increment for the elements of x.
beta – [in] device pointer or host pointer to scalar beta.
y – [inout] device pointer storing vector y.
incy – [in] [rocblas_int] specifies the increment for the elements of y.
-
rocblas_status rocblas_sgbmv_batched(rocblas_handle handle, rocblas_operation trans, rocblas_int m, rocblas_int n, rocblas_int kl, rocblas_int ku, const float *alpha, const float *const A[], rocblas_int lda, const float *const x[], rocblas_int incx, const float *beta, float *const y[], rocblas_int incy, rocblas_int batch_count)#
-
rocblas_status rocblas_dgbmv_batched(rocblas_handle handle, rocblas_operation trans, rocblas_int m, rocblas_int n, rocblas_int kl, rocblas_int ku, const double *alpha, const double *const A[], rocblas_int lda, const double *const x[], rocblas_int incx, const double *beta, double *const y[], rocblas_int incy, rocblas_int batch_count)#
-
rocblas_status rocblas_cgbmv_batched(rocblas_handle handle, rocblas_operation trans, rocblas_int m, rocblas_int n, rocblas_int kl, rocblas_int ku, const rocblas_float_complex *alpha, const rocblas_float_complex *const A[], rocblas_int lda, const rocblas_float_complex *const x[], rocblas_int incx, const rocblas_float_complex *beta, rocblas_float_complex *const y[], rocblas_int incy, rocblas_int batch_count)#
-
rocblas_status rocblas_zgbmv_batched(rocblas_handle handle, rocblas_operation trans, rocblas_int m, rocblas_int n, rocblas_int kl, rocblas_int ku, const rocblas_double_complex *alpha, const rocblas_double_complex *const A[], rocblas_int lda, const rocblas_double_complex *const x[], rocblas_int incx, const rocblas_double_complex *beta, rocblas_double_complex *const y[], rocblas_int incy, rocblas_int batch_count)#
BLAS Level 2 API
gbmv_batched performs one of the matrix-vector operations:
y_i := alpha*A_i*x_i + beta*y_i, or y_i := alpha*A_i**T*x_i + beta*y_i, or y_i := alpha*A_i**H*x_i + beta*y_i, where (A_i, x_i, y_i) is the i-th instance of the batch. alpha and beta are scalars, x_i and y_i are vectors and A_i is an m by n banded matrix with kl sub-diagonals and ku super-diagonals, for i = 1, ..., batch_count.
Note that the empty elements which do not correspond to data will not be referenced.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
trans – [in] [rocblas_operation] indicates whether matrix A is tranposed (conjugated) or not.
m – [in] [rocblas_int] number of rows of each matrix A_i.
n – [in] [rocblas_int] number of columns of each matrix A_i.
kl – [in] [rocblas_int] number of sub-diagonals of each A_i.
ku – [in] [rocblas_int] number of super-diagonals of each A_i.
alpha – [in] device pointer or host pointer to scalar alpha.
A – [in] device array of device pointers storing each banded matrix A_i. Leading (kl + ku + 1) by n part of the matrix contains the coefficients of the banded matrix. The leading diagonal resides in row (ku + 1) with the first super-diagonal above on the RHS of row ku. The first sub-diagonal resides below on the LHS of row ku + 2. This propagates up and down across sub/super-diagonals.
Ex: (m = n = 7; ku = 2, kl = 2) 1 2 3 0 0 0 0 0 0 3 3 3 3 3 4 1 2 3 0 0 0 0 2 2 2 2 2 2 5 4 1 2 3 0 0 ----> 1 1 1 1 1 1 1 0 5 4 1 2 3 0 4 4 4 4 4 4 0 0 0 5 4 1 2 0 5 5 5 5 5 0 0 0 0 0 5 4 1 2 0 0 0 0 0 0 0 0 0 0 0 5 4 1 0 0 0 0 0 0 0
lda – [in] [rocblas_int] specifies the leading dimension of each A_i. Must be >= (kl + ku + 1)
x – [in] device array of device pointers storing each vector x_i.
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i.
beta – [in] device pointer or host pointer to scalar beta.
y – [inout] device array of device pointers storing each vector y_i.
incy – [in] [rocblas_int] specifies the increment for the elements of each y_i.
batch_count – [in] [rocblas_int] specifies the number of instances in the batch.
-
rocblas_status rocblas_sgbmv_strided_batched(rocblas_handle handle, rocblas_operation trans, rocblas_int m, rocblas_int n, rocblas_int kl, rocblas_int ku, const float *alpha, const float *A, rocblas_int lda, rocblas_stride stride_A, const float *x, rocblas_int incx, rocblas_stride stride_x, const float *beta, float *y, rocblas_int incy, rocblas_stride stride_y, rocblas_int batch_count)#
-
rocblas_status rocblas_dgbmv_strided_batched(rocblas_handle handle, rocblas_operation trans, rocblas_int m, rocblas_int n, rocblas_int kl, rocblas_int ku, const double *alpha, const double *A, rocblas_int lda, rocblas_stride stride_A, const double *x, rocblas_int incx, rocblas_stride stride_x, const double *beta, double *y, rocblas_int incy, rocblas_stride stride_y, rocblas_int batch_count)#
-
rocblas_status rocblas_cgbmv_strided_batched(rocblas_handle handle, rocblas_operation trans, rocblas_int m, rocblas_int n, rocblas_int kl, rocblas_int ku, const rocblas_float_complex *alpha, const rocblas_float_complex *A, rocblas_int lda, rocblas_stride stride_A, const rocblas_float_complex *x, rocblas_int incx, rocblas_stride stride_x, const rocblas_float_complex *beta, rocblas_float_complex *y, rocblas_int incy, rocblas_stride stride_y, rocblas_int batch_count)#
-
rocblas_status rocblas_zgbmv_strided_batched(rocblas_handle handle, rocblas_operation trans, rocblas_int m, rocblas_int n, rocblas_int kl, rocblas_int ku, const rocblas_double_complex *alpha, const rocblas_double_complex *A, rocblas_int lda, rocblas_stride stride_A, const rocblas_double_complex *x, rocblas_int incx, rocblas_stride stride_x, const rocblas_double_complex *beta, rocblas_double_complex *y, rocblas_int incy, rocblas_stride stride_y, rocblas_int batch_count)#
BLAS Level 2 API
gbmv_strided_batched performs one of the matrix-vector operations:
y_i := alpha*A_i*x_i + beta*y_i, or y_i := alpha*A_i**T*x_i + beta*y_i, or y_i := alpha*A_i**H*x_i + beta*y_i, where (A_i, x_i, y_i) is the i-th instance of the batch. alpha and beta are scalars, x_i and y_i are vectors and A_i is an m by n banded matrix with kl sub-diagonals and ku super-diagonals, for i = 1, ..., batch_count.
Note that the empty elements which do not correspond to data will not be referenced.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
trans – [in] [rocblas_operation] indicates whether matrix A is tranposed (conjugated) or not.
m – [in] [rocblas_int] number of rows of matrix A.
n – [in] [rocblas_int] number of columns of matrix A.
kl – [in] [rocblas_int] number of sub-diagonals of A.
ku – [in] [rocblas_int] number of super-diagonals of A.
alpha – [in] device pointer or host pointer to scalar alpha.
A – [in] device pointer to first banded matrix (A_1). Leading (kl + ku + 1) by n part of the matrix contains the coefficients of the banded matrix. The leading diagonal resides in row (ku + 1) with the first super-diagonal above on the RHS of row ku. The first sub-diagonal resides below on the LHS of row ku + 2. This propagates up and down across sub/super-diagonals.
Ex: (m = n = 7; ku = 2, kl = 2) 1 2 3 0 0 0 0 0 0 3 3 3 3 3 4 1 2 3 0 0 0 0 2 2 2 2 2 2 5 4 1 2 3 0 0 ----> 1 1 1 1 1 1 1 0 5 4 1 2 3 0 4 4 4 4 4 4 0 0 0 5 4 1 2 0 5 5 5 5 5 0 0 0 0 0 5 4 1 2 0 0 0 0 0 0 0 0 0 0 0 5 4 1 0 0 0 0 0 0 0
lda – [in] [rocblas_int] specifies the leading dimension of A. Must be >= (kl + ku + 1).
stride_A – [in] [rocblas_stride] stride from the start of one matrix (A_i) and the next one (A_i+1).
x – [in] device pointer to first vector (x_1).
incx – [in] [rocblas_int] specifies the increment for the elements of x.
stride_x – [in] [rocblas_stride] stride from the start of one vector (x_i) and the next one (x_i+1).
beta – [in] device pointer or host pointer to scalar beta.
y – [inout] device pointer to first vector (y_1).
incy – [in] [rocblas_int] specifies the increment for the elements of y.
stride_y – [in] [rocblas_stride] stride from the start of one vector (y_i) and the next one (x_i+1).
batch_count – [in] [rocblas_int] specifies the number of instances in the batch.
rocblas_Xgemv + batched, strided_batched#
-
rocblas_status rocblas_sgemv(rocblas_handle handle, rocblas_operation trans, rocblas_int m, rocblas_int n, const float *alpha, const float *A, rocblas_int lda, const float *x, rocblas_int incx, const float *beta, float *y, rocblas_int incy)#
-
rocblas_status rocblas_dgemv(rocblas_handle handle, rocblas_operation trans, rocblas_int m, rocblas_int n, const double *alpha, const double *A, rocblas_int lda, const double *x, rocblas_int incx, const double *beta, double *y, rocblas_int incy)#
-
rocblas_status rocblas_cgemv(rocblas_handle handle, rocblas_operation trans, rocblas_int m, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *A, rocblas_int lda, const rocblas_float_complex *x, rocblas_int incx, const rocblas_float_complex *beta, rocblas_float_complex *y, rocblas_int incy)#
-
rocblas_status rocblas_zgemv(rocblas_handle handle, rocblas_operation trans, rocblas_int m, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *A, rocblas_int lda, const rocblas_double_complex *x, rocblas_int incx, const rocblas_double_complex *beta, rocblas_double_complex *y, rocblas_int incy)#
BLAS Level 2 API
gemv performs one of the matrix-vector operations:
y := alpha*A*x + beta*y, or y := alpha*A**T*x + beta*y, or y := alpha*A**H*x + beta*y, where alpha and beta are scalars, x and y are vectors and A is an m by n matrix.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
trans – [in] [rocblas_operation] indicates whether matrix A is tranposed (conjugated) or not.
m – [in] [rocblas_int] number of rows of matrix A.
n – [in] [rocblas_int] number of columns of matrix A.
alpha – [in] device pointer or host pointer to scalar alpha.
A – [in] device pointer storing matrix A.
lda – [in] [rocblas_int] specifies the leading dimension of A.
x – [in] device pointer storing vector x.
incx – [in] [rocblas_int] specifies the increment for the elements of x.
beta – [in] device pointer or host pointer to scalar beta.
y – [inout] device pointer storing vector y.
incy – [in] [rocblas_int] specifies the increment for the elements of y.
-
rocblas_status rocblas_sgemv_batched(rocblas_handle handle, rocblas_operation trans, rocblas_int m, rocblas_int n, const float *alpha, const float *const A[], rocblas_int lda, const float *const x[], rocblas_int incx, const float *beta, float *const y[], rocblas_int incy, rocblas_int batch_count)#
-
rocblas_status rocblas_dgemv_batched(rocblas_handle handle, rocblas_operation trans, rocblas_int m, rocblas_int n, const double *alpha, const double *const A[], rocblas_int lda, const double *const x[], rocblas_int incx, const double *beta, double *const y[], rocblas_int incy, rocblas_int batch_count)#
-
rocblas_status rocblas_cgemv_batched(rocblas_handle handle, rocblas_operation trans, rocblas_int m, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *const A[], rocblas_int lda, const rocblas_float_complex *const x[], rocblas_int incx, const rocblas_float_complex *beta, rocblas_float_complex *const y[], rocblas_int incy, rocblas_int batch_count)#
-
rocblas_status rocblas_zgemv_batched(rocblas_handle handle, rocblas_operation trans, rocblas_int m, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *const A[], rocblas_int lda, const rocblas_double_complex *const x[], rocblas_int incx, const rocblas_double_complex *beta, rocblas_double_complex *const y[], rocblas_int incy, rocblas_int batch_count)#
BLAS Level 2 API
gemv_batched performs a batch of matrix-vector operations:
y_i := alpha*A_i*x_i + beta*y_i, or y_i := alpha*A_i**T*x_i + beta*y_i, or y_i := alpha*A_i**H*x_i + beta*y_i, where (A_i, x_i, y_i) is the i-th instance of the batch. alpha and beta are scalars, x_i and y_i are vectors and A_i is an m by n matrix, for i = 1, ..., batch_count.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
trans – [in] [rocblas_operation] indicates whether matrices A_i are tranposed (conjugated) or not.
m – [in] [rocblas_int] number of rows of each matrix A_i.
n – [in] [rocblas_int] number of columns of each matrix A_i.
alpha – [in] device pointer or host pointer to scalar alpha.
A – [in] device array of device pointers storing each matrix A_i.
lda – [in] [rocblas_int] specifies the leading dimension of each matrix A_i.
x – [in] device array of device pointers storing each vector x_i.
incx – [in] [rocblas_int] specifies the increment for the elements of each vector x_i.
beta – [in] device pointer or host pointer to scalar beta.
y – [inout] device array of device pointers storing each vector y_i.
incy – [in] [rocblas_int] specifies the increment for the elements of each vector y_i.
batch_count – [in] [rocblas_int] number of instances in the batch.
-
rocblas_status rocblas_sgemv_strided_batched(rocblas_handle handle, rocblas_operation transA, rocblas_int m, rocblas_int n, const float *alpha, const float *A, rocblas_int lda, rocblas_stride strideA, const float *x, rocblas_int incx, rocblas_stride stridex, const float *beta, float *y, rocblas_int incy, rocblas_stride stridey, rocblas_int batch_count)#
-
rocblas_status rocblas_dgemv_strided_batched(rocblas_handle handle, rocblas_operation transA, rocblas_int m, rocblas_int n, const double *alpha, const double *A, rocblas_int lda, rocblas_stride strideA, const double *x, rocblas_int incx, rocblas_stride stridex, const double *beta, double *y, rocblas_int incy, rocblas_stride stridey, rocblas_int batch_count)#
-
rocblas_status rocblas_cgemv_strided_batched(rocblas_handle handle, rocblas_operation transA, rocblas_int m, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *A, rocblas_int lda, rocblas_stride strideA, const rocblas_float_complex *x, rocblas_int incx, rocblas_stride stridex, const rocblas_float_complex *beta, rocblas_float_complex *y, rocblas_int incy, rocblas_stride stridey, rocblas_int batch_count)#
-
rocblas_status rocblas_zgemv_strided_batched(rocblas_handle handle, rocblas_operation transA, rocblas_int m, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *A, rocblas_int lda, rocblas_stride strideA, const rocblas_double_complex *x, rocblas_int incx, rocblas_stride stridex, const rocblas_double_complex *beta, rocblas_double_complex *y, rocblas_int incy, rocblas_stride stridey, rocblas_int batch_count)#
BLAS Level 2 API
gemv_strided_batched performs a batch of matrix-vector operations:
y_i := alpha*A_i*x_i + beta*y_i, or y_i := alpha*A_i**T*x_i + beta*y_i, or y_i := alpha*A_i**H*x_i + beta*y_i, where (A_i, x_i, y_i) is the i-th instance of the batch. alpha and beta are scalars, x_i and y_i are vectors and A_i is an m by n matrix, for i = 1, ..., batch_count.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
transA – [in] [rocblas_operation] indicates whether matrices A_i are tranposed (conjugated) or not.
m – [in] [rocblas_int] number of rows of matrices A_i.
n – [in] [rocblas_int] number of columns of matrices A_i.
alpha – [in] device pointer or host pointer to scalar alpha.
A – [in] device pointer to the first matrix (A_1) in the batch.
lda – [in] [rocblas_int] specifies the leading dimension of matrices A_i.
strideA – [in] [rocblas_stride] stride from the start of one matrix (A_i) and the next one (A_i+1).
x – [in] device pointer to the first vector (x_1) in the batch.
incx – [in] [rocblas_int] specifies the increment for the elements of vectors x_i.
stridex – [in] [rocblas_stride] stride from the start of one vector (x_i) and the next one (x_i+1). There are no restrictions placed on stride_x. However, ensure that stride_x is of appropriate size. When trans equals rocblas_operation_none this typically means stride_x >= n * incx, otherwise stride_x >= m * incx.
beta – [in] device pointer or host pointer to scalar beta.
y – [inout] device pointer to the first vector (y_1) in the batch.
incy – [in] [rocblas_int] specifies the increment for the elements of vectors y_i.
stridey – [in] [rocblas_stride] stride from the start of one vector (y_i) and the next one (y_i+1). There are no restrictions placed on stride_y. However, ensure that stride_y is of appropriate size. When trans equals rocblas_operation_none this typically means stride_y >= m * incy, otherwise stride_y >= n * incy. stridey should be non zero.
batch_count – [in] [rocblas_int] number of instances in the batch.
rocblas_Xger + batched, strided_batched#
-
rocblas_status rocblas_sger(rocblas_handle handle, rocblas_int m, rocblas_int n, const float *alpha, const float *x, rocblas_int incx, const float *y, rocblas_int incy, float *A, rocblas_int lda)#
-
rocblas_status rocblas_dger(rocblas_handle handle, rocblas_int m, rocblas_int n, const double *alpha, const double *x, rocblas_int incx, const double *y, rocblas_int incy, double *A, rocblas_int lda)#
-
rocblas_status rocblas_cgeru(rocblas_handle handle, rocblas_int m, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *x, rocblas_int incx, const rocblas_float_complex *y, rocblas_int incy, rocblas_float_complex *A, rocblas_int lda)#
-
rocblas_status rocblas_zgeru(rocblas_handle handle, rocblas_int m, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *x, rocblas_int incx, const rocblas_double_complex *y, rocblas_int incy, rocblas_double_complex *A, rocblas_int lda)#
-
rocblas_status rocblas_cgerc(rocblas_handle handle, rocblas_int m, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *x, rocblas_int incx, const rocblas_float_complex *y, rocblas_int incy, rocblas_float_complex *A, rocblas_int lda)#
-
rocblas_status rocblas_zgerc(rocblas_handle handle, rocblas_int m, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *x, rocblas_int incx, const rocblas_double_complex *y, rocblas_int incy, rocblas_double_complex *A, rocblas_int lda)#
BLAS Level 2 API
ger,geru,gerc performs the matrix-vector operations:
A := A + alpha*x*y**T , OR A := A + alpha*x*y**H for gerc where alpha is a scalar, x and y are vectors, and A is an m by n matrix.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
m – [in] [rocblas_int] the number of rows of the matrix A.
n – [in] [rocblas_int] the number of columns of the matrix A.
alpha – [in] device pointer or host pointer to scalar alpha.
x – [in] device pointer storing vector x.
incx – [in] [rocblas_int] specifies the increment for the elements of x.
y – [in] device pointer storing vector y.
incy – [in] [rocblas_int] specifies the increment for the elements of y.
A – [inout] device pointer storing matrix A.
lda – [in] [rocblas_int] specifies the leading dimension of A.
-
rocblas_status rocblas_sger_batched(rocblas_handle handle, rocblas_int m, rocblas_int n, const float *alpha, const float *const x[], rocblas_int incx, const float *const y[], rocblas_int incy, float *const A[], rocblas_int lda, rocblas_int batch_count)#
-
rocblas_status rocblas_dger_batched(rocblas_handle handle, rocblas_int m, rocblas_int n, const double *alpha, const double *const x[], rocblas_int incx, const double *const y[], rocblas_int incy, double *const A[], rocblas_int lda, rocblas_int batch_count)#
-
rocblas_status rocblas_cgeru_batched(rocblas_handle handle, rocblas_int m, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *const x[], rocblas_int incx, const rocblas_float_complex *const y[], rocblas_int incy, rocblas_float_complex *const A[], rocblas_int lda, rocblas_int batch_count)#
-
rocblas_status rocblas_zgeru_batched(rocblas_handle handle, rocblas_int m, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *const x[], rocblas_int incx, const rocblas_double_complex *const y[], rocblas_int incy, rocblas_double_complex *const A[], rocblas_int lda, rocblas_int batch_count)#
-
rocblas_status rocblas_cgerc_batched(rocblas_handle handle, rocblas_int m, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *const x[], rocblas_int incx, const rocblas_float_complex *const y[], rocblas_int incy, rocblas_float_complex *const A[], rocblas_int lda, rocblas_int batch_count)#
-
rocblas_status rocblas_zgerc_batched(rocblas_handle handle, rocblas_int m, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *const x[], rocblas_int incx, const rocblas_double_complex *const y[], rocblas_int incy, rocblas_double_complex *const A[], rocblas_int lda, rocblas_int batch_count)#
BLAS Level 2 API
ger_batched,geru_batched,gerc_batched perform a batch of the matrix-vector operations:
A := A + alpha*x*y**T , OR A := A + alpha*x*y**H for gerc where (A_i, x_i, y_i) is the i-th instance of the batch. alpha is a scalar, x_i and y_i are vectors and A_i is an m by n matrix, for i = 1, ..., batch_count.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
m – [in] [rocblas_int] the number of rows of each matrix A_i.
n – [in] [rocblas_int] the number of columns of each matrix A_i.
alpha – [in] device pointer or host pointer to scalar alpha.
x – [in] device array of device pointers storing each vector x_i.
incx – [in] [rocblas_int] specifies the increment for the elements of each vector x_i.
y – [in] device array of device pointers storing each vector y_i.
incy – [in] [rocblas_int] specifies the increment for the elements of each vector y_i.
A – [inout] device array of device pointers storing each matrix A_i.
lda – [in] [rocblas_int] specifies the leading dimension of each A_i.
batch_count – [in] [rocblas_int] number of instances in the batch.
-
rocblas_status rocblas_sger_strided_batched(rocblas_handle handle, rocblas_int m, rocblas_int n, const float *alpha, const float *x, rocblas_int incx, rocblas_stride stridex, const float *y, rocblas_int incy, rocblas_stride stridey, float *A, rocblas_int lda, rocblas_stride strideA, rocblas_int batch_count)#
-
rocblas_status rocblas_dger_strided_batched(rocblas_handle handle, rocblas_int m, rocblas_int n, const double *alpha, const double *x, rocblas_int incx, rocblas_stride stridex, const double *y, rocblas_int incy, rocblas_stride stridey, double *A, rocblas_int lda, rocblas_stride strideA, rocblas_int batch_count)#
-
rocblas_status rocblas_cgeru_strided_batched(rocblas_handle handle, rocblas_int m, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *x, rocblas_int incx, rocblas_stride stridex, const rocblas_float_complex *y, rocblas_int incy, rocblas_stride stridey, rocblas_float_complex *A, rocblas_int lda, rocblas_stride strideA, rocblas_int batch_count)#
-
rocblas_status rocblas_zgeru_strided_batched(rocblas_handle handle, rocblas_int m, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *x, rocblas_int incx, rocblas_stride stridex, const rocblas_double_complex *y, rocblas_int incy, rocblas_stride stridey, rocblas_double_complex *A, rocblas_int lda, rocblas_stride strideA, rocblas_int batch_count)#
-
rocblas_status rocblas_cgerc_strided_batched(rocblas_handle handle, rocblas_int m, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *x, rocblas_int incx, rocblas_stride stridex, const rocblas_float_complex *y, rocblas_int incy, rocblas_stride stridey, rocblas_float_complex *A, rocblas_int lda, rocblas_stride strideA, rocblas_int batch_count)#
-
rocblas_status rocblas_zgerc_strided_batched(rocblas_handle handle, rocblas_int m, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *x, rocblas_int incx, rocblas_stride stridex, const rocblas_double_complex *y, rocblas_int incy, rocblas_stride stridey, rocblas_double_complex *A, rocblas_int lda, rocblas_stride strideA, rocblas_int batch_count)#
BLAS Level 2 API
ger_strided_batched,geru_strided_batched,gerc_strided_batched performs the matrix-vector operations:
A_i := A_i + alpha*x_i*y_i**T, OR A_i := A_i + alpha*x_i*y_i**H for gerc where (A_i, x_i, y_i) is the i-th instance of the batch. alpha is a scalar, x_i and y_i are vectors and A_i is an m by n matrix, for i = 1, ..., batch_count.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
m – [in] [rocblas_int] the number of rows of each matrix A_i.
n – [in] [rocblas_int] the number of columns of each matrix A_i.
alpha – [in] device pointer or host pointer to scalar alpha.
x – [in] device pointer to the first vector (x_1) in the batch.
incx – [in] [rocblas_int] specifies the increments for the elements of each vector x_i.
stridex – [in] [rocblas_stride] stride from the start of one vector (x_i) and the next one (x_i+1). There are no restrictions placed on stride_x. However, ensure that stride_x is of appropriate size. For a typical case this means stride_x >= m * incx.
y – [inout] device pointer to the first vector (y_1) in the batch.
incy – [in] [rocblas_int] specifies the increment for the elements of each vector y_i.
stridey – [in] [rocblas_stride] stride from the start of one vector (y_i) and the next one (y_i+1). There are no restrictions placed on stride_y. However, ensure that stride_y is of appropriate size. For a typical case this means stride_y >= n * incy.
A – [inout] device pointer to the first matrix (A_1) in the batch.
lda – [in] [rocblas_int] specifies the leading dimension of each A_i.
strideA – [in] [rocblas_stride] stride from the start of one matrix (A_i) and the next one (A_i+1)
batch_count – [in] [rocblas_int] number of instances in the batch.
rocblas_Xsbmv + batched, strided_batched#
-
rocblas_status rocblas_ssbmv(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, rocblas_int k, const float *alpha, const float *A, rocblas_int lda, const float *x, rocblas_int incx, const float *beta, float *y, rocblas_int incy)#
-
rocblas_status rocblas_dsbmv(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, rocblas_int k, const double *alpha, const double *A, rocblas_int lda, const double *x, rocblas_int incx, const double *beta, double *y, rocblas_int incy)#
BLAS Level 2 API
sbmv performs the matrix-vector operation:
y := alpha*A*x + beta*y where alpha and beta are scalars, x and y are n element vectors and A should contain an upper or lower triangular n by n symmetric banded matrix.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] rocblas_fill specifies whether the upper ‘rocblas_fill_upper’ or lower ‘rocblas_fill_lower’
if rocblas_fill_upper, the lower part of A is not referenced
if rocblas_fill_lower, the upper part of A is not referenced
n – [in] [rocblas_int]
k – [in] [rocblas_int] specifies the number of sub- and super-diagonals.
alpha – [in] specifies the scalar alpha.
A – [in] pointer storing matrix A on the GPU.
lda – [in] [rocblas_int] specifies the leading dimension of matrix A.
x – [in] pointer storing vector x on the GPU.
incx – [in] [rocblas_int] specifies the increment for the elements of x.
beta – [in] specifies the scalar beta.
y – [out] pointer storing vector y on the GPU.
incy – [in] [rocblas_int] specifies the increment for the elements of y.
-
rocblas_status rocblas_ssbmv_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, rocblas_int k, const float *alpha, const float *const A[], rocblas_int lda, const float *const x[], rocblas_int incx, const float *beta, float *const y[], rocblas_int incy, rocblas_int batch_count)#
-
rocblas_status rocblas_dsbmv_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, rocblas_int k, const double *alpha, const double *const A[], rocblas_int lda, const double *const x[], rocblas_int incx, const double *beta, double *const y[], rocblas_int incy, rocblas_int batch_count)#
BLAS Level 2 API
sbmv_batched performs the matrix-vector operation:
y_i := alpha*A_i*x_i + beta*y_i where (A_i, x_i, y_i) is the i-th instance of the batch. alpha and beta are scalars, x_i and y_i are vectors and A_i is an n by n symmetric banded matrix, for i = 1, ..., batch_count. A should contain an upper or lower triangular n by n symmetric banded matrix.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill] specifies whether the upper ‘rocblas_fill_upper’ or lower ‘rocblas_fill_lower’
if rocblas_fill_upper, the lower part of A is not referenced
if rocblas_fill_lower, the upper part of A is not referenced
n – [in] [rocblas_int] number of rows and columns of each matrix A_i.
k – [in] [rocblas_int] specifies the number of sub- and super-diagonals.
alpha – [in] device pointer or host pointer to scalar alpha.
A – [in] device array of device pointers storing each matrix A_i.
lda – [in] [rocblas_int] specifies the leading dimension of each matrix A_i.
x – [in] device array of device pointers storing each vector x_i.
incx – [in] [rocblas_int] specifies the increment for the elements of each vector x_i.
beta – [in] device pointer or host pointer to scalar beta.
y – [out] device array of device pointers storing each vector y_i.
incy – [in] [rocblas_int] specifies the increment for the elements of each vector y_i.
batch_count – [in] [rocblas_int] number of instances in the batch.
-
rocblas_status rocblas_ssbmv_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, rocblas_int k, const float *alpha, const float *A, rocblas_int lda, rocblas_stride strideA, const float *x, rocblas_int incx, rocblas_stride stridex, const float *beta, float *y, rocblas_int incy, rocblas_stride stridey, rocblas_int batch_count)#
-
rocblas_status rocblas_dsbmv_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, rocblas_int k, const double *alpha, const double *A, rocblas_int lda, rocblas_stride strideA, const double *x, rocblas_int incx, rocblas_stride stridex, const double *beta, double *y, rocblas_int incy, rocblas_stride stridey, rocblas_int batch_count)#
BLAS Level 2 API
sbmv_strided_batched performs the matrix-vector operation:
y_i := alpha*A_i*x_i + beta*y_i where (A_i, x_i, y_i) is the i-th instance of the batch. alpha and beta are scalars, x_i and y_i are vectors and A_i is an n by n symmetric banded matrix, for i = 1, ..., batch_count. A should contain an upper or lower triangular n by n symmetric banded matrix.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill] specifies whether the upper ‘rocblas_fill_upper’ or lower ‘rocblas_fill_lower’
if rocblas_fill_upper, the lower part of A is not referenced
if rocblas_fill_lower, the upper part of A is not referenced
n – [in] [rocblas_int] number of rows and columns of each matrix A_i.
k – [in] [rocblas_int] specifies the number of sub- and super-diagonals.
alpha – [in] device pointer or host pointer to scalar alpha.
A – [in] Device pointer to the first matrix A_1 on the GPU.
lda – [in] [rocblas_int] specifies the leading dimension of each matrix A_i.
strideA – [in] [rocblas_stride] stride from the start of one matrix (A_i) and the next one (A_i+1).
x – [in] Device pointer to the first vector x_1 on the GPU.
incx – [in] [rocblas_int] specifies the increment for the elements of each vector x_i.
stridex – [in] [rocblas_stride] stride from the start of one vector (x_i) and the next one (x_i+1). There are no restrictions placed on stridex. However, ensure that stridex is of appropriate size. This typically means stridex >= n * incx. stridex should be non zero.
beta – [in] device pointer or host pointer to scalar beta.
y – [out] Device pointer to the first vector y_1 on the GPU.
incy – [in] [rocblas_int] specifies the increment for the elements of each vector y_i.
stridey – [in] [rocblas_stride] stride from the start of one vector (y_i) and the next one (y_i+1). There are no restrictions placed on stridey. However, ensure that stridey is of appropriate size. This typically means stridey >= n * incy. stridey should be non zero.
batch_count – [in] [rocblas_int] number of instances in the batch.
rocblas_Xspmv + batched, strided_batched#
-
rocblas_status rocblas_sspmv(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const float *alpha, const float *A, const float *x, rocblas_int incx, const float *beta, float *y, rocblas_int incy)#
-
rocblas_status rocblas_dspmv(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const double *alpha, const double *A, const double *x, rocblas_int incx, const double *beta, double *y, rocblas_int incy)#
BLAS Level 2 API
spmv performs the matrix-vector operation:
y := alpha*A*x + beta*y where alpha and beta are scalars, x and y are n element vectors and A should contain an upper or lower triangular n by n packed symmetric matrix.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] rocblas_fill specifies whether the upper ‘rocblas_fill_upper’ or lower ‘rocblas_fill_lower’
if rocblas_fill_upper, the lower part of A is not referenced
if rocblas_fill_lower, the upper part of A is not referenced
n – [in] [rocblas_int]
alpha – [in] specifies the scalar alpha.
A – [in] pointer storing matrix A on the GPU.
x – [in] pointer storing vector x on the GPU.
incx – [in] [rocblas_int] specifies the increment for the elements of x.
beta – [in] specifies the scalar beta.
y – [out] pointer storing vector y on the GPU.
incy – [in] [rocblas_int] specifies the increment for the elements of y.
-
rocblas_status rocblas_sspmv_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const float *alpha, const float *const A[], const float *const x[], rocblas_int incx, const float *beta, float *const y[], rocblas_int incy, rocblas_int batch_count)#
-
rocblas_status rocblas_dspmv_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const double *alpha, const double *const A[], const double *const x[], rocblas_int incx, const double *beta, double *const y[], rocblas_int incy, rocblas_int batch_count)#
BLAS Level 2 API
spmv_batched performs the matrix-vector operation:
y_i := alpha*A_i*x_i + beta*y_i where (A_i, x_i, y_i) is the i-th instance of the batch. alpha and beta are scalars, x_i and y_i are vectors and A_i is an n by n symmetric matrix, for i = 1, ..., batch_count. A should contain an upper or lower triangular n by n packed symmetric matrix.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill] specifies whether the upper ‘rocblas_fill_upper’ or lower ‘rocblas_fill_lower’
if rocblas_fill_upper, the lower part of A is not referenced
if rocblas_fill_lower, the upper part of A is not referenced
n – [in] [rocblas_int] number of rows and columns of each matrix A_i.
alpha – [in] device pointer or host pointer to scalar alpha.
A – [in] device array of device pointers storing each matrix A_i.
x – [in] device array of device pointers storing each vector x_i.
incx – [in] [rocblas_int] specifies the increment for the elements of each vector x_i.
beta – [in] device pointer or host pointer to scalar beta.
y – [out] device array of device pointers storing each vector y_i.
incy – [in] [rocblas_int] specifies the increment for the elements of each vector y_i.
batch_count – [in] [rocblas_int] number of instances in the batch.
-
rocblas_status rocblas_sspmv_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const float *alpha, const float *A, rocblas_stride strideA, const float *x, rocblas_int incx, rocblas_stride stridex, const float *beta, float *y, rocblas_int incy, rocblas_stride stridey, rocblas_int batch_count)#
-
rocblas_status rocblas_dspmv_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const double *alpha, const double *A, rocblas_stride strideA, const double *x, rocblas_int incx, rocblas_stride stridex, const double *beta, double *y, rocblas_int incy, rocblas_stride stridey, rocblas_int batch_count)#
BLAS Level 2 API
spmv_strided_batched performs the matrix-vector operation:
y_i := alpha*A_i*x_i + beta*y_i where (A_i, x_i, y_i) is the i-th instance of the batch. alpha and beta are scalars, x_i and y_i are vectors and A_i is an n by n symmetric matrix, for i = 1, ..., batch_count. A should contain an upper or lower triangular n by n packed symmetric matrix.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill] specifies whether the upper ‘rocblas_fill_upper’ or lower ‘rocblas_fill_lower’
if rocblas_fill_upper, the lower part of A is not referenced
if rocblas_fill_lower, the upper part of A is not referenced
n – [in] [rocblas_int] number of rows and columns of each matrix A_i.
alpha – [in] device pointer or host pointer to scalar alpha.
A – [in] Device pointer to the first matrix A_1 on the GPU.
strideA – [in] [rocblas_stride] stride from the start of one matrix (A_i) and the next one (A_i+1).
x – [in] Device pointer to the first vector x_1 on the GPU.
incx – [in] [rocblas_int] specifies the increment for the elements of each vector x_i.
stridex – [in] [rocblas_stride] stride from the start of one vector (x_i) and the next one (x_i+1). There are no restrictions placed on stridex. However, ensure that stridex is of appropriate size. This typically means stridex >= n * incx. stridex should be non zero.
beta – [in] device pointer or host pointer to scalar beta.
y – [out] Device pointer to the first vector y_1 on the GPU.
incy – [in] [rocblas_int] specifies the increment for the elements of each vector y_i.
stridey – [in] [rocblas_stride] stride from the start of one vector (y_i) and the next one (y_i+1). There are no restrictions placed on stridey. However, ensure that stridey is of appropriate size. This typically means stridey >= n * incy. stridey should be non zero.
batch_count – [in] [rocblas_int] number of instances in the batch.
rocblas_Xspr + batched, strided_batched#
-
rocblas_status rocblas_sspr(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const float *alpha, const float *x, rocblas_int incx, float *AP)#
-
rocblas_status rocblas_dspr(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const double *alpha, const double *x, rocblas_int incx, double *AP)#
-
rocblas_status rocblas_cspr(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *x, rocblas_int incx, rocblas_float_complex *AP)#
-
rocblas_status rocblas_zspr(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *x, rocblas_int incx, rocblas_double_complex *AP)#
BLAS Level 2 API
spr performs the matrix-vector operations:
A := A + alpha*x*x**T where alpha is a scalar, x is a vector, and A is an n by n symmetric matrix, supplied in packed form.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill] specifies whether the upper ‘rocblas_fill_upper’ or lower ‘rocblas_fill_lower’
rocblas_fill_upper: The upper triangular part of A is supplied in AP.
rocblas_fill_lower: The lower triangular part of A is supplied in AP.
n – [in] [rocblas_int] the number of rows and columns of matrix A. Must be at least 0.
alpha – [in] device pointer or host pointer to scalar alpha.
x – [in] device pointer storing vector x.
incx – [in] [rocblas_int] specifies the increment for the elements of x.
AP – [inout] device pointer storing the packed version of the specified triangular portion of the symmetric matrix A. Of at least size ((n * (n + 1)) / 2).
if uplo == rocblas_fill_upper: The upper triangular portion of the symmetric matrix A is supplied. The matrix is compacted so that AP contains the triangular portion column-by-column so that: AP(0) = A(0,0) AP(1) = A(0,1) AP(2) = A(1,1), etc. Ex: (rocblas_fill_upper; n = 4) 1 2 4 7 2 3 5 8 -----> [1, 2, 3, 4, 5, 6, 7, 8, 9, 0] 4 5 6 9 7 8 9 0 if uplo == rocblas_fill_lower: The lower triangular portion of the symmetric matrix A is supplied. The matrix is compacted so that AP contains the triangular portion column-by-column so that: AP(0) = A(0,0) AP(1) = A(1,0) AP(2) = A(2,1), etc. Ex: (rocblas_fill_lower; n = 4) 1 2 3 4 2 5 6 7 -----> [1, 2, 3, 4, 5, 6, 7, 8, 9, 0] 3 6 8 9 4 7 9 0
-
rocblas_status rocblas_sspr_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const float *alpha, const float *const x[], rocblas_int incx, float *const AP[], rocblas_int batch_count)#
-
rocblas_status rocblas_dspr_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const double *alpha, const double *const x[], rocblas_int incx, double *const AP[], rocblas_int batch_count)#
-
rocblas_status rocblas_cspr_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *const x[], rocblas_int incx, rocblas_float_complex *const AP[], rocblas_int batch_count)#
-
rocblas_status rocblas_zspr_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *const x[], rocblas_int incx, rocblas_double_complex *const AP[], rocblas_int batch_count)#
BLAS Level 2 API
spr_batched performs the matrix-vector operations:
A_i := A_i + alpha*x_i*x_i**T where alpha is a scalar, x_i is a vector, and A_i is an n by n symmetric matrix, supplied in packed form, for i = 1, ..., batch_count.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill] specifies whether the upper ‘rocblas_fill_upper’ or lower ‘rocblas_fill_lower’
rocblas_fill_upper: The upper triangular part of each A_i is supplied in AP.
rocblas_fill_lower: The lower triangular part of each A_i is supplied in AP.
n – [in] [rocblas_int] the number of rows and columns of each matrix A_i. Must be at least 0.
alpha – [in] device pointer or host pointer to scalar alpha.
x – [in] device array of device pointers storing each vector x_i.
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i.
AP – [inout] device array of device pointers storing the packed version of the specified triangular portion of each symmetric matrix A_i of at least size ((n * (n + 1)) / 2). Array is of at least size batch_count.
if uplo == rocblas_fill_upper: The upper triangular portion of each symmetric matrix A_i is supplied. The matrix is compacted so that AP contains the triangular portion column-by-column so that: AP(0) = A(0,0) AP(1) = A(0,1) AP(2) = A(1,1), etc. Ex: (rocblas_fill_upper; n = 4) 1 2 4 7 2 3 5 8 -----> [1, 2, 3, 4, 5, 6, 7, 8, 9, 0] 4 5 6 9 7 8 9 0 if uplo == rocblas_fill_lower: The lower triangular portion of each symmetric matrix A_i is supplied. The matrix is compacted so that AP contains the triangular portion column-by-column so that: AP(0) = A(0,0) AP(1) = A(1,0) AP(2) = A(2,1), etc. Ex: (rocblas_fill_lower; n = 4) 1 2 3 4 2 5 6 7 -----> [1, 2, 3, 4, 5, 6, 7, 8, 9, 0] 3 6 8 9 4 7 9 0
batch_count – [in] [rocblas_int] number of instances in the batch.
-
rocblas_status rocblas_sspr_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const float *alpha, const float *x, rocblas_int incx, rocblas_stride stride_x, float *AP, rocblas_stride stride_A, rocblas_int batch_count)#
-
rocblas_status rocblas_dspr_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const double *alpha, const double *x, rocblas_int incx, rocblas_stride stride_x, double *AP, rocblas_stride stride_A, rocblas_int batch_count)#
-
rocblas_status rocblas_cspr_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *x, rocblas_int incx, rocblas_stride stride_x, rocblas_float_complex *AP, rocblas_stride stride_A, rocblas_int batch_count)#
-
rocblas_status rocblas_zspr_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *x, rocblas_int incx, rocblas_stride stride_x, rocblas_double_complex *AP, rocblas_stride stride_A, rocblas_int batch_count)#
BLAS Level 2 API
spr_strided_batched performs the matrix-vector operations:
A_i := A_i + alpha*x_i*x_i**T where alpha is a scalar, x_i is a vector, and A_i is an n by n symmetric matrix, supplied in packed form, for i = 1, ..., batch_count.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill] specifies whether the upper ‘rocblas_fill_upper’ or lower ‘rocblas_fill_lower’
rocblas_fill_upper: The upper triangular part of each A_i is supplied in AP.
rocblas_fill_lower: The lower triangular part of each A_i is supplied in AP.
n – [in] [rocblas_int] the number of rows and columns of each matrix A_i. Must be at least 0.
alpha – [in] device pointer or host pointer to scalar alpha.
x – [in] device pointer pointing to the first vector (x_1).
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i.
stride_x – [in] [rocblas_stride] stride from the start of one vector (x_i) and the next one (x_i+1).
AP – [inout] device pointer storing the packed version of the specified triangular portion of each symmetric matrix A_i. Points to the first A_1.
if uplo == rocblas_fill_upper: The upper triangular portion of each symmetric matrix A_i is supplied. The matrix is compacted so that AP contains the triangular portion column-by-column so that: AP(0) = A(0,0) AP(1) = A(0,1) AP(2) = A(1,1), etc. Ex: (rocblas_fill_upper; n = 4) 1 2 4 7 2 3 5 8 -----> [1, 2, 3, 4, 5, 6, 7, 8, 9, 0] 4 5 6 9 7 8 9 0 if uplo == rocblas_fill_lower: The lower triangular portion of each symmetric matrix A_i is supplied. The matrix is compacted so that AP contains the triangular portion column-by-column so that: AP(0) = A(0,0) AP(1) = A(1,0) AP(2) = A(2,1), etc. Ex: (rocblas_fill_lower; n = 4) 1 2 3 4 2 5 6 7 -----> [1, 2, 3, 4, 5, 6, 7, 8, 9, 0] 3 6 8 9 4 7 9 0
stride_A – [in] [rocblas_stride] stride from the start of one (A_i) and the next (A_i+1).
batch_count – [in] [rocblas_int] number of instances in the batch.
rocblas_Xspr2 + batched, strided_batched#
-
rocblas_status rocblas_sspr2(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const float *alpha, const float *x, rocblas_int incx, const float *y, rocblas_int incy, float *AP)#
-
rocblas_status rocblas_dspr2(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const double *alpha, const double *x, rocblas_int incx, const double *y, rocblas_int incy, double *AP)#
BLAS Level 2 API
spr2 performs the matrix-vector operation:
A := A + alpha*x*y**T + alpha*y*x**T where alpha is a scalar, x and y are vectors, and A is an n by n symmetric matrix, supplied in packed form.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill] specifies whether the upper ‘rocblas_fill_upper’ or lower ‘rocblas_fill_lower’
rocblas_fill_upper: The upper triangular part of A is supplied in AP.
rocblas_fill_lower: The lower triangular part of A is supplied in AP.
n – [in] [rocblas_int] the number of rows and columns of matrix A. Must be at least 0.
alpha – [in] device pointer or host pointer to scalar alpha.
x – [in] device pointer storing vector x.
incx – [in] [rocblas_int] specifies the increment for the elements of x.
y – [in] device pointer storing vector y.
incy – [in] [rocblas_int] specifies the increment for the elements of y.
AP – [inout] device pointer storing the packed version of the specified triangular portion of the symmetric matrix A. Of at least size ((n * (n + 1)) / 2).
if uplo == rocblas_fill_upper: The upper triangular portion of the symmetric matrix A is supplied. The matrix is compacted so that AP contains the triangular portion column-by-column so that: AP(0) = A(0,0) AP(1) = A(0,1) AP(2) = A(1,1), etc. Ex: (rocblas_fill_upper; n = 4) 1 2 4 7 2 3 5 8 -----> [1, 2, 3, 4, 5, 6, 7, 8, 9, 0] 4 5 6 9 7 8 9 0 if uplo == rocblas_fill_lower: The lower triangular portion of the symmetric matrix A is supplied. The matrix is compacted so that AP contains the triangular portion column-by-column so that: AP(0) = A(0,0) AP(1) = A(1,0) AP(n) = A(2,1), etc. Ex: (rocblas_fill_lower; n = 4) 1 2 3 4 2 5 6 7 -----> [1, 2, 3, 4, 5, 6, 7, 8, 9, 0] 3 6 8 9 4 7 9 0
-
rocblas_status rocblas_sspr2_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const float *alpha, const float *const x[], rocblas_int incx, const float *const y[], rocblas_int incy, float *const AP[], rocblas_int batch_count)#
-
rocblas_status rocblas_dspr2_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const double *alpha, const double *const x[], rocblas_int incx, const double *const y[], rocblas_int incy, double *const AP[], rocblas_int batch_count)#
BLAS Level 2 API
spr2_batched performs the matrix-vector operation:
A_i := A_i + alpha*x_i*y_i**T + alpha*y_i*x_i**T where alpha is a scalar, x_i and y_i are vectors, and A_i is an n by n symmetric matrix, supplied in packed form, for i = 1, ..., batch_count.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill] specifies whether the upper ‘rocblas_fill_upper’ or lower ‘rocblas_fill_lower’
rocblas_fill_upper: The upper triangular part of each A_i is supplied in AP.
rocblas_fill_lower: The lower triangular part of each A_i is supplied in AP.
n – [in] [rocblas_int] the number of rows and columns of each matrix A_i. Must be at least 0.
alpha – [in] device pointer or host pointer to scalar alpha.
x – [in] device array of device pointers storing each vector x_i.
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i.
y – [in] device array of device pointers storing each vector y_i.
incy – [in] [rocblas_int] specifies the increment for the elements of each y_i.
AP – [inout] device array of device pointers storing the packed version of the specified triangular portion of each symmetric matrix A_i of at least size ((n * (n + 1)) / 2). Array is of at least size batch_count.
if uplo == rocblas_fill_upper: The upper triangular portion of each symmetric matrix A_i is supplied. The matrix is compacted so that AP contains the triangular portion column-by-column so that: AP(0) = A(0,0) AP(1) = A(0,1) AP(2) = A(1,1), etc. Ex: (rocblas_fill_upper; n = 4) 1 2 4 7 2 3 5 8 -----> [1, 2, 3, 4, 5, 6, 7, 8, 9, 0] 4 5 6 9 7 8 9 0 if uplo == rocblas_fill_lower: The lower triangular portion of each symmetric matrix A_i is supplied. The matrix is compacted so that AP contains the triangular portion column-by-column so that: AP(0) = A(0,0) AP(1) = A(1,0) AP(n) = A(2,1), etc. Ex: (rocblas_fill_lower; n = 4) 1 2 3 4 2 5 6 7 -----> [1, 2, 3, 4, 5, 6, 7, 8, 9, 0] 3 6 8 9 4 7 9 0
batch_count – [in] [rocblas_int] number of instances in the batch.
-
rocblas_status rocblas_sspr2_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const float *alpha, const float *x, rocblas_int incx, rocblas_stride stride_x, const float *y, rocblas_int incy, rocblas_stride stride_y, float *AP, rocblas_stride stride_A, rocblas_int batch_count)#
-
rocblas_status rocblas_dspr2_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const double *alpha, const double *x, rocblas_int incx, rocblas_stride stride_x, const double *y, rocblas_int incy, rocblas_stride stride_y, double *AP, rocblas_stride stride_A, rocblas_int batch_count)#
BLAS Level 2 API
spr2_strided_batched performs the matrix-vector operation:
A_i := A_i + alpha*x_i*y_i**T + alpha*y_i*x_i**T where alpha is a scalar, x_i and y_i are vectors, and A_i is an n by n symmetric matrix, supplied in packed form, for i = 1, ..., batch_count.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill] specifies whether the upper ‘rocblas_fill_upper’ or lower ‘rocblas_fill_lower’
rocblas_fill_upper: The upper triangular part of each A_i is supplied in AP.
rocblas_fill_lower: The lower triangular part of each A_i is supplied in AP.
n – [in] [rocblas_int] the number of rows and columns of each matrix A_i. Must be at least 0.
alpha – [in] device pointer or host pointer to scalar alpha.
x – [in] device pointer pointing to the first vector (x_1).
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i.
stride_x – [in] [rocblas_stride] stride from the start of one vector (x_i) and the next one (x_i+1).
y – [in] device pointer pointing to the first vector (y_1).
incy – [in] [rocblas_int] specifies the increment for the elements of each y_i.
stride_y – [in] [rocblas_stride] stride from the start of one vector (y_i) and the next one (y_i+1).
AP – [inout] device pointer storing the packed version of the specified triangular portion of each symmetric matrix A_i. Points to the first A_1.
if uplo == rocblas_fill_upper: The upper triangular portion of each symmetric matrix A_i is supplied. The matrix is compacted so that AP contains the triangular portion column-by-column so that: AP(0) = A(0,0) AP(1) = A(0,1) AP(2) = A(1,1), etc. Ex: (rocblas_fill_upper; n = 4) 1 2 4 7 2 3 5 8 -----> [1, 2, 3, 4, 5, 6, 7, 8, 9, 0] 4 5 6 9 7 8 9 0 if uplo == rocblas_fill_lower: The lower triangular portion of each symmetric matrix A_i is supplied. The matrix is compacted so that AP contains the triangular portion column-by-column so that: AP(0) = A(0,0) AP(1) = A(1,0) AP(n) = A(2,1), etc. Ex: (rocblas_fill_lower; n = 4) 1 2 3 4 2 5 6 7 -----> [1, 2, 3, 4, 5, 6, 7, 8, 9, 0] 3 6 8 9 4 7 9 0
stride_A – [in] [rocblas_stride] stride from the start of one (A_i) and the next (A_i+1).
batch_count – [in] [rocblas_int] number of instances in the batch.
rocblas_Xsymv + batched, strided_batched#
-
rocblas_status rocblas_ssymv(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const float *alpha, const float *A, rocblas_int lda, const float *x, rocblas_int incx, const float *beta, float *y, rocblas_int incy)#
-
rocblas_status rocblas_dsymv(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const double *alpha, const double *A, rocblas_int lda, const double *x, rocblas_int incx, const double *beta, double *y, rocblas_int incy)#
-
rocblas_status rocblas_csymv(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *A, rocblas_int lda, const rocblas_float_complex *x, rocblas_int incx, const rocblas_float_complex *beta, rocblas_float_complex *y, rocblas_int incy)#
-
rocblas_status rocblas_zsymv(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *A, rocblas_int lda, const rocblas_double_complex *x, rocblas_int incx, const rocblas_double_complex *beta, rocblas_double_complex *y, rocblas_int incy)#
BLAS Level 2 API
symv performs the matrix-vector operation:
y := alpha*A*x + beta*y where alpha and beta are scalars, x and y are n element vectors and A should contain an upper or lower triangular n by n symmetric matrix.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill] specifies whether the upper ‘rocblas_fill_upper’ or lower ‘rocblas_fill_lower’
if rocblas_fill_upper, the lower part of A is not referenced.
if rocblas_fill_lower, the upper part of A is not referenced.
n – [in] [rocblas_int]
alpha – [in] specifies the scalar alpha.
A – [in] pointer storing matrix A on the GPU
lda – [in] [rocblas_int] specifies the leading dimension of A.
x – [in] pointer storing vector x on the GPU.
incx – [in] [rocblas_int] specifies the increment for the elements of x.
beta – [in] specifies the scalar beta
y – [out] pointer storing vector y on the GPU.
incy – [in] [rocblas_int] specifies the increment for the elements of y.
-
rocblas_status rocblas_ssymv_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const float *alpha, const float *const A[], rocblas_int lda, const float *const x[], rocblas_int incx, const float *beta, float *const y[], rocblas_int incy, rocblas_int batch_count)#
-
rocblas_status rocblas_dsymv_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const double *alpha, const double *const A[], rocblas_int lda, const double *const x[], rocblas_int incx, const double *beta, double *const y[], rocblas_int incy, rocblas_int batch_count)#
-
rocblas_status rocblas_csymv_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *const A[], rocblas_int lda, const rocblas_float_complex *const x[], rocblas_int incx, const rocblas_float_complex *beta, rocblas_float_complex *const y[], rocblas_int incy, rocblas_int batch_count)#
-
rocblas_status rocblas_zsymv_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *const A[], rocblas_int lda, const rocblas_double_complex *const x[], rocblas_int incx, const rocblas_double_complex *beta, rocblas_double_complex *const y[], rocblas_int incy, rocblas_int batch_count)#
BLAS Level 2 API
symv_batched performs the matrix-vector operation:
y_i := alpha*A_i*x_i + beta*y_i where (A_i, x_i, y_i) is the i-th instance of the batch. alpha and beta are scalars, x_i and y_i are vectors and A_i is an n by n symmetric matrix, for i = 1, ..., batch_count. A a should contain an upper or lower triangular symmetric matrix and the opposing triangular part of A is not referenced.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue
uplo – [in] [rocblas_fill] specifies whether the upper ‘rocblas_fill_upper’ or lower ‘rocblas_fill_lower’
if rocblas_fill_upper, the lower part of A is not referenced.
if rocblas_fill_lower, the upper part of A is not referenced.
n – [in] [rocblas_int] number of rows and columns of each matrix A_i.
alpha – [in] device pointer or host pointer to scalar alpha.
A – [in] device array of device pointers storing each matrix A_i.
lda – [in] [rocblas_int] specifies the leading dimension of each matrix A_i.
x – [in] device array of device pointers storing each vector x_i.
incx – [in] [rocblas_int] specifies the increment for the elements of each vector x_i.
beta – [in] device pointer or host pointer to scalar beta.
y – [out] device array of device pointers storing each vector y_i.
incy – [in] [rocblas_int] specifies the increment for the elements of each vector y_i.
batch_count – [in] [rocblas_int] number of instances in the batch.
-
rocblas_status rocblas_ssymv_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const float *alpha, const float *A, rocblas_int lda, rocblas_stride strideA, const float *x, rocblas_int incx, rocblas_stride stridex, const float *beta, float *y, rocblas_int incy, rocblas_stride stridey, rocblas_int batch_count)#
-
rocblas_status rocblas_dsymv_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const double *alpha, const double *A, rocblas_int lda, rocblas_stride strideA, const double *x, rocblas_int incx, rocblas_stride stridex, const double *beta, double *y, rocblas_int incy, rocblas_stride stridey, rocblas_int batch_count)#
-
rocblas_status rocblas_csymv_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *A, rocblas_int lda, rocblas_stride strideA, const rocblas_float_complex *x, rocblas_int incx, rocblas_stride stridex, const rocblas_float_complex *beta, rocblas_float_complex *y, rocblas_int incy, rocblas_stride stridey, rocblas_int batch_count)#
-
rocblas_status rocblas_zsymv_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *A, rocblas_int lda, rocblas_stride strideA, const rocblas_double_complex *x, rocblas_int incx, rocblas_stride stridex, const rocblas_double_complex *beta, rocblas_double_complex *y, rocblas_int incy, rocblas_stride stridey, rocblas_int batch_count)#
BLAS Level 2 API
symv_strided_batched performs the matrix-vector operation:
y_i := alpha*A_i*x_i + beta*y_i where (A_i, x_i, y_i) is the i-th instance of the batch. alpha and beta are scalars, x_i and y_i are vectors and A_i is an n by n symmetric matrix, for i = 1, ..., batch_count. A a should contain an upper or lower triangular symmetric matrix and the opposing triangular part of A is not referenced.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue
uplo – [in] [rocblas_fill] specifies whether the upper ‘rocblas_fill_upper’ or lower ‘rocblas_fill_lower’
if rocblas_fill_upper, the lower part of A is not referenced
if rocblas_fill_lower, the upper part of A is not referenced
n – [in] [rocblas_int] number of rows and columns of each matrix A_i.
alpha – [in] device pointer or host pointer to scalar alpha.
A – [in] Device pointer to the first matrix A_1 on the GPU.
lda – [in] [rocblas_int] specifies the leading dimension of each matrix A_i.
strideA – [in] [rocblas_stride] stride from the start of one matrix (A_i) and the next one (A_i+1).
x – [in] Device pointer to the first vector x_1 on the GPU.
incx – [in] [rocblas_int] specifies the increment for the elements of each vector x_i.
stridex – [in] [rocblas_stride] stride from the start of one vector (x_i) and the next one (x_i+1). There are no restrictions placed on stride_x. However, ensure that stridex is of appropriate size. This typically means stridex >= n * incx. stridex should be non zero.
beta – [in] device pointer or host pointer to scalar beta.
y – [out] Device pointer to the first vector y_1 on the GPU.
incy – [in] [rocblas_int] specifies the increment for the elements of each vector y_i.
stridey – [in] [rocblas_stride] stride from the start of one vector (y_i) and the next one (y_i+1). There are no restrictions placed on stride_y. However, ensure that stridey is of appropriate size. This typically means stridey >= n * incy. stridey should be non zero.
batch_count – [in] [rocblas_int] number of instances in the batch.
rocblas_Xsyr + batched, strided_batched#
-
rocblas_status rocblas_ssyr(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const float *alpha, const float *x, rocblas_int incx, float *A, rocblas_int lda)#
-
rocblas_status rocblas_dsyr(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const double *alpha, const double *x, rocblas_int incx, double *A, rocblas_int lda)#
-
rocblas_status rocblas_csyr(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *x, rocblas_int incx, rocblas_float_complex *A, rocblas_int lda)#
-
rocblas_status rocblas_zsyr(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *x, rocblas_int incx, rocblas_double_complex *A, rocblas_int lda)#
BLAS Level 2 API
syr performs the matrix-vector operations:
A := A + alpha*x*x**T where alpha is a scalar, x is a vector, and A is an n by n symmetric matrix.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill] specifies whether the upper ‘rocblas_fill_upper’ or lower ‘rocblas_fill_lower’
if rocblas_fill_upper, the lower part of A is not referenced
if rocblas_fill_lower, the upper part of A is not referenced
n – [in] [rocblas_int] the number of rows and columns of matrix A.
alpha – [in] device pointer or host pointer to scalar alpha.
x – [in] device pointer storing vector x.
incx – [in] [rocblas_int] specifies the increment for the elements of x.
A – [inout] device pointer storing matrix A.
lda – [in] [rocblas_int] specifies the leading dimension of A.
-
rocblas_status rocblas_ssyr_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const float *alpha, const float *const x[], rocblas_int incx, float *const A[], rocblas_int lda, rocblas_int batch_count)#
-
rocblas_status rocblas_dsyr_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const double *alpha, const double *const x[], rocblas_int incx, double *const A[], rocblas_int lda, rocblas_int batch_count)#
-
rocblas_status rocblas_csyr_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *const x[], rocblas_int incx, rocblas_float_complex *const A[], rocblas_int lda, rocblas_int batch_count)#
-
rocblas_status rocblas_zsyr_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *const x[], rocblas_int incx, rocblas_double_complex *const A[], rocblas_int lda, rocblas_int batch_count)#
BLAS Level 2 API
syr_batched performs a batch of matrix-vector operations:
A[i] := A[i] + alpha*x[i]*x[i]**T where alpha is a scalar, x is an array of vectors, and A is an array of n by n symmetric matrices, for i = 1 , ... , batch_count.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill] specifies whether the upper ‘rocblas_fill_upper’ or lower ‘rocblas_fill_lower’
if rocblas_fill_upper, the lower part of A is not referenced
if rocblas_fill_lower, the upper part of A is not referenced
n – [in] [rocblas_int] the number of rows and columns of matrix A.
alpha – [in] device pointer or host pointer to scalar alpha.
x – [in] device array of device pointers storing each vector x_i.
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i.
A – [inout] device array of device pointers storing each matrix A_i.
lda – [in] [rocblas_int] specifies the leading dimension of each A_i.
batch_count – [in] [rocblas_int] number of instances in the batch.
-
rocblas_status rocblas_ssyr_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const float *alpha, const float *x, rocblas_int incx, rocblas_stride stridex, float *A, rocblas_int lda, rocblas_stride strideA, rocblas_int batch_count)#
-
rocblas_status rocblas_dsyr_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const double *alpha, const double *x, rocblas_int incx, rocblas_stride stridex, double *A, rocblas_int lda, rocblas_stride strideA, rocblas_int batch_count)#
-
rocblas_status rocblas_csyr_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *x, rocblas_int incx, rocblas_stride stridex, rocblas_float_complex *A, rocblas_int lda, rocblas_stride strideA, rocblas_int batch_count)#
-
rocblas_status rocblas_zsyr_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *x, rocblas_int incx, rocblas_stride stridex, rocblas_double_complex *A, rocblas_int lda, rocblas_stride strideA, rocblas_int batch_count)#
BLAS Level 2 API
syr_strided_batched performs the matrix-vector operations:
A[i] := A[i] + alpha*x[i]*x[i]**T where alpha is a scalar, vectors, and A is an array of n by n symmetric matrices, for i = 1 , ... , batch_count.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill] specifies whether the upper ‘rocblas_fill_upper’ or lower ‘rocblas_fill_lower’
if rocblas_fill_upper, the lower part of A is not referenced
if rocblas_fill_lower, the upper part of A is not referenced
n – [in] [rocblas_int] the number of rows and columns of each matrix A.
alpha – [in] device pointer or host pointer to scalar alpha.
x – [in] device pointer to the first vector x_1.
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i.
stridex – [in] [rocblas_stride] specifies the pointer increment between vectors (x_i) and (x_i+1).
A – [inout] device pointer to the first matrix A_1.
lda – [in] [rocblas_int] specifies the leading dimension of each A_i.
strideA – [in] [rocblas_stride] stride from the start of one matrix (A_i) and the next one (A_i+1).
batch_count – [in] [rocblas_int] number of instances in the batch.
rocblas_Xsyr2 + batched, strided_batched#
-
rocblas_status rocblas_ssyr2(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const float *alpha, const float *x, rocblas_int incx, const float *y, rocblas_int incy, float *A, rocblas_int lda)#
-
rocblas_status rocblas_dsyr2(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const double *alpha, const double *x, rocblas_int incx, const double *y, rocblas_int incy, double *A, rocblas_int lda)#
-
rocblas_status rocblas_csyr2(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *x, rocblas_int incx, const rocblas_float_complex *y, rocblas_int incy, rocblas_float_complex *A, rocblas_int lda)#
-
rocblas_status rocblas_zsyr2(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *x, rocblas_int incx, const rocblas_double_complex *y, rocblas_int incy, rocblas_double_complex *A, rocblas_int lda)#
BLAS Level 2 API
syr2 performs the matrix-vector operations:
A := A + alpha*x*y**T + alpha*y*x**T where alpha is a scalar, x and y are vectors, and A is an n by n symmetric matrix.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill] specifies whether the upper ‘rocblas_fill_upper’ or lower ‘rocblas_fill_lower’
if rocblas_fill_upper, the lower part of A is not referenced
if rocblas_fill_lower, the upper part of A is not referenced
n – [in] [rocblas_int] the number of rows and columns of matrix A.
alpha – [in] device pointer or host pointer to scalar alpha.
x – [in] device pointer storing vector x.
incx – [in] [rocblas_int] specifies the increment for the elements of x.
y – [in] device pointer storing vector y.
incy – [in] [rocblas_int] specifies the increment for the elements of y.
A – [inout] device pointer storing matrix A.
lda – [in] [rocblas_int] specifies the leading dimension of A.
-
rocblas_status rocblas_ssyr2_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const float *alpha, const float *const x[], rocblas_int incx, const float *const y[], rocblas_int incy, float *const A[], rocblas_int lda, rocblas_int batch_count)#
-
rocblas_status rocblas_dsyr2_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const double *alpha, const double *const x[], rocblas_int incx, const double *const y[], rocblas_int incy, double *const A[], rocblas_int lda, rocblas_int batch_count)#
-
rocblas_status rocblas_csyr2_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *const x[], rocblas_int incx, const rocblas_float_complex *const y[], rocblas_int incy, rocblas_float_complex *const A[], rocblas_int lda, rocblas_int batch_count)#
-
rocblas_status rocblas_zsyr2_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *const x[], rocblas_int incx, const rocblas_double_complex *const y[], rocblas_int incy, rocblas_double_complex *const A[], rocblas_int lda, rocblas_int batch_count)#
BLAS Level 2 API
syr2_batched performs a batch of matrix-vector operations:
A[i] := A[i] + alpha*x[i]*y[i]**T + alpha*y[i]*x[i]**T where alpha is a scalar, x[i] and y[i] are vectors, and A[i] is a n by n symmetric matrix, for i = 1 , ... , batch_count.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill] specifies whether the upper ‘rocblas_fill_upper’ or lower ‘rocblas_fill_lower’
if rocblas_fill_upper, the lower part of A is not referenced
if rocblas_fill_lower, the upper part of A is not referenced
n – [in] [rocblas_int] the number of rows and columns of matrix A.
alpha – [in] device pointer or host pointer to scalar alpha.
x – [in] device array of device pointers storing each vector x_i.
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i.
y – [in] device array of device pointers storing each vector y_i.
incy – [in] [rocblas_int] specifies the increment for the elements of each y_i.
A – [inout] device array of device pointers storing each matrix A_i.
lda – [in] [rocblas_int] specifies the leading dimension of each A_i.
batch_count – [in] [rocblas_int] number of instances in the batch.
-
rocblas_status rocblas_ssyr2_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const float *alpha, const float *x, rocblas_int incx, rocblas_stride stridex, const float *y, rocblas_int incy, rocblas_stride stridey, float *A, rocblas_int lda, rocblas_stride strideA, rocblas_int batch_count)#
-
rocblas_status rocblas_dsyr2_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const double *alpha, const double *x, rocblas_int incx, rocblas_stride stridex, const double *y, rocblas_int incy, rocblas_stride stridey, double *A, rocblas_int lda, rocblas_stride strideA, rocblas_int batch_count)#
-
rocblas_status rocblas_csyr2_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *x, rocblas_int incx, rocblas_stride stridex, const rocblas_float_complex *y, rocblas_int incy, rocblas_stride stridey, rocblas_float_complex *A, rocblas_int lda, rocblas_stride strideA, rocblas_int batch_count)#
-
rocblas_status rocblas_zsyr2_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *x, rocblas_int incx, rocblas_stride stridex, const rocblas_double_complex *y, rocblas_int incy, rocblas_stride stridey, rocblas_double_complex *A, rocblas_int lda, rocblas_stride strideA, rocblas_int batch_count)#
BLAS Level 2 API
syr2_strided_batched the matrix-vector operations:
A[i] := A[i] + alpha*x[i]*y[i]**T + alpha*y[i]*x[i]**T where alpha is a scalar, x[i] and y[i] are vectors, and A[i] is a n by n symmetric matrices, for i = 1 , ... , batch_count
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill] specifies whether the upper ‘rocblas_fill_upper’ or lower ‘rocblas_fill_lower’
if rocblas_fill_upper, the lower part of A is not referenced
if rocblas_fill_lower, the upper part of A is not referenced
n – [in] [rocblas_int] the number of rows and columns of each matrix A.
alpha – [in] device pointer or host pointer to scalar alpha.
x – [in] device pointer to the first vector x_1.
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i.
stridex – [in] [rocblas_stride] specifies the pointer increment between vectors (x_i) and (x_i+1).
y – [in] device pointer to the first vector y_1.
incy – [in] [rocblas_int] specifies the increment for the elements of each y_i.
stridey – [in] [rocblas_stride] specifies the pointer increment between vectors (y_i) and (y_i+1).
A – [inout] device pointer to the first matrix A_1.
lda – [in] [rocblas_int] specifies the leading dimension of each A_i.
strideA – [in] [rocblas_stride] stride from the start of one matrix (A_i) and the next one (A_i+1).
batch_count – [in] [rocblas_int] number of instances in the batch.
rocblas_Xtbmv + batched, strided_batched#
-
rocblas_status rocblas_stbmv(rocblas_handle handle, rocblas_fill uplo, rocblas_operation trans, rocblas_diagonal diag, rocblas_int m, rocblas_int k, const float *A, rocblas_int lda, float *x, rocblas_int incx)#
-
rocblas_status rocblas_dtbmv(rocblas_handle handle, rocblas_fill uplo, rocblas_operation trans, rocblas_diagonal diag, rocblas_int m, rocblas_int k, const double *A, rocblas_int lda, double *x, rocblas_int incx)#
-
rocblas_status rocblas_ctbmv(rocblas_handle handle, rocblas_fill uplo, rocblas_operation trans, rocblas_diagonal diag, rocblas_int m, rocblas_int k, const rocblas_float_complex *A, rocblas_int lda, rocblas_float_complex *x, rocblas_int incx)#
-
rocblas_status rocblas_ztbmv(rocblas_handle handle, rocblas_fill uplo, rocblas_operation trans, rocblas_diagonal diag, rocblas_int m, rocblas_int k, const rocblas_double_complex *A, rocblas_int lda, rocblas_double_complex *x, rocblas_int incx)#
BLAS Level 2 API
tbmv performs one of the matrix-vector operations:
x := A*x or x := A**T*x or x := A**H*x, x is a vectors and A is a banded m by m matrix (see description below).
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill]
rocblas_fill_upper: A is an upper banded triangular matrix.
rocblas_fill_lower: A is a lower banded triangular matrix.
trans – [in] [rocblas_operation] indicates whether matrix A is tranposed (conjugated) or not.
diag – [in] [rocblas_diagonal]
rocblas_diagonal_unit: The main diagonal of A is assumed to consist of only 1’s and is not referenced.
rocblas_diagonal_non_unit: No assumptions are made of A’s main diagonal.
m – [in] [rocblas_int] the number of rows and columns of the matrix represented by A.
k – [in] [rocblas_int]
if uplo == rocblas_fill_upper, k specifies the number of super-diagonals of the matrix A. if uplo == rocblas_fill_lower, k specifies the number of sub-diagonals of the matrix A. k must satisfy k > 0 && k < lda.
A – [in] device pointer storing banded triangular matrix A.
if uplo == rocblas_fill_upper: The matrix represented is an upper banded triangular matrix with the main diagonal and k super-diagonals, everything else can be assumed to be 0. The matrix is compacted so that the main diagonal resides on the k'th row, the first super diagonal resides on the RHS of the k-1'th row, etc, with the k'th diagonal on the RHS of the 0'th row. Ex: (rocblas_fill_upper; m = 5; k = 2) 1 6 9 0 0 0 0 9 8 7 0 2 7 8 0 0 6 7 8 9 0 0 3 8 7 ----> 1 2 3 4 5 0 0 0 4 9 0 0 0 0 0 0 0 0 0 5 0 0 0 0 0 if uplo == rocblas_fill_lower: The matrix represnted is a lower banded triangular matrix with the main diagonal and k sub-diagonals, everything else can be assumed to be 0. The matrix is compacted so that the main diagonal resides on the 0'th row, working up to the k'th diagonal residing on the LHS of the k'th row. Ex: (rocblas_fill_lower; m = 5; k = 2) 1 0 0 0 0 1 2 3 4 5 6 2 0 0 0 6 7 8 9 0 9 7 3 0 0 ----> 9 8 7 0 0 0 8 8 4 0 0 0 0 0 0 0 0 7 9 5 0 0 0 0 0
lda – [in] [rocblas_int] specifies the leading dimension of A. lda must satisfy lda > k.
x – [inout] device pointer storing vector x.
incx – [in] [rocblas_int] specifies the increment for the elements of x.
-
rocblas_status rocblas_stbmv_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation trans, rocblas_diagonal diag, rocblas_int m, rocblas_int k, const float *const A[], rocblas_int lda, float *const x[], rocblas_int incx, rocblas_int batch_count)#
-
rocblas_status rocblas_dtbmv_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation trans, rocblas_diagonal diag, rocblas_int m, rocblas_int k, const double *const A[], rocblas_int lda, double *const x[], rocblas_int incx, rocblas_int batch_count)#
-
rocblas_status rocblas_ctbmv_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation trans, rocblas_diagonal diag, rocblas_int m, rocblas_int k, const rocblas_float_complex *const A[], rocblas_int lda, rocblas_float_complex *const x[], rocblas_int incx, rocblas_int batch_count)#
-
rocblas_status rocblas_ztbmv_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation trans, rocblas_diagonal diag, rocblas_int m, rocblas_int k, const rocblas_double_complex *const A[], rocblas_int lda, rocblas_double_complex *const x[], rocblas_int incx, rocblas_int batch_count)#
BLAS Level 2 API
tbmv_batched performs one of the matrix-vector operations:
x_i := A_i*x_i or x_i := A_i**T*x_i or x_i := A_i**H*x_i, where (A_i, x_i) is the i-th instance of the batch. x_i is a vector and A_i is an m by m matrix, for i = 1, ..., batch_count.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill]
rocblas_fill_upper: each A_i is an upper banded triangular matrix.
rocblas_fill_lower: each A_i is a lower banded triangular matrix.
trans – [in] [rocblas_operation] indicates whether each matrix A_i is tranposed (conjugated) or not.
diag – [in] [rocblas_diagonal]
rocblas_diagonal_unit: The main diagonal of each A_i is assumed to consist of only 1’s and is not referenced.
rocblas_diagonal_non_unit: No assumptions are made of each A_i’s main diagonal.
m – [in] [rocblas_int] the number of rows and columns of the matrix represented by each A_i.
k – [in] [rocblas_int]
if uplo == rocblas_fill_upper, k specifies the number of super-diagonals of each matrix A_i. if uplo == rocblas_fill_lower, k specifies the number of sub-diagonals of each matrix A_i. k must satisfy k > 0 && k < lda.
A – [in] device array of device pointers storing each banded triangular matrix A_i.
if uplo == rocblas_fill_upper: The matrix represented is an upper banded triangular matrix with the main diagonal and k super-diagonals, everything else can be assumed to be 0. The matrix is compacted so that the main diagonal resides on the k'th row, the first super diagonal resides on the RHS of the k-1'th row, etc, with the k'th diagonal on the RHS of the 0'th row. Ex: (rocblas_fill_upper; m = 5; k = 2) 1 6 9 0 0 0 0 9 8 7 0 2 7 8 0 0 6 7 8 9 0 0 3 8 7 ----> 1 2 3 4 5 0 0 0 4 9 0 0 0 0 0 0 0 0 0 5 0 0 0 0 0 if uplo == rocblas_fill_lower: The matrix represnted is a lower banded triangular matrix with the main diagonal and k sub-diagonals, everything else can be assumed to be 0. The matrix is compacted so that the main diagonal resides on the 0'th row, working up to the k'th diagonal residing on the LHS of the k'th row. Ex: (rocblas_fill_lower; m = 5; k = 2) 1 0 0 0 0 1 2 3 4 5 6 2 0 0 0 6 7 8 9 0 9 7 3 0 0 ----> 9 8 7 0 0 0 8 8 4 0 0 0 0 0 0 0 0 7 9 5 0 0 0 0 0
lda – [in] [rocblas_int] specifies the leading dimension of each A_i. lda must satisfy lda > k.
x – [inout] device array of device pointer storing each vector x_i.
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i.
batch_count – [in] [rocblas_int] number of instances in the batch.
-
rocblas_status rocblas_stbmv_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation trans, rocblas_diagonal diag, rocblas_int m, rocblas_int k, const float *A, rocblas_int lda, rocblas_stride stride_A, float *x, rocblas_int incx, rocblas_stride stride_x, rocblas_int batch_count)#
-
rocblas_status rocblas_dtbmv_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation trans, rocblas_diagonal diag, rocblas_int m, rocblas_int k, const double *A, rocblas_int lda, rocblas_stride stride_A, double *x, rocblas_int incx, rocblas_stride stride_x, rocblas_int batch_count)#
-
rocblas_status rocblas_ctbmv_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation trans, rocblas_diagonal diag, rocblas_int m, rocblas_int k, const rocblas_float_complex *A, rocblas_int lda, rocblas_stride stride_A, rocblas_float_complex *x, rocblas_int incx, rocblas_stride stride_x, rocblas_int batch_count)#
-
rocblas_status rocblas_ztbmv_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation trans, rocblas_diagonal diag, rocblas_int m, rocblas_int k, const rocblas_double_complex *A, rocblas_int lda, rocblas_stride stride_A, rocblas_double_complex *x, rocblas_int incx, rocblas_stride stride_x, rocblas_int batch_count)#
BLAS Level 2 API
tbmv_strided_batched performs one of the matrix-vector operations:
x_i := A_i*x_i or x_i := A_i**T*x_i or x_i := A_i**H*x_i, where (A_i, x_i) is the i-th instance of the batch. x_i is a vector and A_i is an m by m matrix, for i = 1, ..., batch_count.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill]
rocblas_fill_upper: each A_i is an upper banded triangular matrix.
rocblas_fill_lower: each A_i is a lower banded triangular matrix.
trans – [in] [rocblas_operation] indicates whether each matrix A_i is tranposed (conjugated) or not.
diag – [in] [rocblas_diagonal]
rocblas_diagonal_unit: The main diagonal of each A_i is assumed to consist of only 1’s and is not referenced.
rocblas_diagonal_non_unit: No assumptions are made of each A_i’s main diagonal.
m – [in] [rocblas_int] the number of rows and columns of the matrix represented by each A_i.
k – [in] [rocblas_int]
if uplo == rocblas_fill_upper, k specifies the number of super-diagonals of each matrix A_i. if uplo == rocblas_fill_lower, k specifies the number of sub-diagonals of each matrix A_i. k must satisfy k > 0 && k < lda.
A – [in] device array to the first matrix A_i of the batch. Stores each banded triangular matrix A_i.
if uplo == rocblas_fill_upper: The matrix represented is an upper banded triangular matrix with the main diagonal and k super-diagonals, everything else can be assumed to be 0. The matrix is compacted so that the main diagonal resides on the k'th row, the first super diagonal resides on the RHS of the k-1'th row, etc, with the k'th diagonal on the RHS of the 0'th row. Ex: (rocblas_fill_upper; m = 5; k = 2) 1 6 9 0 0 0 0 9 8 7 0 2 7 8 0 0 6 7 8 9 0 0 3 8 7 ----> 1 2 3 4 5 0 0 0 4 9 0 0 0 0 0 0 0 0 0 5 0 0 0 0 0 if uplo == rocblas_fill_lower: The matrix represnted is a lower banded triangular matrix with the main diagonal and k sub-diagonals, everything else can be assumed to be 0. The matrix is compacted so that the main diagonal resides on the 0'th row, working up to the k'th diagonal residing on the LHS of the k'th row. Ex: (rocblas_fill_lower; m = 5; k = 2) 1 0 0 0 0 1 2 3 4 5 6 2 0 0 0 6 7 8 9 0 9 7 3 0 0 ----> 9 8 7 0 0 0 8 8 4 0 0 0 0 0 0 0 0 7 9 5 0 0 0 0 0
lda – [in] [rocblas_int] specifies the leading dimension of each A_i. lda must satisfy lda > k.
stride_A – [in] [rocblas_stride] stride from the start of one A_i matrix to the next A_(i + 1).
x – [inout] device array to the first vector x_i of the batch.
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i.
stride_x – [in] [rocblas_stride] stride from the start of one x_i matrix to the next x_(i + 1).
batch_count – [in] [rocblas_int] number of instances in the batch.
rocblas_Xtbsv + batched, strided_batched#
-
rocblas_status rocblas_stbsv(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int n, rocblas_int k, const float *A, rocblas_int lda, float *x, rocblas_int incx)#
-
rocblas_status rocblas_dtbsv(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int n, rocblas_int k, const double *A, rocblas_int lda, double *x, rocblas_int incx)#
-
rocblas_status rocblas_ctbsv(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int n, rocblas_int k, const rocblas_float_complex *A, rocblas_int lda, rocblas_float_complex *x, rocblas_int incx)#
-
rocblas_status rocblas_ztbsv(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int n, rocblas_int k, const rocblas_double_complex *A, rocblas_int lda, rocblas_double_complex *x, rocblas_int incx)#
BLAS Level 2 API
tbsv solves:
A*x = b or A**T*x = b or A**H*x = b where x and b are vectors and A is a banded triangular matrix.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill]
rocblas_fill_upper: A is an upper triangular matrix.
rocblas_fill_lower: A is a lower triangular matrix.
transA – [in] [rocblas_operation]
rocblas_operation_none: Solves A*x = b
rocblas_operation_transpose: Solves A**T*x = b
rocblas_operation_conjugate_transpose: Solves A**H*x = b
diag – [in] [rocblas_diagonal]
rocblas_diagonal_unit: A is assumed to be unit triangular (i.e. the diagonal elements of A are not used in computations).
rocblas_diagonal_non_unit: A is not assumed to be unit triangular.
n – [in] [rocblas_int] n specifies the number of rows of b. n >= 0.
k – [in] [rocblas_int]
if(uplo == rocblas_fill_upper) k specifies the number of super-diagonals of A. if(uplo == rocblas_fill_lower) k specifies the number of sub-diagonals of A. k >= 0.
A – [in] device pointer storing the matrix A in banded format.
lda – [in] [rocblas_int] specifies the leading dimension of A. lda >= (k + 1).
x – [inout] device pointer storing input vector b. Overwritten by the output vector x.
incx – [in] [rocblas_int] specifies the increment for the elements of x.
-
rocblas_status rocblas_stbsv_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int n, rocblas_int k, const float *const A[], rocblas_int lda, float *const x[], rocblas_int incx, rocblas_int batch_count)#
-
rocblas_status rocblas_dtbsv_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int n, rocblas_int k, const double *const A[], rocblas_int lda, double *const x[], rocblas_int incx, rocblas_int batch_count)#
-
rocblas_status rocblas_ctbsv_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int n, rocblas_int k, const rocblas_float_complex *const A[], rocblas_int lda, rocblas_float_complex *const x[], rocblas_int incx, rocblas_int batch_count)#
-
rocblas_status rocblas_ztbsv_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int n, rocblas_int k, const rocblas_double_complex *const A[], rocblas_int lda, rocblas_double_complex *const x[], rocblas_int incx, rocblas_int batch_count)#
BLAS Level 2 API
tbsv_batched solves:
A_i*x_i = b_i or A_i**T*x_i = b_i or A_i**H*x_i = b_i where x_i and b_i are vectors and A_i is a banded triangular matrix, for i = [1, batch_count].
The input vectors b_i are overwritten by the output vectors x_i.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill]
rocblas_fill_upper: A_i is an upper triangular matrix.
rocblas_fill_lower: A_i is a lower triangular matrix.
transA – [in] [rocblas_operation]
rocblas_operation_none: Solves A_i*x_i = b_i
rocblas_operation_transpose: Solves A_i**T*x_i = b_i
rocblas_operation_conjugate_transpose: Solves A_i**H*x_i = b_i
diag – [in] [rocblas_diagonal]
rocblas_diagonal_unit: each A_i is assumed to be unit triangular (i.e. the diagonal elements of each A_i are not used in computations).
rocblas_diagonal_non_unit: each A_i is not assumed to be unit triangular.
n – [in] [rocblas_int] n specifies the number of rows of each b_i. n >= 0.
k – [in] [rocblas_int]
if(uplo == rocblas_fill_upper) k specifies the number of super-diagonals of each A_i. if(uplo == rocblas_fill_lower) k specifies the number of sub-diagonals of each A_i. k >= 0.
A – [in] device vector of device pointers storing each matrix A_i in banded format.
lda – [in] [rocblas_int] specifies the leading dimension of each A_i. lda >= (k + 1).
x – [inout] device vector of device pointers storing each input vector b_i. Overwritten by each output vector x_i.
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i.
batch_count – [in] [rocblas_int] number of instances in the batch.
-
rocblas_status rocblas_stbsv_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int n, rocblas_int k, const float *A, rocblas_int lda, rocblas_stride stride_A, float *x, rocblas_int incx, rocblas_stride stride_x, rocblas_int batch_count)#
-
rocblas_status rocblas_dtbsv_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int n, rocblas_int k, const double *A, rocblas_int lda, rocblas_stride stride_A, double *x, rocblas_int incx, rocblas_stride stride_x, rocblas_int batch_count)#
-
rocblas_status rocblas_ctbsv_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int n, rocblas_int k, const rocblas_float_complex *A, rocblas_int lda, rocblas_stride stride_A, rocblas_float_complex *x, rocblas_int incx, rocblas_stride stride_x, rocblas_int batch_count)#
-
rocblas_status rocblas_ztbsv_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int n, rocblas_int k, const rocblas_double_complex *A, rocblas_int lda, rocblas_stride stride_A, rocblas_double_complex *x, rocblas_int incx, rocblas_stride stride_x, rocblas_int batch_count)#
BLAS Level 2 API
tbsv_strided_batched solves:
A_i*x_i = b_i or A_i**T*x_i = b_i or A_i**H*x_i = b_i where x_i and b_i are vectors and A_i is a banded triangular matrix, for i = [1, batch_count].
The input vectors b_i are overwritten by the output vectors x_i.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill]
rocblas_fill_upper: A_i is an upper triangular matrix.
rocblas_fill_lower: A_i is a lower triangular matrix.
transA – [in] [rocblas_operation]
rocblas_operation_none: Solves A_i*x_i = b_i
rocblas_operation_transpose: Solves A_i**T*x_i = b_i
rocblas_operation_conjugate_transpose: Solves A_i**H*x_i = b_i
diag – [in] [rocblas_diagonal]
rocblas_diagonal_unit: each A_i is assumed to be unit triangular (i.e. the diagonal elements of each A_i are not used in computations).
rocblas_diagonal_non_unit: each A_i is not assumed to be unit triangular.
n – [in] [rocblas_int] n specifies the number of rows of each b_i. n >= 0.
k – [in] [rocblas_int]
if(uplo == rocblas_fill_upper) k specifies the number of super-diagonals of each A_i. if(uplo == rocblas_fill_lower) k specifies the number of sub-diagonals of each A_i. k >= 0.
A – [in] device pointer pointing to the first banded matrix A_1.
lda – [in] [rocblas_int] specifies the leading dimension of each A_i. lda >= (k + 1).
stride_A – [in] [rocblas_stride] specifies the distance between the start of one matrix (A_i) and the next (A_i+1).
x – [inout] device pointer pointing to the first input vector b_1. Overwritten by output vectors x.
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i.
stride_x – [in] [rocblas_stride] specifies the distance between the start of one vector (x_i) and the next (x_i+1).
batch_count – [in] [rocblas_int] number of instances in the batch.
rocblas_Xtpmv + batched, strided_batched#
-
rocblas_status rocblas_stpmv(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, const float *A, float *x, rocblas_int incx)#
-
rocblas_status rocblas_dtpmv(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, const double *A, double *x, rocblas_int incx)#
-
rocblas_status rocblas_ctpmv(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, const rocblas_float_complex *A, rocblas_float_complex *x, rocblas_int incx)#
-
rocblas_status rocblas_ztpmv(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, const rocblas_double_complex *A, rocblas_double_complex *x, rocblas_int incx)#
BLAS Level 2 API
tpmv performs one of the matrix-vector operations:
x = A*x or x = A**T*x, where x is an n element vector and A is an n by n unit, or non-unit, upper or lower triangular matrix, supplied in the pack form. The vector x is overwritten.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill]
rocblas_fill_upper: A is an upper triangular matrix.
rocblas_fill_lower: A is a lower triangular matrix.
transA – [in] [rocblas_operation]
diag – [in] [rocblas_diagonal]
rocblas_diagonal_unit: A is assumed to be unit triangular.
rocblas_diagonal_non_unit: A is not assumed to be unit triangular.
m – [in] [rocblas_int] m specifies the number of rows of A. m >= 0.
A – [in] device pointer storing matrix A, of dimension at leat ( m * ( m + 1 ) / 2 ).
Before entry with uplo = rocblas_fill_upper, the array A must contain the upper triangular matrix packed sequentially, column by column, so that A[0] contains a_{0,0}, A[1] and A[2] contain a_{0,1} and a_{1, 1}, respectively, and so on.
Before entry with uplo = rocblas_fill_lower, the array A must contain the lower triangular matrix packed sequentially, column by column, so that A[0] contains a_{0,0}, A[1] and A[2] contain a_{1,0} and a_{2,0}, respectively, and so on.
Note that when DIAG = rocblas_diagonal_unit, the diagonal elements of A are not referenced, but are assumed to be unity.
x – [in] device pointer storing vector x.
incx – [in] [rocblas_int] specifies the increment for the elements of x. incx must not be zero.
-
rocblas_status rocblas_stpmv_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, const float *const *A, float *const *x, rocblas_int incx, rocblas_int batch_count)#
-
rocblas_status rocblas_dtpmv_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, const double *const *A, double *const *x, rocblas_int incx, rocblas_int batch_count)#
-
rocblas_status rocblas_ctpmv_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, const rocblas_float_complex *const *A, rocblas_float_complex *const *x, rocblas_int incx, rocblas_int batch_count)#
-
rocblas_status rocblas_ztpmv_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, const rocblas_double_complex *const *A, rocblas_double_complex *const *x, rocblas_int incx, rocblas_int batch_count)#
BLAS Level 2 API
tpmv_batched performs one of the matrix-vector operations:
x_i = A_i*x_i or x_i = A**T*x_i, 0 < i < batch_count where x_i is an n element vector and A_i is an n by n (unit, or non-unit, upper or lower triangular matrix) The vectors x_i are overwritten.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill]
rocblas_fill_upper: A_i is an upper triangular matrix.
rocblas_fill_lower: A_i is a lower triangular matrix.
transA – [in] [rocblas_operation]
diag – [in] [rocblas_diagonal]
rocblas_diagonal_unit: A_i is assumed to be unit triangular.
rocblas_diagonal_non_unit: A_i is not assumed to be unit triangular.
m – [in] [rocblas_int] m specifies the number of rows of matrices A_i. m >= 0.
A – [in] device pointer storing pointer of matrices A_i, of dimension ( lda, m ).
x – [in] device pointer storing vectors x_i.
incx – [in] [rocblas_int] specifies the increment for the elements of vectors x_i.
batch_count – [in] [rocblas_int] The number of batched matrices/vectors.
-
rocblas_status rocblas_stpmv_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, const float *A, rocblas_stride stride_A, float *x, rocblas_int incx, rocblas_stride stride_x, rocblas_int batch_count)#
-
rocblas_status rocblas_dtpmv_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, const double *A, rocblas_stride stride_A, double *x, rocblas_int incx, rocblas_stride stride_x, rocblas_int batch_count)#
-
rocblas_status rocblas_ctpmv_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, const rocblas_float_complex *A, rocblas_stride stride_A, rocblas_float_complex *x, rocblas_int incx, rocblas_stride stride_x, rocblas_int batch_count)#
-
rocblas_status rocblas_ztpmv_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, const rocblas_double_complex *A, rocblas_stride stride_A, rocblas_double_complex *x, rocblas_int incx, rocblas_stride stride_x, rocblas_int batch_count)#
BLAS Level 2 API
tpmv_strided_batched performs one of the matrix-vector operations:
x_i = A_i*x_i or x_i = A**T*x_i, 0 < i < batch_count where x_i is an n element vector and A_i is an n by n (unit, or non-unit, upper or lower triangular matrix) with strides specifying how to retrieve $x_i$ (resp. $A_i$) from $x_{i-1}$ (resp. $A_i$). The vectors x_i are overwritten.- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill]
rocblas_fill_upper: A_i is an upper triangular matrix.
rocblas_fill_lower: A_i is a lower triangular matrix.
transA – [in] [rocblas_operation]
diag – [in] [rocblas_diagonal]
rocblas_diagonal_unit: A_i is assumed to be unit triangular.
rocblas_diagonal_non_unit: A_i is not assumed to be unit triangular.
m – [in] [rocblas_int] m specifies the number of rows of matrices A_i. m >= 0.
A – [in] device pointer of the matrix A_0, of dimension ( lda, m )
stride_A – [in] [rocblas_stride] stride from the start of one A_i matrix to the next A_{i + 1}.
x – [in] device pointer storing the vector x_0.
incx – [in] [rocblas_int] specifies the increment for the elements of one vector x.
stride_x – [in] [rocblas_stride] stride from the start of one x_i vector to the next x_{i + 1}.
batch_count – [in] [rocblas_int] The number of batched matrices/vectors.
rocblas_Xtpsv + batched, strided_batched#
-
rocblas_status rocblas_stpsv(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int n, const float *AP, float *x, rocblas_int incx)#
-
rocblas_status rocblas_dtpsv(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int n, const double *AP, double *x, rocblas_int incx)#
-
rocblas_status rocblas_ctpsv(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int n, const rocblas_float_complex *AP, rocblas_float_complex *x, rocblas_int incx)#
-
rocblas_status rocblas_ztpsv(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int n, const rocblas_double_complex *AP, rocblas_double_complex *x, rocblas_int incx)#
BLAS Level 2 API
tpsv solves:
A*x = b or A**T*x = b or A**H*x = b where x and b are vectors and A is a triangular matrix stored in the packed format.
The input vector b is overwritten by the output vector x.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill]
rocblas_fill_upper: A is an upper triangular matrix.
rocblas_fill_lower: A is a lower triangular matrix.
transA – [in] [rocblas_operation]
rocblas_operation_none: Solves A*x = b
rocblas_operation_transpose: Solves A**T*x = b
rocblas_operation_conjugate_transpose: Solves A**H*x = b
diag – [in] [rocblas_diagonal]
rocblas_diagonal_unit: A is assumed to be unit triangular (i.e. the diagonal elements of A are not used in computations).
rocblas_diagonal_non_unit: A is not assumed to be unit triangular.
n – [in] [rocblas_int] n specifies the number of rows of b. n >= 0.
AP – [in] device pointer storing the packed version of matrix A, of dimension >= (n * (n + 1) / 2).
x – [inout] device pointer storing vector b on input, overwritten by x on output.
incx – [in] [rocblas_int] specifies the increment for the elements of x.
-
rocblas_status rocblas_stpsv_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int n, const float *const AP[], float *const x[], rocblas_int incx, rocblas_int batch_count)#
-
rocblas_status rocblas_dtpsv_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int n, const double *const AP[], double *const x[], rocblas_int incx, rocblas_int batch_count)#
-
rocblas_status rocblas_ctpsv_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int n, const rocblas_float_complex *const AP[], rocblas_float_complex *const x[], rocblas_int incx, rocblas_int batch_count)#
-
rocblas_status rocblas_ztpsv_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int n, const rocblas_double_complex *const AP[], rocblas_double_complex *const x[], rocblas_int incx, rocblas_int batch_count)#
BLAS Level 2 API
tpsv_batched solves:
A_i*x_i = b_i or A_i**T*x_i = b_i or A_i**H*x_i = b_i where x_i and b_i are vectors and A_i is a triangular matrix stored in the packed format, for i in [1, batch_count].
The input vectors b_i are overwritten by the output vectors x_i.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill]
rocblas_fill_upper: each A_i is an upper triangular matrix.
rocblas_fill_lower: each A_i is a lower triangular matrix.
transA – [in] [rocblas_operation]
rocblas_operation_none: Solves A*x = b
rocblas_operation_transpose: Solves A**T*x = b
rocblas_operation_conjugate_transpose: Solves A**H*x = b
diag – [in] [rocblas_diagonal]
rocblas_diagonal_unit: Each A_i is assumed to be unit triangular (i.e. the diagonal elements of each A_i are not used in computations).
rocblas_diagonal_non_unit: each A_i is not assumed to be unit triangular.
n – [in] [rocblas_int] n specifies the number of rows of each b_i. n >= 0.
AP – [in] device array of device pointers storing the packed versions of each matrix A_i, of dimension >= (n * (n + 1) / 2).
x – [inout] device array of device pointers storing each input vector b_i, overwritten by x_i on output.
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i.
batch_count – [in] [rocblas_int] specifies the number of instances in the batch.
-
rocblas_status rocblas_stpsv_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int n, const float *AP, rocblas_stride stride_A, float *x, rocblas_int incx, rocblas_stride stride_x, rocblas_int batch_count)#
-
rocblas_status rocblas_dtpsv_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int n, const double *AP, rocblas_stride stride_A, double *x, rocblas_int incx, rocblas_stride stride_x, rocblas_int batch_count)#
-
rocblas_status rocblas_ctpsv_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int n, const rocblas_float_complex *AP, rocblas_stride stride_A, rocblas_float_complex *x, rocblas_int incx, rocblas_stride stride_x, rocblas_int batch_count)#
-
rocblas_status rocblas_ztpsv_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int n, const rocblas_double_complex *AP, rocblas_stride stride_A, rocblas_double_complex *x, rocblas_int incx, rocblas_stride stride_x, rocblas_int batch_count)#
BLAS Level 2 API
tpsv_strided_batched solves:
A_i*x_i = b_i or A_i**T*x_i = b_i or A_i**H*x_i = b_i where x_i and b_i are vectors and A_i is a triangular matrix stored in the packed format, for i in [1, batch_count].
The input vectors b_i are overwritten by the output vectors x_i.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill]
rocblas_fill_upper: each A_i is an upper triangular matrix.
rocblas_fill_lower: each A_i is a lower triangular matrix.
transA – [in] [rocblas_operation]
rocblas_operation_none: Solves A*x = b
rocblas_operation_transpose: Solves A**T*x = b
rocblas_operation_conjugate_transpose: Solves A**H*x = b
diag – [in] [rocblas_diagonal]
rocblas_diagonal_unit: each A_i is assumed to be unit triangular (i.e. the diagonal elements of each A_i are not used in computations).
rocblas_diagonal_non_unit: each A_i is not assumed to be unit triangular.
n – [in] [rocblas_int] n specifies the number of rows of each b_i. n >= 0.
AP – [in] device pointer pointing to the first packed matrix A_1, of dimension >= (n * (n + 1) / 2).
stride_A – [in] [rocblas_stride] stride from the beginning of one packed matrix (AP_i) and the next (AP_i+1).
x – [inout] device pointer pointing to the first input vector b_1. Overwritten by each x_i on output.
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i.
stride_x – [in] [rocblas_stride] stride from the beginning of one vector (x_i) and the next (x_i+1).
batch_count – [in] [rocblas_int] specifies the number of instances in the batch.
rocblas_Xtrmv + batched, strided_batched#
-
rocblas_status rocblas_strmv(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, const float *A, rocblas_int lda, float *x, rocblas_int incx)#
-
rocblas_status rocblas_dtrmv(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, const double *A, rocblas_int lda, double *x, rocblas_int incx)#
-
rocblas_status rocblas_ctrmv(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, const rocblas_float_complex *A, rocblas_int lda, rocblas_float_complex *x, rocblas_int incx)#
-
rocblas_status rocblas_ztrmv(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, const rocblas_double_complex *A, rocblas_int lda, rocblas_double_complex *x, rocblas_int incx)#
BLAS Level 2 API
trmv performs one of the matrix-vector operations:
x = A*x or x = A**T*x, where x is an n element vector and A is an n by n unit, or non-unit, upper or lower triangular matrix. The vector x is overwritten.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill]
rocblas_fill_upper: A is an upper triangular matrix.
rocblas_fill_lower: A is a lower triangular matrix.
transA – [in] [rocblas_operation]
diag – [in] [rocblas_diagonal]
rocblas_diagonal_unit: A is assumed to be unit triangular.
rocblas_diagonal_non_unit: A is not assumed to be unit triangular.
m – [in] [rocblas_int] m specifies the number of rows of A. m >= 0.
A – [in] device pointer storing matrix A, of dimension ( lda, m ).
lda – [in] [rocblas_int] specifies the leading dimension of A. lda = max( 1, m ).
x – [in] device pointer storing vector x.
incx – [in] [rocblas_int] specifies the increment for the elements of x.
-
rocblas_status rocblas_strmv_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, const float *const *A, rocblas_int lda, float *const *x, rocblas_int incx, rocblas_int batch_count)#
-
rocblas_status rocblas_dtrmv_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, const double *const *A, rocblas_int lda, double *const *x, rocblas_int incx, rocblas_int batch_count)#
-
rocblas_status rocblas_ctrmv_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, const rocblas_float_complex *const *A, rocblas_int lda, rocblas_float_complex *const *x, rocblas_int incx, rocblas_int batch_count)#
-
rocblas_status rocblas_ztrmv_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, const rocblas_double_complex *const *A, rocblas_int lda, rocblas_double_complex *const *x, rocblas_int incx, rocblas_int batch_count)#
BLAS Level 2 API
trmv_batched performs one of the matrix-vector operations:
x_i = A_i*x_i or x_i = A**T*x_i, 0 < i < batch_count where x_i is an n element vector and A_i is an n by n (unit, or non-unit, upper or lower triangular matrix) The vectors x_i are overwritten.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill]
rocblas_fill_upper: A_i is an upper triangular matrix.
rocblas_fill_lower: A_i is a lower triangular matrix.
transA – [in] [rocblas_operation]
diag – [in] [rocblas_diagonal]
rocblas_diagonal_unit: A_i is assumed to be unit triangular.
rocblas_diagonal_non_unit: A_i is not assumed to be unit triangular.
m – [in] [rocblas_int] m specifies the number of rows of matrices A_i. m >= 0.
A – [in] device pointer storing pointer of matrices A_i, of dimension ( lda, m )
lda – [in] [rocblas_int] specifies the leading dimension of A_i. lda >= max( 1, m ).
x – [in] device pointer storing vectors x_i.
incx – [in] [rocblas_int] specifies the increment for the elements of vectors x_i.
batch_count – [in] [rocblas_int] The number of batched matrices/vectors.
-
rocblas_status rocblas_strmv_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, const float *A, rocblas_int lda, rocblas_stride stride_A, float *x, rocblas_int incx, rocblas_stride stride_x, rocblas_int batch_count)#
-
rocblas_status rocblas_dtrmv_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, const double *A, rocblas_int lda, rocblas_stride stride_A, double *x, rocblas_int incx, rocblas_stride stride_x, rocblas_int batch_count)#
-
rocblas_status rocblas_ctrmv_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, const rocblas_float_complex *A, rocblas_int lda, rocblas_stride stride_A, rocblas_float_complex *x, rocblas_int incx, rocblas_stride stride_x, rocblas_int batch_count)#
-
rocblas_status rocblas_ztrmv_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, const rocblas_double_complex *A, rocblas_int lda, rocblas_stride stride_A, rocblas_double_complex *x, rocblas_int incx, rocblas_stride stride_x, rocblas_int batch_count)#
BLAS Level 2 API
trmv_strided_batched performs one of the matrix-vector operations:
x_i = A_i*x_i or x_i = A**T*x_i, 0 < i < batch_count where x_i is an n element vector and A_i is an n by n (unit, or non-unit, upper or lower triangular matrix) with strides specifying how to retrieve $x_i$ (resp. $A_i$) from $x_{i-1}$ (resp. $A_i$).The vectors x_i are overwritten.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill]
rocblas_fill_upper: A_i is an upper triangular matrix.
rocblas_fill_lower: A_i is a lower triangular matrix.
transA – [in] [rocblas_operation]
diag – [in] [rocblas_diagonal]
rocblas_diagonal_unit: A_i is assumed to be unit triangular.
rocblas_diagonal_non_unit: A_i is not assumed to be unit triangular.
m – [in] [rocblas_int] m specifies the number of rows of matrices A_i. m >= 0.
A – [in] device pointer of the matrix A_0, of dimension ( lda, m ).
lda – [in] [rocblas_int] specifies the leading dimension of A_i. lda >= max( 1, m ).
stride_A – [in] [rocblas_stride] stride from the start of one A_i matrix to the next A_{i + 1}.
x – [in] device pointer storing the vector x_0.
incx – [in] [rocblas_int] specifies the increment for the elements of one vector x.
stride_x – [in] [rocblas_stride] stride from the start of one x_i vector to the next x_{i + 1}.
batch_count – [in] [rocblas_int] The number of batched matrices/vectors.
rocblas_Xtrsv + batched, strided_batched#
-
rocblas_status rocblas_strsv(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, const float *A, rocblas_int lda, float *x, rocblas_int incx)#
-
rocblas_status rocblas_dtrsv(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, const double *A, rocblas_int lda, double *x, rocblas_int incx)#
-
rocblas_status rocblas_ctrsv(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, const rocblas_float_complex *A, rocblas_int lda, rocblas_float_complex *x, rocblas_int incx)#
-
rocblas_status rocblas_ztrsv(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, const rocblas_double_complex *A, rocblas_int lda, rocblas_double_complex *x, rocblas_int incx)#
BLAS Level 2 API
trsv solves:
A*x = b or A**T*x = b where x and b are vectors and A is a triangular matrix. The vector x is overwritten on b.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill]
rocblas_fill_upper: A is an upper triangular matrix.
rocblas_fill_lower: A is a lower triangular matrix.
transA – [in] [rocblas_operation]
diag – [in] [rocblas_diagonal]
rocblas_diagonal_unit: A is assumed to be unit triangular.
rocblas_diagonal_non_unit: A is not assumed to be unit triangular.
m – [in] [rocblas_int] m specifies the number of rows of b. m >= 0.
A – [in] device pointer storing matrix A, of dimension ( lda, m )
lda – [in] [rocblas_int] specifies the leading dimension of A. lda = max( 1, m ).
x – [in] device pointer storing vector x.
incx – [in] [rocblas_int] specifies the increment for the elements of x.
-
rocblas_status rocblas_strsv_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, const float *const A[], rocblas_int lda, float *const x[], rocblas_int incx, rocblas_int batch_count)#
-
rocblas_status rocblas_dtrsv_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, const double *const A[], rocblas_int lda, double *const x[], rocblas_int incx, rocblas_int batch_count)#
-
rocblas_status rocblas_ctrsv_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, const rocblas_float_complex *const A[], rocblas_int lda, rocblas_float_complex *const x[], rocblas_int incx, rocblas_int batch_count)#
-
rocblas_status rocblas_ztrsv_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, const rocblas_double_complex *const A[], rocblas_int lda, rocblas_double_complex *const x[], rocblas_int incx, rocblas_int batch_count)#
BLAS Level 2 API
trsv_batched solves:
A_i*x_i = b_i or A_i**T*x_i = b_i where (A_i, x_i, b_i) is the i-th instance of the batch. x_i and b_i are vectors and A_i is an m by m triangular matrix.
The vector x is overwritten on b.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill]
rocblas_fill_upper: A is an upper triangular matrix.
rocblas_fill_lower: A is a lower triangular matrix.
transA – [in] [rocblas_operation]
diag – [in] [rocblas_diagonal]
rocblas_diagonal_unit: A is assumed to be unit triangular.
rocblas_diagonal_non_unit: A is not assumed to be unit triangular.
m – [in] [rocblas_int] m specifies the number of rows of b. m >= 0.
A – [in] device array of device pointers storing each matrix A_i.
lda – [in] [rocblas_int] specifies the leading dimension of each A_i. lda = max(1, m)
x – [in] device array of device pointers storing each vector x_i.
incx – [in] [rocblas_int] specifies the increment for the elements of x.
batch_count – [in] [rocblas_int] number of instances in the batch.
-
rocblas_status rocblas_strsv_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, const float *A, rocblas_int lda, rocblas_stride stride_A, float *x, rocblas_int incx, rocblas_stride stride_x, rocblas_int batch_count)#
-
rocblas_status rocblas_dtrsv_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, const double *A, rocblas_int lda, rocblas_stride stride_A, double *x, rocblas_int incx, rocblas_stride stride_x, rocblas_int batch_count)#
-
rocblas_status rocblas_ctrsv_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, const rocblas_float_complex *A, rocblas_int lda, rocblas_stride stride_A, rocblas_float_complex *x, rocblas_int incx, rocblas_stride stride_x, rocblas_int batch_count)#
-
rocblas_status rocblas_ztrsv_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, const rocblas_double_complex *A, rocblas_int lda, rocblas_stride stride_A, rocblas_double_complex *x, rocblas_int incx, rocblas_stride stride_x, rocblas_int batch_count)#
BLAS Level 2 API
trsv_strided_batched solves:
A_i*x_i = b_i or A_i**T*x_i = b_i where (A_i, x_i, b_i) is the i-th instance of the batch. x_i and b_i are vectors and A_i is an m by m triangular matrix, for i = 1, ..., batch_count.
The vector x is overwritten on b.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill]
rocblas_fill_upper: A is an upper triangular matrix.
rocblas_fill_lower: A is a lower triangular matrix.
transA – [in] [rocblas_operation]
diag – [in] [rocblas_diagonal]
rocblas_diagonal_unit: A is assumed to be unit triangular.
rocblas_diagonal_non_unit: A is not assumed to be unit triangular.
m – [in] [rocblas_int] m specifies the number of rows of each b_i. m >= 0.
A – [in] device pointer to the first matrix (A_1) in the batch, of dimension ( lda, m ).
stride_A – [in] [rocblas_stride] stride from the start of one A_i matrix to the next A_(i + 1).
lda – [in] [rocblas_int] specifies the leading dimension of each A_i. lda = max( 1, m ).
x – [inout] device pointer to the first vector (x_1) in the batch.
stride_x – [in] [rocblas_stride] stride from the start of one x_i vector to the next x_(i + 1)
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i.
batch_count – [in] [rocblas_int] number of instances in the batch.
rocblas_Xhemv + batched, strided_batched#
-
rocblas_status rocblas_chemv(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *A, rocblas_int lda, const rocblas_float_complex *x, rocblas_int incx, const rocblas_float_complex *beta, rocblas_float_complex *y, rocblas_int incy)#
-
rocblas_status rocblas_zhemv(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *A, rocblas_int lda, const rocblas_double_complex *x, rocblas_int incx, const rocblas_double_complex *beta, rocblas_double_complex *y, rocblas_int incy)#
BLAS Level 2 API
hemv performs one of the matrix-vector operations:
y := alpha*A*x + beta*y where alpha and beta are scalars, x and y are n element vectors and A is an n by n Hermitian matrix.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill]
rocblas_fill_upper: the upper triangular part of the Hermitian matrix A is supplied.
rocblas_fill_lower: the lower triangular part of the Hermitian matrix A is supplied.
n – [in] [rocblas_int] the order of the matrix A.
alpha – [in] device pointer or host pointer to scalar alpha.
A – [in] device pointer storing matrix A. Of dimension (lda, n).
if uplo == rocblas_fill_upper: The upper triangular part of A must contain the upper triangular part of a Hermitian matrix. The lower triangular part of A will not be referenced. if uplo == rocblas_fill_lower: The lower triangular part of A must contain the lower triangular part of a Hermitian matrix. The upper triangular part of A will not be referenced. As a Hermitian matrix, the imaginary part of the main diagonal of A will not be referenced and is assumed to be == 0.
lda – [in] [rocblas_int] specifies the leading dimension of A. must be >= max(1, n).
x – [in] device pointer storing vector x.
incx – [in] [rocblas_int] specifies the increment for the elements of x.
beta – [in] device pointer or host pointer to scalar beta.
y – [inout] device pointer storing vector y.
incy – [in] [rocblas_int] specifies the increment for the elements of y.
-
rocblas_status rocblas_chemv_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *const A[], rocblas_int lda, const rocblas_float_complex *const x[], rocblas_int incx, const rocblas_float_complex *beta, rocblas_float_complex *const y[], rocblas_int incy, rocblas_int batch_count)#
-
rocblas_status rocblas_zhemv_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *const A[], rocblas_int lda, const rocblas_double_complex *const x[], rocblas_int incx, const rocblas_double_complex *beta, rocblas_double_complex *const y[], rocblas_int incy, rocblas_int batch_count)#
BLAS Level 2 API
hemv_batched performs one of the matrix-vector operations:
y_i := alpha*A_i*x_i + beta*y_i where alpha and beta are scalars, x_i and y_i are n element vectors and A_i is an n by n Hermitian matrix, for each batch in i = [1, batch_count].
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill]
rocblas_fill_upper: the upper triangular part of the Hermitian matrix A is supplied.
rocblas_fill_lower: the lower triangular part of the Hermitian matrix A is supplied.
n – [in] [rocblas_int] the order of each matrix A_i.
alpha – [in] device pointer or host pointer to scalar alpha.
A – [in] device array of device pointers storing each matrix A_i of dimension (lda, n).
if uplo == rocblas_fill_upper: The upper triangular part of each A_i must contain the upper triangular part of a Hermitian matrix. The lower triangular part of each A_i will not be referenced. if uplo == rocblas_fill_lower: The lower triangular part of each A_i must contain the lower triangular part of a Hermitian matrix. The upper triangular part of each A_i will not be referenced. As a Hermitian matrix, the imaginary part of the main diagonal of each A_i will not be referenced and is assumed to be == 0.
lda – [in] [rocblas_int] specifies the leading dimension of each A_i. must be >= max(1, n).
x – [in] device array of device pointers storing each vector x_i.
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i.
beta – [in] device pointer or host pointer to scalar beta.
y – [inout] device array of device pointers storing each vector y_i.
incy – [in] [rocblas_int] specifies the increment for the elements of y.
batch_count – [in] [rocblas_int] number of instances in the batch.
-
rocblas_status rocblas_chemv_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *A, rocblas_int lda, rocblas_stride stride_A, const rocblas_float_complex *x, rocblas_int incx, rocblas_stride stride_x, const rocblas_float_complex *beta, rocblas_float_complex *y, rocblas_int incy, rocblas_stride stride_y, rocblas_int batch_count)#
-
rocblas_status rocblas_zhemv_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *A, rocblas_int lda, rocblas_stride stride_A, const rocblas_double_complex *x, rocblas_int incx, rocblas_stride stride_x, const rocblas_double_complex *beta, rocblas_double_complex *y, rocblas_int incy, rocblas_stride stride_y, rocblas_int batch_count)#
BLAS Level 2 API
hemv_strided_batched performs one of the matrix-vector operations:
y_i := alpha*A_i*x_i + beta*y_i where alpha and beta are scalars, x_i and y_i are n element vectors and A_i is an n by n Hermitian matrix, for each batch in i = [1, batch_count].
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill]
rocblas_fill_upper: the upper triangular part of the Hermitian matrix A is supplied.
rocblas_fill_lower: the lower triangular part of the Hermitian matrix A is supplied.
n – [in] [rocblas_int] the order of each matrix A_i.
alpha – [in] device pointer or host pointer to scalar alpha.
A – [in] device array of device pointers storing each matrix A_i of dimension (lda, n).
if uplo == rocblas_fill_upper: The upper triangular part of each A_i must contain the upper triangular part of a Hermitian matrix. The lower triangular part of each A_i will not be referenced. if uplo == rocblas_fill_lower: The lower triangular part of each A_i must contain the lower triangular part of a Hermitian matrix. The upper triangular part of each A_i will not be referenced. As a Hermitian matrix, the imaginary part of the main diagonal of each A_i will not be referenced and is assumed to be == 0.
lda – [in] [rocblas_int] specifies the leading dimension of each A_i. must be >= max(1, n).
stride_A – [in] [rocblas_stride] stride from the start of one (A_i) to the next (A_i+1).
x – [in] device array of device pointers storing each vector x_i.
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i.
stride_x – [in] [rocblas_stride] stride from the start of one vector (x_i) and the next one (x_i+1).
beta – [in] device pointer or host pointer to scalar beta.
y – [inout] device array of device pointers storing each vector y_i.
incy – [in] [rocblas_int] specifies the increment for the elements of y.
stride_y – [in] [rocblas_stride] stride from the start of one vector (y_i) and the next one (y_i+1).
batch_count – [in] [rocblas_int] number of instances in the batch.
rocblas_Xhbmv + batched, strided_batched#
-
rocblas_status rocblas_chbmv(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, rocblas_int k, const rocblas_float_complex *alpha, const rocblas_float_complex *A, rocblas_int lda, const rocblas_float_complex *x, rocblas_int incx, const rocblas_float_complex *beta, rocblas_float_complex *y, rocblas_int incy)#
-
rocblas_status rocblas_zhbmv(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, rocblas_int k, const rocblas_double_complex *alpha, const rocblas_double_complex *A, rocblas_int lda, const rocblas_double_complex *x, rocblas_int incx, const rocblas_double_complex *beta, rocblas_double_complex *y, rocblas_int incy)#
BLAS Level 2 API
hbmv performs the matrix-vector operations:
y := alpha*A*x + beta*y where alpha and beta are scalars, x and y are n element vectors and A is an n by n Hermitian band matrix, with k super-diagonals.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill]
rocblas_fill_upper: The upper triangular part of A is being supplied.
rocblas_fill_lower: The lower triangular part of A is being supplied.
n – [in] [rocblas_int] the order of the matrix A.
k – [in] [rocblas_int] the number of super-diagonals of the matrix A. Must be >= 0.
alpha – [in] device pointer or host pointer to scalar alpha.
A – [in] device pointer storing matrix A. Of dimension (lda, n).
if uplo == rocblas_fill_upper: The leading (k + 1) by n part of A must contain the upper triangular band part of the Hermitian matrix, with the leading diagonal in row (k + 1), the first super-diagonal on the RHS of row k, etc. The top left k by x triangle of A will not be referenced. Ex (upper, lda = n = 4, k = 1): A Represented matrix (0,0) (5,9) (6,8) (7,7) (1, 0) (5, 9) (0, 0) (0, 0) (1,0) (2,0) (3,0) (4,0) (5,-9) (2, 0) (6, 8) (0, 0) (0,0) (0,0) (0,0) (0,0) (0, 0) (6,-8) (3, 0) (7, 7) (0,0) (0,0) (0,0) (0,0) (0, 0) (0, 0) (7,-7) (4, 0) if uplo == rocblas_fill_lower: The leading (k + 1) by n part of A must contain the lower triangular band part of the Hermitian matrix, with the leading diagonal in row (1), the first sub-diagonal on the LHS of row 2, etc. The bottom right k by k triangle of A will not be referenced. Ex (lower, lda = 2, n = 4, k = 1): A Represented matrix (1,0) (2,0) (3,0) (4,0) (1, 0) (5,-9) (0, 0) (0, 0) (5,9) (6,8) (7,7) (0,0) (5, 9) (2, 0) (6,-8) (0, 0) (0, 0) (6, 8) (3, 0) (7,-7) (0, 0) (0, 0) (7, 7) (4, 0) As a Hermitian matrix, the imaginary part of the main diagonal of A will not be referenced and is assumed to be == 0.
lda – [in] [rocblas_int] specifies the leading dimension of A. must be >= k + 1.
x – [in] device pointer storing vector x.
incx – [in] [rocblas_int] specifies the increment for the elements of x.
beta – [in] device pointer or host pointer to scalar beta.
y – [inout] device pointer storing vector y.
incy – [in] [rocblas_int] specifies the increment for the elements of y.
-
rocblas_status rocblas_chbmv_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, rocblas_int k, const rocblas_float_complex *alpha, const rocblas_float_complex *const A[], rocblas_int lda, const rocblas_float_complex *const x[], rocblas_int incx, const rocblas_float_complex *beta, rocblas_float_complex *const y[], rocblas_int incy, rocblas_int batch_count)#
-
rocblas_status rocblas_zhbmv_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, rocblas_int k, const rocblas_double_complex *alpha, const rocblas_double_complex *const A[], rocblas_int lda, const rocblas_double_complex *const x[], rocblas_int incx, const rocblas_double_complex *beta, rocblas_double_complex *const y[], rocblas_int incy, rocblas_int batch_count)#
BLAS Level 2 API
hbmv_batched performs one of the matrix-vector operations:
y_i := alpha*A_i*x_i + beta*y_i where alpha and beta are scalars, x_i and y_i are n element vectors and A_i is an n by n Hermitian band matrix with k super-diagonals, for each batch in i = [1, batch_count].
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill]
rocblas_fill_upper: The upper triangular part of each A_i is being supplied.
rocblas_fill_lower: The lower triangular part of each A_i is being supplied.
n – [in] [rocblas_int] the order of each matrix A_i.
k – [in] [rocblas_int] the number of super-diagonals of each matrix A_i. Must be >= 0.
alpha – [in] device pointer or host pointer to scalar alpha.
A – [in] device array of device pointers storing each matrix_i A of dimension (lda, n).
if uplo == rocblas_fill_upper: The leading (k + 1) by n part of each A_i must contain the upper triangular band part of the Hermitian matrix, with the leading diagonal in row (k + 1), the first super-diagonal on the RHS of row k, etc. The top left k by x triangle of each A_i will not be referenced. Ex (upper, lda = n = 4, k = 1): A Represented matrix (0,0) (5,9) (6,8) (7,7) (1, 0) (5, 9) (0, 0) (0, 0) (1,0) (2,0) (3,0) (4,0) (5,-9) (2, 0) (6, 8) (0, 0) (0,0) (0,0) (0,0) (0,0) (0, 0) (6,-8) (3, 0) (7, 7) (0,0) (0,0) (0,0) (0,0) (0, 0) (0, 0) (7,-7) (4, 0) if uplo == rocblas_fill_lower: The leading (k + 1) by n part of each A_i must contain the lower triangular band part of the Hermitian matrix, with the leading diagonal in row (1), the first sub-diagonal on the LHS of row 2, etc. The bottom right k by k triangle of each A_i will not be referenced. Ex (lower, lda = 2, n = 4, k = 1): A Represented matrix (1,0) (2,0) (3,0) (4,0) (1, 0) (5,-9) (0, 0) (0, 0) (5,9) (6,8) (7,7) (0,0) (5, 9) (2, 0) (6,-8) (0, 0) (0, 0) (6, 8) (3, 0) (7,-7) (0, 0) (0, 0) (7, 7) (4, 0) As a Hermitian matrix, the imaginary part of the main diagonal of each A_i will not be referenced and is assumed to be == 0.
lda – [in] [rocblas_int] specifies the leading dimension of each A_i. must be >= max(1, n).
x – [in] device array of device pointers storing each vector x_i.
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i.
beta – [in] device pointer or host pointer to scalar beta.
y – [inout] device array of device pointers storing each vector y_i.
incy – [in] [rocblas_int] specifies the increment for the elements of y.
batch_count – [in] [rocblas_int] number of instances in the batch.
-
rocblas_status rocblas_chbmv_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, rocblas_int k, const rocblas_float_complex *alpha, const rocblas_float_complex *A, rocblas_int lda, rocblas_stride stride_A, const rocblas_float_complex *x, rocblas_int incx, rocblas_stride stride_x, const rocblas_float_complex *beta, rocblas_float_complex *y, rocblas_int incy, rocblas_stride stride_y, rocblas_int batch_count)#
-
rocblas_status rocblas_zhbmv_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, rocblas_int k, const rocblas_double_complex *alpha, const rocblas_double_complex *A, rocblas_int lda, rocblas_stride stride_A, const rocblas_double_complex *x, rocblas_int incx, rocblas_stride stride_x, const rocblas_double_complex *beta, rocblas_double_complex *y, rocblas_int incy, rocblas_stride stride_y, rocblas_int batch_count)#
BLAS Level 2 API
hbmv_strided_batched performs one of the matrix-vector operations:
y_i := alpha*A_i*x_i + beta*y_i where alpha and beta are scalars, x_i and y_i are n element vectors and A_i is an n by n Hermitian band matrix with k super-diagonals, for each batch in i = [1, batch_count].
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill]
rocblas_fill_upper: The upper triangular part of each A_i is being supplied.
rocblas_fill_lower: The lower triangular part of each A_i is being supplied.
n – [in] [rocblas_int] the order of each matrix A_i.
k – [in] [rocblas_int] the number of super-diagonals of each matrix A_i. Must be >= 0.
alpha – [in] device pointer or host pointer to scalar alpha.
A – [in] device array pointing to the first matrix A_1. Each A_i is of dimension (lda, n).
if uplo == rocblas_fill_upper: The leading (k + 1) by n part of each A_i must contain the upper triangular band part of the Hermitian matrix, with the leading diagonal in row (k + 1), the first super-diagonal on the RHS of row k, etc. The top left k by x triangle of each A_i will not be referenced. Ex (upper, lda = n = 4, k = 1): A Represented matrix (0,0) (5,9) (6,8) (7,7) (1, 0) (5, 9) (0, 0) (0, 0) (1,0) (2,0) (3,0) (4,0) (5,-9) (2, 0) (6, 8) (0, 0) (0,0) (0,0) (0,0) (0,0) (0, 0) (6,-8) (3, 0) (7, 7) (0,0) (0,0) (0,0) (0,0) (0, 0) (0, 0) (7,-7) (4, 0) if uplo == rocblas_fill_lower: The leading (k + 1) by n part of each A_i must contain the lower triangular band part of the Hermitian matrix, with the leading diagonal in row (1), the first sub-diagonal on the LHS of row 2, etc. The bottom right k by k triangle of each A_i will not be referenced. Ex (lower, lda = 2, n = 4, k = 1): A Represented matrix (1,0) (2,0) (3,0) (4,0) (1, 0) (5,-9) (0, 0) (0, 0) (5,9) (6,8) (7,7) (0,0) (5, 9) (2, 0) (6,-8) (0, 0) (0, 0) (6, 8) (3, 0) (7,-7) (0, 0) (0, 0) (7, 7) (4, 0) As a Hermitian matrix, the imaginary part of the main diagonal of each A_i will not be referenced and is assumed to be == 0.
lda – [in] [rocblas_int] specifies the leading dimension of each A_i. must be >= max(1, n).
stride_A – [in] [rocblas_stride] stride from the start of one matrix (A_i) and the next one (A_i+1).
x – [in] device array pointing to the first vector y_1.
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i.
stride_x – [in] [rocblas_stride] stride from the start of one vector (x_i) and the next one (x_i+1).
beta – [in] device pointer or host pointer to scalar beta.
y – [inout] device array pointing to the first vector y_1.
incy – [in] [rocblas_int] specifies the increment for the elements of y.
stride_y – [in] [rocblas_stride] stride from the start of one vector (y_i) and the next one (y_i+1).
batch_count – [in] [rocblas_int] number of instances in the batch.
rocblas_Xhpmv + batched, strided_batched#
-
rocblas_status rocblas_chpmv(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *AP, const rocblas_float_complex *x, rocblas_int incx, const rocblas_float_complex *beta, rocblas_float_complex *y, rocblas_int incy)#
-
rocblas_status rocblas_zhpmv(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *AP, const rocblas_double_complex *x, rocblas_int incx, const rocblas_double_complex *beta, rocblas_double_complex *y, rocblas_int incy)#
BLAS Level 2 API
hpmv performs the matrix-vector operation:
y := alpha*A*x + beta*y where alpha and beta are scalars, x and y are n element vectors and A is an n by n Hermitian matrix, supplied in packed form (see description below).
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill]
rocblas_fill_upper: the upper triangular part of the Hermitian matrix A is supplied in AP.
rocblas_fill_lower: the lower triangular part of the Hermitian matrix A is supplied in AP.
n – [in] [rocblas_int] the order of the matrix A. Must be >= 0.
alpha – [in] device pointer or host pointer to scalar alpha.
AP – [in] device pointer storing the packed version of the specified triangular portion of the Hermitian matrix A. Of at least size ((n * (n + 1)) / 2).
Note that the imaginary part of the diagonal elements are not accessed and are assumed to be 0.if uplo == rocblas_fill_upper: The upper triangular portion of the Hermitian matrix A is supplied. The matrix is compacted so that AP contains the triangular portion column-by-column so that: AP(0) = A(0,0) AP(1) = A(0,1) AP(2) = A(1,1), etc. Ex: (rocblas_fill_upper; n = 3) (1, 0) (2, 1) (3, 2) (2,-1) (4, 0) (5,-1) ---> [(1,0),(2,1),(4,0),(3,2),(5,-1),(6,0)] (3,-2) (5, 1) (6, 0) if uplo == rocblas_fill_lower: The lower triangular portion of the Hermitian matrix A is supplied. The matrix is compacted so that AP contains the triangular portion column-by-column so that: AP(0) = A(0,0) AP(1) = A(1,0) AP(2) = A(2,1), etc. Ex: (rocblas_fill_lower; n = 3) (1, 0) (2, 1) (3, 2) (2,-1) (4, 0) (5,-1) ---> [(1,0),(2,-1),(3,-2),(4,0),(5,1),(6,0)] (3,-2) (5, 1) (6, 0)
x – [in] device pointer storing vector x.
incx – [in] [rocblas_int] specifies the increment for the elements of x.
beta – [in] device pointer or host pointer to scalar beta.
y – [inout] device pointer storing vector y.
incy – [in] [rocblas_int] specifies the increment for the elements of y.
-
rocblas_status rocblas_chpmv_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *const AP[], const rocblas_float_complex *const x[], rocblas_int incx, const rocblas_float_complex *beta, rocblas_float_complex *const y[], rocblas_int incy, rocblas_int batch_count)#
-
rocblas_status rocblas_zhpmv_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *const AP[], const rocblas_double_complex *const x[], rocblas_int incx, const rocblas_double_complex *beta, rocblas_double_complex *const y[], rocblas_int incy, rocblas_int batch_count)#
BLAS Level 2 API
hpmv_batched performs the matrix-vector operation:
y_i := alpha*A_i*x_i + beta*y_i where alpha and beta are scalars, x_i and y_i are n element vectors and A_i is an n by n Hermitian matrix, supplied in packed form (see description below), for each batch in i = [1, batch_count].
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill]
rocblas_fill_upper: the upper triangular part of each Hermitian matrix A_i is supplied in AP.
rocblas_fill_lower: the lower triangular part of each Hermitian matrix A_i is supplied in AP.
n – [in] [rocblas_int] the order of each matrix A_i.
alpha – [in] device pointer or host pointer to scalar alpha.
AP – [in] device pointer of device pointers storing the packed version of the specified triangular portion of each Hermitian matrix A_i. Each A_i is of at least size ((n * (n + 1)) / 2).
if uplo == rocblas_fill_upper: The upper triangular portion of each Hermitian matrix A_i is supplied. The matrix is compacted so that each AP_i contains the triangular portion column-by-column so that: AP(0) = A(0,0) AP(1) = A(0,1) AP(2) = A(1,1), etc. Ex: (rocblas_fill_upper; n = 3) (1, 0) (2, 1) (3, 2) (2,-1) (4, 0) (5,-1) ---> [(1,0),(2,1),(4,0),(3,2),(5,-1),(6,0)] (3,-2) (5, 1) (6, 0) if uplo == rocblas_fill_lower: The lower triangular portion of each Hermitian matrix A_i is supplied. The matrix is compacted so that each AP_i contains the triangular portion column-by-column so that: AP(0) = A(0,0) AP(1) = A(1,0) AP(2) = A(2,1), etc. Ex: (rocblas_fill_lower; n = 3) (1, 0) (2, 1) (3, 2) (2,-1) (4, 0) (5,-1) ---> [(1,0),(2,-1),(3,-2),(4,0),(5,1),(6,0)] (3,-2) (5, 1) (6, 0) Note that the imaginary part of the diagonal elements are not accessed and are assumed to be 0.
x – [in] device array of device pointers storing each vector x_i.
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i.
beta – [in] device pointer or host pointer to scalar beta.
y – [inout] device array of device pointers storing each vector y_i.
incy – [in] [rocblas_int] specifies the increment for the elements of y.
batch_count – [in] [rocblas_int] number of instances in the batch.
-
rocblas_status rocblas_chpmv_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *AP, rocblas_stride stride_A, const rocblas_float_complex *x, rocblas_int incx, rocblas_stride stride_x, const rocblas_float_complex *beta, rocblas_float_complex *y, rocblas_int incy, rocblas_stride stride_y, rocblas_int batch_count)#
-
rocblas_status rocblas_zhpmv_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *AP, rocblas_stride stride_A, const rocblas_double_complex *x, rocblas_int incx, rocblas_stride stride_x, const rocblas_double_complex *beta, rocblas_double_complex *y, rocblas_int incy, rocblas_stride stride_y, rocblas_int batch_count)#
BLAS Level 2 API
hpmv_strided_batched performs the matrix-vector operation:
y_i := alpha*A_i*x_i + beta*y_i where alpha and beta are scalars, x_i and y_i are n element vectors and A_i is an n by n Hermitian matrix, supplied in packed form (see description below), for each batch in i = [1, batch_count].
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill]
rocblas_fill_upper: the upper triangular part of each Hermitian matrix A_i is supplied in AP.
rocblas_fill_lower: the lower triangular part of each Hermitian matrix A_i is supplied in AP.
n – [in] [rocblas_int] the order of each matrix A_i.
alpha – [in] device pointer or host pointer to scalar alpha.
AP – [in] device pointer pointing to the beginning of the first matrix (AP_1). Stores the packed version of the specified triangular portion of each Hermitian matrix AP_i of size ((n * (n + 1)) / 2).
if uplo == rocblas_fill_upper: The upper triangular portion of each Hermitian matrix A_i is supplied. The matrix is compacted so that each AP_i contains the triangular portion column-by-column so that: AP(0) = A(0,0) AP(1) = A(0,1) AP(2) = A(1,1), etc. Ex: (rocblas_fill_upper; n = 3) (1, 0) (2, 1) (3, 2) (2,-1) (4, 0) (5,-1) ---> [(1,0),(2,1),(4,0),(3,2),(5,-1),(6,0)] (3,-2) (5, 1) (6, 0) if uplo == rocblas_fill_lower: The lower triangular portion of each Hermitian matrix A_i is supplied. The matrix is compacted so that each AP_i contains the triangular portion column-by-column so that: AP(0) = A(0,0) AP(1) = A(1,0) AP(2) = A(2,1), etc. Ex: (rocblas_fill_lower; n = 3) (1, 0) (2, 1) (3, 2) (2,-1) (4, 0) (5,-1) ---> [(1,0),(2,-1),(3,-2),(4,0),(5,1),(6,0)] (3,-2) (5, 1) (6, 0) Note that the imaginary part of the diagonal elements are not accessed and are assumed to be 0.
stride_A – [in] [rocblas_stride] stride from the start of one matrix (AP_i) and the next one (AP_i+1).
x – [in] device array pointing to the beginning of the first vector (x_1).
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i.
stride_x – [in] [rocblas_stride] stride from the start of one vector (x_i) and the next one (x_i+1).
beta – [in] device pointer or host pointer to scalar beta.
y – [inout] device array pointing to the beginning of the first vector (y_1).
incy – [in] [rocblas_int] specifies the increment for the elements of y.
stride_y – [in] [rocblas_stride] stride from the start of one vector (y_i) and the next one (y_i+1).
batch_count – [in] [rocblas_int] number of instances in the batch.
rocblas_Xher + batched, strided_batched#
-
rocblas_status rocblas_cher(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const float *alpha, const rocblas_float_complex *x, rocblas_int incx, rocblas_float_complex *A, rocblas_int lda)#
-
rocblas_status rocblas_zher(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const double *alpha, const rocblas_double_complex *x, rocblas_int incx, rocblas_double_complex *A, rocblas_int lda)#
BLAS Level 2 API
her performs the matrix-vector operations:
A := A + alpha*x*x**H where alpha is a real scalar, x is a vector, and A is an n by n Hermitian matrix.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill] specifies whether the upper ‘rocblas_fill_upper’ or lower ‘rocblas_fill_lower’
rocblas_fill_upper: The upper triangular part of A is supplied in A.
rocblas_fill_lower: The lower triangular part of A is supplied in A.
n – [in] [rocblas_int] the number of rows and columns of matrix A. Must be at least 0.
alpha – [in] device pointer or host pointer to scalar alpha.
x – [in] device pointer storing vector x.
incx – [in] [rocblas_int] specifies the increment for the elements of x.
A – [inout] device pointer storing the specified triangular portion of the Hermitian matrix A. Of size (lda * n).
if uplo == rocblas_fill_upper: The upper triangular portion of the Hermitian matrix A is supplied. The lower triangluar portion will not be touched. if uplo == rocblas_fill_lower: The lower triangular portion of the Hermitian matrix A is supplied. The upper triangular portion will not be touched. Note that the imaginary part of the diagonal elements are not accessed and are assumed to be 0.
lda – [in] [rocblas_int] specifies the leading dimension of A. Must be at least max(1, n).
-
rocblas_status rocblas_cher_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const float *alpha, const rocblas_float_complex *const x[], rocblas_int incx, rocblas_float_complex *const A[], rocblas_int lda, rocblas_int batch_count)#
-
rocblas_status rocblas_zher_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const double *alpha, const rocblas_double_complex *const x[], rocblas_int incx, rocblas_double_complex *const A[], rocblas_int lda, rocblas_int batch_count)#
BLAS Level 2 API
her_batched performs the matrix-vector operations:
A_i := A_i + alpha*x_i*x_i**H where alpha is a real scalar, x_i is a vector, and A_i is an n by n symmetric matrix, for i = 1, ..., batch_count.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill] specifies whether the upper ‘rocblas_fill_upper’ or lower ‘rocblas_fill_lower’
rocblas_fill_upper: The upper triangular part of each A_i is supplied in A.
rocblas_fill_lower: The lower triangular part of each A_i is supplied in A.
n – [in] [rocblas_int] the number of rows and columns of each matrix A_i. Must be at least 0.
alpha – [in] device pointer or host pointer to scalar alpha.
x – [in] device array of device pointers storing each vector x_i.
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i.
A – [inout] device array of device pointers storing the specified triangular portion of each Hermitian matrix A_i of at least size ((n * (n + 1)) / 2). Array is of at least size batch_count.
if uplo == rocblas_fill_upper: The upper triangular portion of each Hermitian matrix A_i is supplied. The lower triangular portion of each A_i will not be touched. if uplo == rocblas_fill_lower: The lower triangular portion of each Hermitian matrix A_i is supplied. The upper triangular portion of each A_i will not be touched. Note that the imaginary part of the diagonal elements are not accessed and are assumed to be 0.
lda – [in] [rocblas_int] specifies the leading dimension of each A_i. Must be at least max(1, n).
batch_count – [in] [rocblas_int] number of instances in the batch.
-
rocblas_status rocblas_cher_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const float *alpha, const rocblas_float_complex *x, rocblas_int incx, rocblas_stride stride_x, rocblas_float_complex *A, rocblas_int lda, rocblas_stride stride_A, rocblas_int batch_count)#
-
rocblas_status rocblas_zher_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const double *alpha, const rocblas_double_complex *x, rocblas_int incx, rocblas_stride stride_x, rocblas_double_complex *A, rocblas_int lda, rocblas_stride stride_A, rocblas_int batch_count)#
BLAS Level 2 API
her_strided_batched performs the matrix-vector operations:
A_i := A_i + alpha*x_i*x_i**H where alpha is a real scalar, x_i is a vector, and A_i is an n by n Hermitian matrix, for i = 1, ..., batch_count.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill] specifies whether the upper ‘rocblas_fill_upper’ or lower ‘rocblas_fill_lower’
rocblas_fill_upper: The upper triangular part of each A_i is supplied in A.
rocblas_fill_lower: The lower triangular part of each A_i is supplied in A.
n – [in] [rocblas_int] the number of rows and columns of each matrix A_i. Must be at least 0.
alpha – [in] device pointer or host pointer to scalar alpha.
x – [in] device pointer pointing to the first vector (x_1).
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i.
stride_x – [in] [rocblas_stride] stride from the start of one vector (x_i) and the next one (x_i+1).
A – [inout] device array of device pointers storing the specified triangular portion of each Hermitian matrix A_i. Points to the first matrix (A_1).
Note that the imaginary part of the diagonal elements are not accessed and are assumed to be 0.if uplo == rocblas_fill_upper: The upper triangular portion of each Hermitian matrix A_i is supplied. The lower triangular portion of each A_i will not be touched. if uplo == rocblas_fill_lower: The lower triangular portion of each Hermitian matrix A_i is supplied. The upper triangular portion of each A_i will not be touched.
lda – [in] [rocblas_int] specifies the leading dimension of each A_i.
stride_A – [in] [rocblas_stride] stride from the start of one (A_i) and the next (A_i+1).
batch_count – [in] [rocblas_int] number of instances in the batch.
rocblas_Xher2 + batched, strided_batched#
-
rocblas_status rocblas_cher2(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *x, rocblas_int incx, const rocblas_float_complex *y, rocblas_int incy, rocblas_float_complex *A, rocblas_int lda)#
-
rocblas_status rocblas_zher2(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *x, rocblas_int incx, const rocblas_double_complex *y, rocblas_int incy, rocblas_double_complex *A, rocblas_int lda)#
BLAS Level 2 API
her2 performs the matrix-vector operations:
A := A + alpha*x*y**H + conj(alpha)*y*x**H where alpha is a complex scalar, x and y are vectors, and A is an n by n Hermitian matrix.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill] specifies whether the upper ‘rocblas_fill_upper’ or lower ‘rocblas_fill_lower’
rocblas_fill_upper: The upper triangular part of A is supplied.
rocblas_fill_lower: The lower triangular part of A is supplied.
n – [in] [rocblas_int] the number of rows and columns of matrix A. Must be at least 0.
alpha – [in] device pointer or host pointer to scalar alpha.
x – [in] device pointer storing vector x.
incx – [in] [rocblas_int] specifies the increment for the elements of x.
y – [in] device pointer storing vector y.
incy – [in] [rocblas_int] specifies the increment for the elements of y.
A – [inout] device pointer storing the specified triangular portion of the Hermitian matrix A. Of size (lda, n).
Note that the imaginary part of the diagonal elements are not accessed and are assumed to be 0.if uplo == rocblas_fill_upper: The upper triangular portion of the Hermitian matrix A is supplied. The lower triangular portion of A will not be touched. if uplo == rocblas_fill_lower: The lower triangular portion of the Hermitian matrix A is supplied. The upper triangular portion of A will not be touched.
lda – [in] [rocblas_int] specifies the leading dimension of A. Must be at least max(lda, 1).
-
rocblas_status rocblas_cher2_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *const x[], rocblas_int incx, const rocblas_float_complex *const y[], rocblas_int incy, rocblas_float_complex *const A[], rocblas_int lda, rocblas_int batch_count)#
-
rocblas_status rocblas_zher2_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *const x[], rocblas_int incx, const rocblas_double_complex *const y[], rocblas_int incy, rocblas_double_complex *const A[], rocblas_int lda, rocblas_int batch_count)#
BLAS Level 2 API
her2_batched performs the matrix-vector operations:
A_i := A_i + alpha*x_i*y_i**H + conj(alpha)*y_i*x_i**H where alpha is a complex scalar, x_i and y_i are vectors, and A_i is an n by n Hermitian matrix for each batch in i = [1, batch_count].
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill] specifies whether the upper ‘rocblas_fill_upper’ or lower ‘rocblas_fill_lower’
rocblas_fill_upper: The upper triangular part of each A_i is supplied.
rocblas_fill_lower: The lower triangular part of each A_i is supplied.
n – [in] [rocblas_int] the number of rows and columns of each matrix A_i. Must be at least 0.
alpha – [in] device pointer or host pointer to scalar alpha.
x – [in] device array of device pointers storing each vector x_i.
incx – [in] [rocblas_int] specifies the increment for the elements of x.
y – [in] device array of device pointers storing each vector y_i.
incy – [in] [rocblas_int] specifies the increment for the elements of each y_i.
A – [inout] device array of device pointers storing the specified triangular portion of each Hermitian matrix A_i of size (lda, n).
Note that the imaginary part of the diagonal elements are not accessed and are assumed to be 0.if uplo == rocblas_fill_upper: The upper triangular portion of each Hermitian matrix A_i is supplied. The lower triangular portion of each A_i will not be touched. if uplo == rocblas_fill_lower: The lower triangular portion of each Hermitian matrix A_i is supplied. The upper triangular portion of each A_i will not be touched.
lda – [in] [rocblas_int] specifies the leading dimension of each A_i. Must be at least max(lda, 1).
batch_count – [in] [rocblas_int] number of instances in the batch.
-
rocblas_status rocblas_cher2_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *x, rocblas_int incx, rocblas_stride stride_x, const rocblas_float_complex *y, rocblas_int incy, rocblas_stride stride_y, rocblas_float_complex *A, rocblas_int lda, rocblas_stride stride_A, rocblas_int batch_count)#
-
rocblas_status rocblas_zher2_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *x, rocblas_int incx, rocblas_stride stride_x, const rocblas_double_complex *y, rocblas_int incy, rocblas_stride stride_y, rocblas_double_complex *A, rocblas_int lda, rocblas_stride stride_A, rocblas_int batch_count)#
BLAS Level 2 API
her2_strided_batched performs the matrix-vector operations:
A_i := A_i + alpha*x_i*y_i**H + conj(alpha)*y_i*x_i**H where alpha is a complex scalar, x_i and y_i are vectors, and A_i is an n by n Hermitian matrix for each batch in i = [1, batch_count].
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill] specifies whether the upper ‘rocblas_fill_upper’ or lower ‘rocblas_fill_lower’
rocblas_fill_upper: The upper triangular part of each A_i is supplied.
rocblas_fill_lower: The lower triangular part of each A_i is supplied.
n – [in] [rocblas_int] the number of rows and columns of each matrix A_i. Must be at least 0.
alpha – [in] device pointer or host pointer to scalar alpha.
x – [in] device pointer pointing to the first vector x_1.
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i.
stride_x – [in] [rocblas_stride] specifies the stride between the beginning of one vector (x_i) and the next (x_i+1).
y – [in] device pointer pointing to the first vector y_i.
incy – [in] [rocblas_int] specifies the increment for the elements of each y_i.
stride_y – [in] [rocblas_stride] specifies the stride between the beginning of one vector (y_i) and the next (y_i+1).
A – [inout] device pointer pointing to the first matrix (A_1). Stores the specified triangular portion of each Hermitian matrix A_i.
Note that the imaginary part of the diagonal elements are not accessed and are assumed to be 0.if uplo == rocblas_fill_upper: The upper triangular portion of each Hermitian matrix A_i is supplied. The lower triangular portion of each A_i will not be touched. if uplo == rocblas_fill_lower: The lower triangular portion of each Hermitian matrix A_i is supplied. The upper triangular portion of each A_i will not be touched.
lda – [in] [rocblas_int] specifies the leading dimension of each A_i. Must be at least max(lda, 1).
stride_A – [in] [rocblas_stride] specifies the stride between the beginning of one matrix (A_i) and the next (A_i+1).
batch_count – [in] [rocblas_int] number of instances in the batch.
rocblas_Xhpr + batched, strided_batched#
-
rocblas_status rocblas_chpr(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const float *alpha, const rocblas_float_complex *x, rocblas_int incx, rocblas_float_complex *AP)#
-
rocblas_status rocblas_zhpr(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const double *alpha, const rocblas_double_complex *x, rocblas_int incx, rocblas_double_complex *AP)#
BLAS Level 2 API
hpr performs the matrix-vector operations:
A := A + alpha*x*x**H where alpha is a real scalar, x is a vector, and A is an n by n Hermitian matrix, supplied in packed form.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill] specifies whether the upper ‘rocblas_fill_upper’ or lower ‘rocblas_fill_lower’
rocblas_fill_upper: The upper triangular part of A is supplied in AP.
rocblas_fill_lower: The lower triangular part of A is supplied in AP.
n – [in] [rocblas_int] the number of rows and columns of matrix A. Must be at least 0.
alpha – [in] device pointer or host pointer to scalar alpha.
x – [in] device pointer storing vector x.
incx – [in] [rocblas_int] specifies the increment for the elements of x.
AP – [inout] device pointer storing the packed version of the specified triangular portion of the Hermitian matrix A. Of at least size ((n * (n + 1)) / 2).
if uplo == rocblas_fill_upper: The upper triangular portion of the Hermitian matrix A is supplied. The matrix is compacted so that AP contains the triangular portion column-by-column so that: AP(0) = A(0,0) AP(1) = A(0,1) AP(2) = A(1,1), etc. Ex: (rocblas_fill_upper; n = 3) (1, 0) (2, 1) (4,9) (2,-1) (3, 0) (5,3) ---> [(1,0),(2,1),(3,0),(4,9),(5,3),(6,0)] (4,-9) (5,-3) (6,0) if uplo == rocblas_fill_lower: The lower triangular portion of the Hermitian matrix A is supplied. The matrix is compacted so that AP contains the triangular portion column-by-column so that: AP(0) = A(0,0) AP(1) = A(1,0) AP(2) = A(2,1), etc. Ex: (rocblas_fill_lower; n = 3) (1, 0) (2, 1) (4,9) (2,-1) (3, 0) (5,3) ---> [(1,0),(2,-1),(4,-9),(3,0),(5,-3),(6,0)] (4,-9) (5,-3) (6,0) Note that the imaginary part of the diagonal elements are not accessed and are assumed to be 0.
-
rocblas_status rocblas_chpr_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const float *alpha, const rocblas_float_complex *const x[], rocblas_int incx, rocblas_float_complex *const AP[], rocblas_int batch_count)#
-
rocblas_status rocblas_zhpr_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const double *alpha, const rocblas_double_complex *const x[], rocblas_int incx, rocblas_double_complex *const AP[], rocblas_int batch_count)#
BLAS Level 2 API
hpr_batched performs the matrix-vector operations:
A_i := A_i + alpha*x_i*x_i**H where alpha is a real scalar, x_i is a vector, and A_i is an n by n symmetric matrix, supplied in packed form, for i = 1, ..., batch_count.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill] specifies whether the upper ‘rocblas_fill_upper’ or lower ‘rocblas_fill_lower’
rocblas_fill_upper: The upper triangular part of each A_i is supplied in AP.
rocblas_fill_lower: The lower triangular part of each A_i is supplied in AP.
n – [in] [rocblas_int] the number of rows and columns of each matrix A_i. Must be at least 0.
alpha – [in] device pointer or host pointer to scalar alpha.
x – [in] device array of device pointers storing each vector x_i.
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i.
AP – [inout] device array of device pointers storing the packed version of the specified triangular portion of each Hermitian matrix A_i of at least size ((n * (n + 1)) / 2). Array is of at least size batch_count.
if uplo == rocblas_fill_upper: The upper triangular portion of each Hermitian matrix A_i is supplied. The matrix is compacted so that AP contains the triangular portion column-by-column so that: AP(0) = A(0,0) AP(1) = A(0,1) AP(2) = A(1,1), etc. Ex: (rocblas_fill_upper; n = 3) (1, 0) (2, 1) (4,9) (2,-1) (3, 0) (5,3) ---> [(1,0),(2,1),(3,0),(4,9),(5,3),(6,0)] (4,-9) (5,-3) (6,0) if uplo == rocblas_fill_lower: The lower triangular portion of each Hermitian matrix A_i is supplied. The matrix is compacted so that AP contains the triangular portion column-by-column so that: AP(0) = A(0,0) AP(1) = A(1,0) AP(2) = A(2,1), etc. Ex: (rocblas_fill_lower; n = 3) (1, 0) (2, 1) (4,9) (2,-1) (3, 0) (5,3) ---> [(1,0),(2,-1),(4,-9),(3,0),(5,-3),(6,0)] (4,-9) (5,-3) (6,0) Note that the imaginary part of the diagonal elements are not accessed and are assumed to be 0.
batch_count – [in] [rocblas_int] number of instances in the batch.
-
rocblas_status rocblas_chpr_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const float *alpha, const rocblas_float_complex *x, rocblas_int incx, rocblas_stride stride_x, rocblas_float_complex *AP, rocblas_stride stride_A, rocblas_int batch_count)#
-
rocblas_status rocblas_zhpr_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const double *alpha, const rocblas_double_complex *x, rocblas_int incx, rocblas_stride stride_x, rocblas_double_complex *AP, rocblas_stride stride_A, rocblas_int batch_count)#
BLAS Level 2 API
hpr_strided_batched performs the matrix-vector operations:
A_i := A_i + alpha*x_i*x_i**H where alpha is a real scalar, x_i is a vector, and A_i is an n by n symmetric matrix, supplied in packed form, for i = 1, ..., batch_count.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill] specifies whether the upper ‘rocblas_fill_upper’ or lower ‘rocblas_fill_lower’
rocblas_fill_upper: The upper triangular part of each A_i is supplied in AP.
rocblas_fill_lower: The lower triangular part of each A_i is supplied in AP.
n – [in] [rocblas_int] the number of rows and columns of each matrix A_i. Must be at least 0.
alpha – [in] device pointer or host pointer to scalar alpha.
x – [in] device pointer pointing to the first vector (x_1).
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i.
stride_x – [in] [rocblas_stride] stride from the start of one vector (x_i) and the next one (x_i+1).
AP – [inout] device array of device pointers storing the packed version of the specified triangular portion of each Hermitian matrix A_i. Points to the first matrix (A_1).
if uplo == rocblas_fill_upper: The upper triangular portion of each Hermitian matrix A_i is supplied. The matrix is compacted so that AP contains the triangular portion column-by-column so that: AP(0) = A(0,0) AP(1) = A(0,1) AP(2) = A(1,1), etc. Ex: (rocblas_fill_upper; n = 3) (1, 0) (2, 1) (4,9) (2,-1) (3, 0) (5,3) ---> [(1,0),(2,1),(3,0),(4,9),(5,3),(6,0)] (4,-9) (5,-3) (6,0) if uplo == rocblas_fill_lower: The lower triangular portion of each Hermitian matrix A_i is supplied. The matrix is compacted so that AP contains the triangular portion column-by-column so that: AP(0) = A(0,0) AP(1) = A(1,0) AP(2) = A(2,1), etc. Ex: (rocblas_fill_lower; n = 3) (1, 0) (2, 1) (4,9) (2,-1) (3, 0) (5,3) ---> [(1,0),(2,-1),(4,-9),(3,0),(5,-3),(6,0)] (4,-9) (5,-3) (6,0) Note that the imaginary part of the diagonal elements are not accessed and are assumed to be 0.
stride_A – [in] [rocblas_stride] stride from the start of one (A_i) and the next (A_i+1).
batch_count – [in] [rocblas_int] number of instances in the batch.
rocblas_Xhpr2 + batched, strided_batched#
-
rocblas_status rocblas_chpr2(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *x, rocblas_int incx, const rocblas_float_complex *y, rocblas_int incy, rocblas_float_complex *AP)#
-
rocblas_status rocblas_zhpr2(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *x, rocblas_int incx, const rocblas_double_complex *y, rocblas_int incy, rocblas_double_complex *AP)#
BLAS Level 2 API
hpr2 performs the matrix-vector operations:
A := A + alpha*x*y**H + conj(alpha)*y*x**H where alpha is a complex scalar, x and y are vectors, and A is an n by n Hermitian matrix, supplied in packed form.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill] specifies whether the upper ‘rocblas_fill_upper’ or lower ‘rocblas_fill_lower’
rocblas_fill_upper: The upper triangular part of A is supplied in AP.
rocblas_fill_lower: The lower triangular part of A is supplied in AP.
n – [in] [rocblas_int] the number of rows and columns of matrix A. Must be at least 0.
alpha – [in] device pointer or host pointer to scalar alpha.
x – [in] device pointer storing vector x.
incx – [in] [rocblas_int] specifies the increment for the elements of x.
y – [in] device pointer storing vector y.
incy – [in] [rocblas_int] specifies the increment for the elements of y.
AP – [inout] device pointer storing the packed version of the specified triangular portion of the Hermitian matrix A. Of at least size ((n * (n + 1)) / 2).
if uplo == rocblas_fill_upper: The upper triangular portion of the Hermitian matrix A is supplied. The matrix is compacted so that AP contains the triangular portion column-by-column so that: AP(0) = A(0,0) AP(1) = A(0,1) AP(2) = A(1,1), etc. Ex: (rocblas_fill_upper; n = 3) (1, 0) (2, 1) (4,9) (2,-1) (3, 0) (5,3) ---> [(1,0),(2,1),(3,0),(4,9),(5,3),(6,0)] (4,-9) (5,-3) (6,0) if uplo == rocblas_fill_lower: The lower triangular portion of the Hermitian matrix A is supplied. The matrix is compacted so that AP contains the triangular portion column-by-column so that: AP(0) = A(0,0) AP(1) = A(1,0) AP(2) = A(2,1), etc. Ex: (rocblas_fill_lower; n = 3) (1, 0) (2, 1) (4,9) (2,-1) (3, 0) (5,3) ---> [(1,0),(2,-1),(4,-9),(3,0),(5,-3),(6,0)] (4,-9) (5,-3) (6,0) Note that the imaginary part of the diagonal elements are not accessed and are assumed to be 0.
-
rocblas_status rocblas_chpr2_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *const x[], rocblas_int incx, const rocblas_float_complex *const y[], rocblas_int incy, rocblas_float_complex *const AP[], rocblas_int batch_count)#
-
rocblas_status rocblas_zhpr2_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *const x[], rocblas_int incx, const rocblas_double_complex *const y[], rocblas_int incy, rocblas_double_complex *const AP[], rocblas_int batch_count)#
BLAS Level 2 API
hpr2_batched performs the matrix-vector operations:
A_i := A_i + alpha*x_i*y_i**H + conj(alpha)*y_i*x_i**H where alpha is a complex scalar, x_i and y_i are vectors, and A_i is an n by n symmetric matrix, supplied in packed form, for i = 1, ..., batch_count.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill] specifies whether the upper ‘rocblas_fill_upper’ or lower ‘rocblas_fill_lower’
rocblas_fill_upper: The upper triangular part of each A_i is supplied in AP.
rocblas_fill_lower: The lower triangular part of each A_i is supplied in AP.
n – [in] [rocblas_int] the number of rows and columns of each matrix A_i. Must be at least 0.
alpha – [in] device pointer or host pointer to scalar alpha.
x – [in] device array of device pointers storing each vector x_i.
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i.
y – [in] device array of device pointers storing each vector y_i.
incy – [in] [rocblas_int] specifies the increment for the elements of each y_i.
AP – [inout] device array of device pointers storing the packed version of the specified triangular portion of each Hermitian matrix A_i of at least size ((n * (n + 1)) / 2). Array is of at least size batch_count.
if uplo == rocblas_fill_upper: The upper triangular portion of each Hermitian matrix A_i is supplied. The matrix is compacted so that AP contains the triangular portion column-by-column so that: AP(0) = A(0,0) AP(1) = A(0,1) AP(2) = A(1,1), etc. Ex: (rocblas_fill_upper; n = 3) (1, 0) (2, 1) (4,9) (2,-1) (3, 0) (5,3) ---> [(1,0),(2,1),(3,0),(4,9),(5,3),(6,0)] (4,-9) (5,-3) (6,0) if uplo == rocblas_fill_lower: The lower triangular portion of each Hermitian matrix A_i is supplied. The matrix is compacted so that AP contains the triangular portion column-by-column so that: AP(0) = A(0,0) AP(1) = A(1,0) AP(2) = A(2,1), etc. Ex: (rocblas_fill_lower; n = 3) (1, 0) (2, 1) (4,9) (2,-1) (3, 0) (5,3) --> [(1,0),(2,-1),(4,-9),(3,0),(5,-3),(6,0)] (4,-9) (5,-3) (6,0) Note that the imaginary part of the diagonal elements are not accessed and are assumed to be 0.
batch_count – [in] [rocblas_int] number of instances in the batch.
-
rocblas_status rocblas_chpr2_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *x, rocblas_int incx, rocblas_stride stride_x, const rocblas_float_complex *y, rocblas_int incy, rocblas_stride stride_y, rocblas_float_complex *AP, rocblas_stride stride_A, rocblas_int batch_count)#
-
rocblas_status rocblas_zhpr2_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *x, rocblas_int incx, rocblas_stride stride_x, const rocblas_double_complex *y, rocblas_int incy, rocblas_stride stride_y, rocblas_double_complex *AP, rocblas_stride stride_A, rocblas_int batch_count)#
BLAS Level 2 API
hpr2_strided_batched performs the matrix-vector operations:
A_i := A_i + alpha*x_i*y_i**H + conj(alpha)*y_i*x_i**H where alpha is a complex scalar, x_i and y_i are vectors, and A_i is an n by n symmetric matrix, supplied in packed form, for i = 1, ..., batch_count.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill] specifies whether the upper ‘rocblas_fill_upper’ or lower ‘rocblas_fill_lower’
rocblas_fill_upper: The upper triangular part of each A_i is supplied in AP.
rocblas_fill_lower: The lower triangular part of each A_i is supplied in AP.
n – [in] [rocblas_int] the number of rows and columns of each matrix A_i. Must be at least 0.
alpha – [in] device pointer or host pointer to scalar alpha.
x – [in] device pointer pointing to the first vector (x_1).
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i.
stride_x – [in] [rocblas_stride] stride from the start of one vector (x_i) and the next one (x_i+1).
y – [in] device pointer pointing to the first vector (y_1).
incy – [in] [rocblas_int] specifies the increment for the elements of each y_i.
stride_y – [in] [rocblas_stride] stride from the start of one vector (y_i) and the next one (y_i+1).
AP – [inout] device array of device pointers storing the packed version of the specified triangular portion of each Hermitian matrix A_i. Points to the first matrix (A_1).
if uplo == rocblas_fill_upper: The upper triangular portion of each Hermitian matrix A_i is supplied. The matrix is compacted so that AP contains the triangular portion column-by-column so that: AP(0) = A(0,0) AP(1) = A(0,1) AP(2) = A(1,1), etc. Ex: (rocblas_fill_upper; n = 3) (1, 0) (2, 1) (4,9) (2,-1) (3, 0) (5,3) ---> [(1,0),(2,1),(3,0),(4,9),(5,3),(6,0)] (4,-9) (5,-3) (6,0) if uplo == rocblas_fill_lower: The lower triangular portion of each Hermitian matrix A_i is supplied. The matrix is compacted so that AP contains the triangular portion column-by-column so that: AP(0) = A(0,0) AP(1) = A(1,0) AP(2) = A(2,1), etc. Ex: (rocblas_fill_lower; n = 3) (1, 0) (2, 1) (4,9) (2,-1) (3, 0) (5,3) ---> [(1,0),(2,-1),(4,-9),(3,0),(5,-3),(6,0)] (4,-9) (5,-3) (6,0) Note that the imaginary part of the diagonal elements are not accessed and are assumed to be 0.
stride_A – [in] [rocblas_stride] stride from the start of one (A_i) and the next (A_i+1).
batch_count – [in] [rocblas_int] number of instances in the batch.
rocBLAS Level-3 functions#
rocblas_Xgemm + batched, strided_batched#
-
rocblas_status rocblas_sgemm(rocblas_handle handle, rocblas_operation transA, rocblas_operation transB, rocblas_int m, rocblas_int n, rocblas_int k, const float *alpha, const float *A, rocblas_int lda, const float *B, rocblas_int ldb, const float *beta, float *C, rocblas_int ldc)#
-
rocblas_status rocblas_dgemm(rocblas_handle handle, rocblas_operation transA, rocblas_operation transB, rocblas_int m, rocblas_int n, rocblas_int k, const double *alpha, const double *A, rocblas_int lda, const double *B, rocblas_int ldb, const double *beta, double *C, rocblas_int ldc)#
-
rocblas_status rocblas_hgemm(rocblas_handle handle, rocblas_operation transA, rocblas_operation transB, rocblas_int m, rocblas_int n, rocblas_int k, const rocblas_half *alpha, const rocblas_half *A, rocblas_int lda, const rocblas_half *B, rocblas_int ldb, const rocblas_half *beta, rocblas_half *C, rocblas_int ldc)#
-
rocblas_status rocblas_cgemm(rocblas_handle handle, rocblas_operation transA, rocblas_operation transB, rocblas_int m, rocblas_int n, rocblas_int k, const rocblas_float_complex *alpha, const rocblas_float_complex *A, rocblas_int lda, const rocblas_float_complex *B, rocblas_int ldb, const rocblas_float_complex *beta, rocblas_float_complex *C, rocblas_int ldc)#
-
rocblas_status rocblas_zgemm(rocblas_handle handle, rocblas_operation transA, rocblas_operation transB, rocblas_int m, rocblas_int n, rocblas_int k, const rocblas_double_complex *alpha, const rocblas_double_complex *A, rocblas_int lda, const rocblas_double_complex *B, rocblas_int ldb, const rocblas_double_complex *beta, rocblas_double_complex *C, rocblas_int ldc)#
BLAS Level 3 API
gemm performs one of the matrix-matrix operations:
C = alpha*op( A )*op( B ) + beta*C, where op( X ) is one of op( X ) = X or op( X ) = X**T or op( X ) = X**H, alpha and beta are scalars, and A, B and C are matrices, with op( A ) an m by k matrix, op( B ) a k by n matrix and C an m by n matrix.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
transA – [in] [rocblas_operation] specifies the form of op( A ).
transB – [in] [rocblas_operation] specifies the form of op( B ).
m – [in] [rocblas_int] number or rows of matrices op( A ) and C.
n – [in] [rocblas_int] number of columns of matrices op( B ) and C.
k – [in] [rocblas_int] number of columns of matrix op( A ) and number of rows of matrix op( B ).
alpha – [in] device pointer or host pointer specifying the scalar alpha.
A – [in] device pointer storing matrix A.
lda – [in] [rocblas_int] specifies the leading dimension of A.
B – [in] device pointer storing matrix B.
ldb – [in] [rocblas_int] specifies the leading dimension of B.
beta – [in] device pointer or host pointer specifying the scalar beta.
C – [inout] device pointer storing matrix C on the GPU.
ldc – [in] [rocblas_int] specifies the leading dimension of C.
-
rocblas_status rocblas_sgemm_batched(rocblas_handle handle, rocblas_operation transA, rocblas_operation transB, rocblas_int m, rocblas_int n, rocblas_int k, const float *alpha, const float *const A[], rocblas_int lda, const float *const B[], rocblas_int ldb, const float *beta, float *const C[], rocblas_int ldc, rocblas_int batch_count)#
-
rocblas_status rocblas_dgemm_batched(rocblas_handle handle, rocblas_operation transA, rocblas_operation transB, rocblas_int m, rocblas_int n, rocblas_int k, const double *alpha, const double *const A[], rocblas_int lda, const double *const B[], rocblas_int ldb, const double *beta, double *const C[], rocblas_int ldc, rocblas_int batch_count)#
-
rocblas_status rocblas_hgemm_batched(rocblas_handle handle, rocblas_operation transA, rocblas_operation transB, rocblas_int m, rocblas_int n, rocblas_int k, const rocblas_half *alpha, const rocblas_half *const A[], rocblas_int lda, const rocblas_half *const B[], rocblas_int ldb, const rocblas_half *beta, rocblas_half *const C[], rocblas_int ldc, rocblas_int batch_count)#
-
rocblas_status rocblas_cgemm_batched(rocblas_handle handle, rocblas_operation transA, rocblas_operation transB, rocblas_int m, rocblas_int n, rocblas_int k, const rocblas_float_complex *alpha, const rocblas_float_complex *const A[], rocblas_int lda, const rocblas_float_complex *const B[], rocblas_int ldb, const rocblas_float_complex *beta, rocblas_float_complex *const C[], rocblas_int ldc, rocblas_int batch_count)#
-
rocblas_status rocblas_zgemm_batched(rocblas_handle handle, rocblas_operation transA, rocblas_operation transB, rocblas_int m, rocblas_int n, rocblas_int k, const rocblas_double_complex *alpha, const rocblas_double_complex *const A[], rocblas_int lda, const rocblas_double_complex *const B[], rocblas_int ldb, const rocblas_double_complex *beta, rocblas_double_complex *const C[], rocblas_int ldc, rocblas_int batch_count)#
BLAS Level 3 API
gemm_batched performs one of the batched matrix-matrix operations:
C_i = alpha*op( A_i )*op( B_i ) + beta*C_i, for i = 1, ..., batch_count, where op( X ) is one of op( X ) = X or op( X ) = X**T or op( X ) = X**H, alpha and beta are scalars, and A, B and C are strided batched matrices, with op( A ) an m by k by batch_count strided_batched matrix, op( B ) an k by n by batch_count strided_batched matrix and C an m by n by batch_count strided_batched matrix.
- Parameters:
handle – [in] [rocblas_handle handle to the rocblas library context queue.
transA – [in] [rocblas_operation] specifies the form of op( A ).
transB – [in] [rocblas_operation] specifies the form of op( B ).
m – [in] [rocblas_int] matrix dimention m.
n – [in] [rocblas_int] matrix dimention n.
k – [in] [rocblas_int] matrix dimention k.
alpha – [in] device pointer or host pointer specifying the scalar alpha.
A – [in] device array of device pointers storing each matrix A_i.
lda – [in] [rocblas_int] specifies the leading dimension of each A_i.
B – [in] device array of device pointers storing each matrix B_i.
ldb – [in] [rocblas_int] specifies the leading dimension of each B_i.
beta – [in] device pointer or host pointer specifying the scalar beta.
C – [inout] device array of device pointers storing each matrix C_i.
ldc – [in] [rocblas_int] specifies the leading dimension of each C_i.
batch_count – [in] [rocblas_int] number of gemm operations in the batch.
-
rocblas_status rocblas_sgemm_strided_batched(rocblas_handle handle, rocblas_operation transA, rocblas_operation transB, rocblas_int m, rocblas_int n, rocblas_int k, const float *alpha, const float *A, rocblas_int lda, rocblas_stride stride_a, const float *B, rocblas_int ldb, rocblas_stride stride_b, const float *beta, float *C, rocblas_int ldc, rocblas_stride stride_c, rocblas_int batch_count)#
-
rocblas_status rocblas_dgemm_strided_batched(rocblas_handle handle, rocblas_operation transA, rocblas_operation transB, rocblas_int m, rocblas_int n, rocblas_int k, const double *alpha, const double *A, rocblas_int lda, rocblas_stride stride_a, const double *B, rocblas_int ldb, rocblas_stride stride_b, const double *beta, double *C, rocblas_int ldc, rocblas_stride stride_c, rocblas_int batch_count)#
-
rocblas_status rocblas_hgemm_strided_batched(rocblas_handle handle, rocblas_operation transA, rocblas_operation transB, rocblas_int m, rocblas_int n, rocblas_int k, const rocblas_half *alpha, const rocblas_half *A, rocblas_int lda, rocblas_stride stride_a, const rocblas_half *B, rocblas_int ldb, rocblas_stride stride_b, const rocblas_half *beta, rocblas_half *C, rocblas_int ldc, rocblas_stride stride_c, rocblas_int batch_count)#
-
rocblas_status rocblas_cgemm_strided_batched(rocblas_handle handle, rocblas_operation transA, rocblas_operation transB, rocblas_int m, rocblas_int n, rocblas_int k, const rocblas_float_complex *alpha, const rocblas_float_complex *A, rocblas_int lda, rocblas_stride stride_a, const rocblas_float_complex *B, rocblas_int ldb, rocblas_stride stride_b, const rocblas_float_complex *beta, rocblas_float_complex *C, rocblas_int ldc, rocblas_stride stride_c, rocblas_int batch_count)#
-
rocblas_status rocblas_zgemm_strided_batched(rocblas_handle handle, rocblas_operation transA, rocblas_operation transB, rocblas_int m, rocblas_int n, rocblas_int k, const rocblas_double_complex *alpha, const rocblas_double_complex *A, rocblas_int lda, rocblas_stride stride_a, const rocblas_double_complex *B, rocblas_int ldb, rocblas_stride stride_b, const rocblas_double_complex *beta, rocblas_double_complex *C, rocblas_int ldc, rocblas_stride stride_c, rocblas_int batch_count)#
BLAS Level 3 API
gemm_strided_batched performs one of the strided batched matrix-matrix operations:
C_i = alpha*op( A_i )*op( B_i ) + beta*C_i, for i = 1, ..., batch_count, where op( X ) is one of op( X ) = X or op( X ) = X**T or op( X ) = X**H, alpha and beta are scalars, and A, B and C are strided batched matrices, with op( A ) an m by k by batch_count strided_batched matrix, op( B ) an k by n by batch_count strided_batched matrix and C an m by n by batch_count strided_batched matrix.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
transA – [in] [rocblas_operation] specifies the form of op( A ).
transB – [in] [rocblas_operation] specifies the form of op( B ).
m – [in] [rocblas_int] matrix dimention m.
n – [in] [rocblas_int] matrix dimention n.
k – [in] [rocblas_int] matrix dimention k.
alpha – [in] device pointer or host pointer specifying the scalar alpha.
A – [in] device pointer pointing to the first matrix A_1.
lda – [in] [rocblas_int] specifies the leading dimension of each A_i.
stride_a – [in] [rocblas_stride] stride from the start of one A_i matrix to the next A_(i + 1).
B – [in] device pointer pointing to the first matrix B_1.
ldb – [in] [rocblas_int] specifies the leading dimension of each B_i.
stride_b – [in] [rocblas_stride] stride from the start of one B_i matrix to the next B_(i + 1).
beta – [in] device pointer or host pointer specifying the scalar beta.
C – [inout] device pointer pointing to the first matrix C_1.
ldc – [in] [rocblas_int] specifies the leading dimension of each C_i.
stride_c – [in] [rocblas_stride] stride from the start of one C_i matrix to the next C_(i + 1).
batch_count – [in] [rocblas_int] number of gemm operatons in the batch.
rocblas_Xsymm + batched, strided_batched#
-
rocblas_status rocblas_ssymm(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_int m, rocblas_int n, const float *alpha, const float *A, rocblas_int lda, const float *B, rocblas_int ldb, const float *beta, float *C, rocblas_int ldc)#
-
rocblas_status rocblas_dsymm(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_int m, rocblas_int n, const double *alpha, const double *A, rocblas_int lda, const double *B, rocblas_int ldb, const double *beta, double *C, rocblas_int ldc)#
-
rocblas_status rocblas_csymm(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_int m, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *A, rocblas_int lda, const rocblas_float_complex *B, rocblas_int ldb, const rocblas_float_complex *beta, rocblas_float_complex *C, rocblas_int ldc)#
-
rocblas_status rocblas_zsymm(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_int m, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *A, rocblas_int lda, const rocblas_double_complex *B, rocblas_int ldb, const rocblas_double_complex *beta, rocblas_double_complex *C, rocblas_int ldc)#
BLAS Level 3 API
symm performs one of the matrix-matrix operations:
C := alpha*A*B + beta*C if side == rocblas_side_left, C := alpha*B*A + beta*C if side == rocblas_side_right, where alpha and beta are scalars, B and C are m by n matrices, and A is a symmetric matrix stored as either upper or lower.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
side – [in] [rocblas_side]
rocblas_side_left: C := alpha*A*B + beta*C
rocblas_side_right: C := alpha*B*A + beta*C
uplo – [in] [rocblas_fill]
rocblas_fill_upper: A is an upper triangular matrix
rocblas_fill_lower: A is a lower triangular matrix
m – [in] [rocblas_int] m specifies the number of rows of B and C. m >= 0.
n – [in] [rocblas_int] n specifies the number of columns of B and C. n >= 0.
alpha – [in] alpha specifies the scalar alpha. When alpha is zero then A and B are not referenced.
A – [in] pointer storing matrix A on the GPU.
A is m by m if side == rocblas_side_left
A is n by n if side == rocblas_side_right only the upper/lower triangular part is accessed.
lda – [in] [rocblas_int] lda specifies the first dimension of A.
if side = rocblas_side_left, lda >= max( 1, m ), otherwise lda >= max( 1, n ).
B – [in] pointer storing matrix B on the GPU. Matrix dimension is m by n
ldb – [in] [rocblas_int] ldb specifies the first dimension of B. ldb >= max( 1, m ).
beta – [in] beta specifies the scalar beta. When beta is zero then C need not be set before entry.
C – [in] pointer storing matrix C on the GPU. Matrix dimension is m by n
ldc – [in] [rocblas_int] ldc specifies the first dimension of C. ldc >= max( 1, m ).
-
rocblas_status rocblas_ssymm_batched(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_int m, rocblas_int n, const float *alpha, const float *const A[], rocblas_int lda, const float *const B[], rocblas_int ldb, const float *beta, float *const C[], rocblas_int ldc, rocblas_int batch_count)#
-
rocblas_status rocblas_dsymm_batched(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_int m, rocblas_int n, const double *alpha, const double *const A[], rocblas_int lda, const double *const B[], rocblas_int ldb, const double *beta, double *const C[], rocblas_int ldc, rocblas_int batch_count)#
-
rocblas_status rocblas_csymm_batched(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_int m, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *const A[], rocblas_int lda, const rocblas_float_complex *const B[], rocblas_int ldb, const rocblas_float_complex *beta, rocblas_float_complex *const C[], rocblas_int ldc, rocblas_int batch_count)#
-
rocblas_status rocblas_zsymm_batched(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_int m, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *const A[], rocblas_int lda, const rocblas_double_complex *const B[], rocblas_int ldb, const rocblas_double_complex *beta, rocblas_double_complex *const C[], rocblas_int ldc, rocblas_int batch_count)#
BLAS Level 3 API
symm_batched performs a batch of the matrix-matrix operations:
C_i := alpha*A_i*B_i + beta*C_i if side == rocblas_side_left, C_i := alpha*B_i*A_i + beta*C_i if side == rocblas_side_right, where alpha and beta are scalars, B_i and C_i are m by n matrices, and A_i is a symmetric matrix stored as either upper or lower.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
side – [in] [rocblas_side]
rocblas_side_left: C_i := alpha*A_i*B_i + beta*C_i
rocblas_side_right: C_i := alpha*B_i*A_i + beta*C_i
uplo – [in] [rocblas_fill]
rocblas_fill_upper: A_i is an upper triangular matrix
rocblas_fill_lower: A_i is a lower triangular matrix
m – [in] [rocblas_int] m specifies the number of rows of B_i and C_i. m >= 0.
n – [in] [rocblas_int] n specifies the number of columns of B_i and C_i. n >= 0.
alpha – [in] alpha specifies the scalar alpha. When alpha is zero then A_i and B_i are not referenced.
A – [in] device array of device pointers storing each matrix A_i on the GPU.
A_i is m by m if side == rocblas_side_left
A_i is n by n if side == rocblas_side_right only the upper/lower triangular part is accessed.
lda – [in] [rocblas_int] lda specifies the first dimension of A_i.
if side = rocblas_side_left, lda >= max( 1, m ), otherwise lda >= max( 1, n ).
B – [in] device array of device pointers storing each matrix B_i on the GPU. Matrix dimension is m by n
ldb – [in] [rocblas_int] ldb specifies the first dimension of B_i. ldb >= max( 1, m ).
beta – [in] beta specifies the scalar beta. When beta is zero then C_i need not be set before entry.
C – [in] device array of device pointers storing each matrix C_i on the GPU. Matrix dimension is m by n.
ldc – [in] [rocblas_int] ldc specifies the first dimension of C_i. ldc >= max( 1, m ).
batch_count – [in] [rocblas_int] number of instances in the batch.
-
rocblas_status rocblas_ssymm_strided_batched(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_int m, rocblas_int n, const float *alpha, const float *A, rocblas_int lda, rocblas_stride stride_A, const float *B, rocblas_int ldb, rocblas_stride stride_B, const float *beta, float *C, rocblas_int ldc, rocblas_stride stride_C, rocblas_int batch_count)#
-
rocblas_status rocblas_dsymm_strided_batched(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_int m, rocblas_int n, const double *alpha, const double *A, rocblas_int lda, rocblas_stride stride_A, const double *B, rocblas_int ldb, rocblas_stride stride_B, const double *beta, double *C, rocblas_int ldc, rocblas_stride stride_C, rocblas_int batch_count)#
-
rocblas_status rocblas_csymm_strided_batched(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_int m, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *A, rocblas_int lda, rocblas_stride stride_A, const rocblas_float_complex *B, rocblas_int ldb, rocblas_stride stride_B, const rocblas_float_complex *beta, rocblas_float_complex *C, rocblas_int ldc, rocblas_stride stride_C, rocblas_int batch_count)#
-
rocblas_status rocblas_zsymm_strided_batched(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_int m, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *A, rocblas_int lda, rocblas_stride stride_A, const rocblas_double_complex *B, rocblas_int ldb, rocblas_stride stride_B, const rocblas_double_complex *beta, rocblas_double_complex *C, rocblas_int ldc, rocblas_stride stride_C, rocblas_int batch_count)#
BLAS Level 3 API
symm_strided_batched performs a batch of the matrix-matrix operations:
C_i := alpha*A_i*B_i + beta*C_i if side == rocblas_side_left, C_i := alpha*B_i*A_i + beta*C_i if side == rocblas_side_right, where alpha and beta are scalars, B_i and C_i are m by n matrices, and A_i is a symmetric matrix stored as either upper or lower.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
side – [in] [rocblas_side]
rocblas_side_left: C_i := alpha*A_i*B_i + beta*C_i
rocblas_side_right: C_i := alpha*B_i*A_i + beta*C_i
uplo – [in] [rocblas_fill]
rocblas_fill_upper: A_i is an upper triangular matrix
rocblas_fill_lower: A_i is a lower triangular matrix
m – [in] [rocblas_int] m specifies the number of rows of B_i and C_i. m >= 0.
n – [in] [rocblas_int] n specifies the number of columns of B_i and C_i. n >= 0.
alpha – [in] alpha specifies the scalar alpha. When alpha is zero then A_i and B_i are not referenced.
A – [in] device pointer to first matrix A_1
A_i is m by m if side == rocblas_side_left
A_i is n by n if side == rocblas_side_right only the upper/lower triangular part is accessed.
lda – [in] [rocblas_int] lda specifies the first dimension of A_i.
if side = rocblas_side_left, lda >= max( 1, m ), otherwise lda >= max( 1, n ).
stride_A – [in] [rocblas_stride] stride from the start of one matrix (A_i) and the next one (A_i+1).
B – [in] device pointer to first matrix B_1 of dimension (ldb, n) on the GPU.
ldb – [in] [rocblas_int] ldb specifies the first dimension of B_i. ldb >= max( 1, m ).
stride_B – [in] [rocblas_stride] stride from the start of one matrix (B_i) and the next one (B_i+1).
beta – [in] beta specifies the scalar beta. When beta is zero then C need not be set before entry.
C – [in] device pointer to first matrix C_1 of dimension (ldc, n) on the GPU.
ldc – [in] [rocblas_int] ldc specifies the first dimension of C. ldc >= max( 1, m ).
stride_C – [inout] [rocblas_stride] stride from the start of one matrix (C_i) and the next one (C_i+1).
batch_count – [in] [rocblas_int] number of instances in the batch.
rocblas_Xsyrk + batched, strided_batched#
-
rocblas_status rocblas_ssyrk(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_int n, rocblas_int k, const float *alpha, const float *A, rocblas_int lda, const float *beta, float *C, rocblas_int ldc)#
-
rocblas_status rocblas_dsyrk(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_int n, rocblas_int k, const double *alpha, const double *A, rocblas_int lda, const double *beta, double *C, rocblas_int ldc)#
-
rocblas_status rocblas_csyrk(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_int n, rocblas_int k, const rocblas_float_complex *alpha, const rocblas_float_complex *A, rocblas_int lda, const rocblas_float_complex *beta, rocblas_float_complex *C, rocblas_int ldc)#
-
rocblas_status rocblas_zsyrk(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_int n, rocblas_int k, const rocblas_double_complex *alpha, const rocblas_double_complex *A, rocblas_int lda, const rocblas_double_complex *beta, rocblas_double_complex *C, rocblas_int ldc)#
BLAS Level 3 API
syrk performs one of the matrix-matrix operations for a symmetric rank-k update:
C := alpha*op( A )*op( A )^T + beta*C, where alpha and beta are scalars, op(A) is an n by k matrix, and C is a symmetric n x n matrix stored as either upper or lower. op( A ) = A, and A is n by k if transA == rocblas_operation_none op( A ) = A^T and A is k by n if transA == rocblas_operation_transpose
rocblas_operation_conjugate_transpose is not supported for complex types. See cherk and zherk.
if transA = rocblas_operation_none, lda >= max( 1, n ), otherwise lda >= max( 1, k ).
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill]
rocblas_fill_upper: C is an upper triangular matrix
rocblas_fill_lower: C is a lower triangular matrix
transA – [in] [rocblas_operation]
rocblas_operation_transpose: op(A) = A^T
rocblas_operation_none: op(A) = A
rocblas_operation_conjugate_transpose: op(A) = A^T
n – [in] [rocblas_int] n specifies the number of rows and columns of C. n >= 0.
k – [in] [rocblas_int] k specifies the number of columns of op(A). k >= 0.
alpha – [in] alpha specifies the scalar alpha. When alpha is zero then A is not referenced and A need not be set before entry.
A – [in] pointer storing matrix A on the GPU. Matrix dimension is ( lda, k ) when if transA = rocblas_operation_none, otherwise (lda, n)
lda – [in] [rocblas_int] lda specifies the first dimension of A.
beta – [in] beta specifies the scalar beta. When beta is zero then C need not be set before entry.
C – [in] pointer storing matrix C on the GPU. only the upper/lower triangular part is accessed.
ldc – [in] [rocblas_int] ldc specifies the first dimension of C. ldc >= max( 1, n ).
-
rocblas_status rocblas_ssyrk_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_int n, rocblas_int k, const float *alpha, const float *const A[], rocblas_int lda, const float *beta, float *const C[], rocblas_int ldc, rocblas_int batch_count)#
-
rocblas_status rocblas_dsyrk_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_int n, rocblas_int k, const double *alpha, const double *const A[], rocblas_int lda, const double *beta, double *const C[], rocblas_int ldc, rocblas_int batch_count)#
-
rocblas_status rocblas_csyrk_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_int n, rocblas_int k, const rocblas_float_complex *alpha, const rocblas_float_complex *const A[], rocblas_int lda, const rocblas_float_complex *beta, rocblas_float_complex *const C[], rocblas_int ldc, rocblas_int batch_count)#
-
rocblas_status rocblas_zsyrk_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_int n, rocblas_int k, const rocblas_double_complex *alpha, const rocblas_double_complex *const A[], rocblas_int lda, const rocblas_double_complex *beta, rocblas_double_complex *const C[], rocblas_int ldc, rocblas_int batch_count)#
BLAS Level 3 API
syrk_batched performs a batch of the matrix-matrix operations for a symmetric rank-k update:
C_i := alpha*op( A_i )*op( A_i )^T + beta*C_i, where alpha and beta are scalars, op(A_i) is an n by k matrix, and C_i is a symmetric n x n matrix stored as either upper or lower. op( A_i ) = A_i, and A_i is n by k if transA == rocblas_operation_none op( A_i ) = A_i^T and A_i is k by n if transA == rocblas_operation_transpose
rocblas_operation_conjugate_transpose is not supported for complex types. See cherk and zherk.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill]
rocblas_fill_upper: C_i is an upper triangular matrix
rocblas_fill_lower: C_i is a lower triangular matrix
transA – [in] [rocblas_operation]
rocblas_operation_transpose: op(A) = A^T
rocblas_operation_none: op(A) = A
rocblas_operation_conjugate_transpose: op(A) = A^T
n – [in] [rocblas_int] n specifies the number of rows and columns of C_i. n >= 0.
k – [in] [rocblas_int] k specifies the number of columns of op(A). k >= 0.
alpha – [in] alpha specifies the scalar alpha. When alpha is zero then A is not referenced and A need not be set before entry.
A – [in] device array of device pointers storing each matrix_i A of dimension (lda, k) when transA is rocblas_operation_none, otherwise of dimension (lda, n).
lda – [in] [rocblas_int] lda specifies the first dimension of A_i.
if transA = rocblas_operation_none, lda >= max( 1, n ), otherwise lda >= max( 1, k ).
beta – [in] beta specifies the scalar beta. When beta is zero then C need not be set before entry.
C – [in] device array of device pointers storing each matrix C_i on the GPU. only the upper/lower triangular part of each C_i is accessed.
ldc – [in] [rocblas_int] ldc specifies the first dimension of C. ldc >= max( 1, n ).
batch_count – [in] [rocblas_int] number of instances in the batch.
-
rocblas_status rocblas_ssyrk_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_int n, rocblas_int k, const float *alpha, const float *A, rocblas_int lda, rocblas_stride stride_A, const float *beta, float *C, rocblas_int ldc, rocblas_stride stride_C, rocblas_int batch_count)#
-
rocblas_status rocblas_dsyrk_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_int n, rocblas_int k, const double *alpha, const double *A, rocblas_int lda, rocblas_stride stride_A, const double *beta, double *C, rocblas_int ldc, rocblas_stride stride_C, rocblas_int batch_count)#
-
rocblas_status rocblas_csyrk_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_int n, rocblas_int k, const rocblas_float_complex *alpha, const rocblas_float_complex *A, rocblas_int lda, rocblas_stride stride_A, const rocblas_float_complex *beta, rocblas_float_complex *C, rocblas_int ldc, rocblas_stride stride_C, rocblas_int batch_count)#
-
rocblas_status rocblas_zsyrk_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_int n, rocblas_int k, const rocblas_double_complex *alpha, const rocblas_double_complex *A, rocblas_int lda, rocblas_stride stride_A, const rocblas_double_complex *beta, rocblas_double_complex *C, rocblas_int ldc, rocblas_stride stride_C, rocblas_int batch_count)#
BLAS Level 3 API
syrk_strided_batched performs a batch of the matrix-matrix operations for a symmetric rank-k update:
C_i := alpha*op( A_i )*op( A_i )^T + beta*C_i, where alpha and beta are scalars, op(A_i) is an n by k matrix, and C_i is a symmetric n x n matrix stored as either upper or lower. op( A_i ) = A_i, and A_i is n by k if transA == rocblas_operation_none op( A_i ) = A_i^T and A_i is k by n if transA == rocblas_operation_transpose
rocblas_operation_conjugate_transpose is not supported for complex types. See cherk and zherk.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill]
rocblas_fill_upper: C_i is an upper triangular matrix
rocblas_fill_lower: C_i is a lower triangular matrix
transA – [in] [rocblas_operation]
rocblas_operation_transpose: op(A) = A^T
rocblas_operation_none: op(A) = A
rocblas_operation_conjugate_transpose: op(A) = A^T
n – [in] [rocblas_int] n specifies the number of rows and columns of C_i. n >= 0.
k – [in] [rocblas_int] k specifies the number of columns of op(A). k >= 0.
alpha – [in] alpha specifies the scalar alpha. When alpha is zero then A is not referenced and A need not be set before entry.
A – [in] Device pointer to the first matrix A_1 on the GPU of dimension (lda, k) when transA is rocblas_operation_none, otherwise of dimension (lda, n).
lda – [in] [rocblas_int] lda specifies the first dimension of A_i.
if transA = rocblas_operation_none, lda >= max( 1, n ), otherwise lda >= max( 1, k ).
stride_A – [in] [rocblas_stride] stride from the start of one matrix (A_i) and the next one (A_i+1).
beta – [in] beta specifies the scalar beta. When beta is zero then C need not be set before entry.
C – [in] Device pointer to the first matrix C_1 on the GPU. on the GPU. only the upper/lower triangular part of each C_i is accessed.
ldc – [in] [rocblas_int] ldc specifies the first dimension of C. ldc >= max( 1, n ).
stride_C – [inout] [rocblas_stride] stride from the start of one matrix (C_i) and the next one (C_i+1)
batch_count – [in] [rocblas_int] number of instances in the batch.
rocblas_Xsyr2k + batched, strided_batched#
-
rocblas_status rocblas_ssyr2k(rocblas_handle handle, rocblas_fill uplo, rocblas_operation trans, rocblas_int n, rocblas_int k, const float *alpha, const float *A, rocblas_int lda, const float *B, rocblas_int ldb, const float *beta, float *C, rocblas_int ldc)#
-
rocblas_status rocblas_dsyr2k(rocblas_handle handle, rocblas_fill uplo, rocblas_operation trans, rocblas_int n, rocblas_int k, const double *alpha, const double *A, rocblas_int lda, const double *B, rocblas_int ldb, const double *beta, double *C, rocblas_int ldc)#
-
rocblas_status rocblas_csyr2k(rocblas_handle handle, rocblas_fill uplo, rocblas_operation trans, rocblas_int n, rocblas_int k, const rocblas_float_complex *alpha, const rocblas_float_complex *A, rocblas_int lda, const rocblas_float_complex *B, rocblas_int ldb, const rocblas_float_complex *beta, rocblas_float_complex *C, rocblas_int ldc)#
-
rocblas_status rocblas_zsyr2k(rocblas_handle handle, rocblas_fill uplo, rocblas_operation trans, rocblas_int n, rocblas_int k, const rocblas_double_complex *alpha, const rocblas_double_complex *A, rocblas_int lda, const rocblas_double_complex *B, rocblas_int ldb, const rocblas_double_complex *beta, rocblas_double_complex *C, rocblas_int ldc)#
BLAS Level 3 API
syr2k performs one of the matrix-matrix operations for a symmetric rank-2k update:
C := alpha*(op( A )*op( B )^T + op( B )*op( A )^T) + beta*C, where alpha and beta are scalars, op(A) and op(B) are n by k matrix, and C is a symmetric n x n matrix stored as either upper or lower. op( A ) = A, op( B ) = B, and A and B are n by k if trans == rocblas_operation_none op( A ) = A^T, op( B ) = B^T, and A and B are k by n if trans == rocblas_operation_transpose or for ssyr2k and dsyr2k when trans == rocblas_operation_conjugate_transpose
rocblas_operation_conjugate_transpose is not supported for complex types in csyr2k and zsyr2k.
if trans = rocblas_operation_none, lda >= max( 1, n ), otherwise lda >= max( 1, k ).
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill]
rocblas_fill_upper: C is an upper triangular matrix
rocblas_fill_lower: C is a lower triangular matrix
trans – [in] [rocblas_operation]
rocblas_operation_transpose: op( A ) = A^T, op( B ) = B^T
rocblas_operation_none: op( A ) = A, op( B ) = B
rocblas_operation_conjugate_transpose: op( A ) = A^T, op( B ) = B^T
n – [in] [rocblas_int] n specifies the number of rows and columns of C. n >= 0.
k – [in] [rocblas_int] k specifies the number of columns of op(A) and op(B). k >= 0.
alpha – [in] alpha specifies the scalar alpha. When alpha is zero then A is not referenced and A need not be set before entry.
A – [in] pointer storing matrix A on the GPU. Matrix dimension is ( lda, k ) when if trans = rocblas_operation_none, otherwise (lda, n) only the upper/lower triangular part is accessed.
lda – [in] [rocblas_int] lda specifies the first dimension of A.
B – [in] pointer storing matrix B on the GPU. Matrix dimension is ( ldb, k ) when if trans = rocblas_operation_none, otherwise (ldb, n) only the upper/lower triangular part is accessed.
ldb – [in] [rocblas_int] ldb specifies the first dimension of B. if trans = rocblas_operation_none, ldb >= max( 1, n ), otherwise ldb >= max( 1, k ).
beta – [in] beta specifies the scalar beta. When beta is zero then C need not be set before entry.
C – [in] pointer storing matrix C on the GPU.
ldc – [in] [rocblas_int] ldc specifies the first dimension of C. ldc >= max( 1, n ).
-
rocblas_status rocblas_ssyr2k_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation trans, rocblas_int n, rocblas_int k, const float *alpha, const float *const A[], rocblas_int lda, const float *const B[], rocblas_int ldb, const float *beta, float *const C[], rocblas_int ldc, rocblas_int batch_count)#
-
rocblas_status rocblas_dsyr2k_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation trans, rocblas_int n, rocblas_int k, const double *alpha, const double *const A[], rocblas_int lda, const double *const B[], rocblas_int ldb, const double *beta, double *const C[], rocblas_int ldc, rocblas_int batch_count)#
-
rocblas_status rocblas_csyr2k_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation trans, rocblas_int n, rocblas_int k, const rocblas_float_complex *alpha, const rocblas_float_complex *const A[], rocblas_int lda, const rocblas_float_complex *const B[], rocblas_int ldb, const rocblas_float_complex *beta, rocblas_float_complex *const C[], rocblas_int ldc, rocblas_int batch_count)#
-
rocblas_status rocblas_zsyr2k_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation trans, rocblas_int n, rocblas_int k, const rocblas_double_complex *alpha, const rocblas_double_complex *const A[], rocblas_int lda, const rocblas_double_complex *const B[], rocblas_int ldb, const rocblas_double_complex *beta, rocblas_double_complex *const C[], rocblas_int ldc, rocblas_int batch_count)#
BLAS Level 3 API
syr2k_batched performs a batch of the matrix-matrix operations for a symmetric rank-2k update:
C_i := alpha*(op( A_i )*op( B_i )^T + op( B_i )*op( A_i )^T) + beta*C_i, where alpha and beta are scalars, op(A_i) and op(B_i) are n by k matrix, and C_i is a symmetric n x n matrix stored as either upper or lower. op( A_i ) = A_i, op( B_i ) = B_i, and A_i and B_i are n by k if trans == rocblas_operation_none op( A_i ) = A_i^T, op( B_i ) = B_i^T, and A_i and B_i are k by n if trans == rocblas_operation_transpose or for ssyr2k_batched and dsyr2k_batched when trans == rocblas_operation_conjugate_transpose
rocblas_operation_conjugate_transpose is not supported for complex types in csyr2k_batched and zsyr2k_batched.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill]
rocblas_fill_upper: C_i is an upper triangular matrix
rocblas_fill_lower: C_i is a lower triangular matrix
trans – [in] [rocblas_operation]
rocblas_operation_transpose: op( A_i ) = A_i^T, op( B_i ) = B_i^T
rocblas_operation_none: op( A_i ) = A_i, op( B_i ) = B_i
rocblas_operation_conjugate_transpose: op( A_i ) = A_i^T, op( B_i ) = B_i^T
n – [in] [rocblas_int] n specifies the number of rows and columns of C_i. n >= 0.
k – [in] [rocblas_int] k specifies the number of columns of op(A). k >= 0.
alpha – [in] alpha specifies the scalar alpha. When alpha is zero then A is not referenced and A need not be set before entry.
A – [in] device array of device pointers storing each matrix_i A of dimension (lda, k) when trans is rocblas_operation_none, otherwise of dimension (lda, n).
lda – [in] [rocblas_int] lda specifies the first dimension of A_i. if trans = rocblas_operation_none, lda >= max( 1, n ), otherwise lda >= max( 1, k ).
B – [in] device array of device pointers storing each matrix_i B of dimension (ldb, k) when trans is rocblas_operation_none, otherwise of dimension (ldb, n).
ldb – [in] [rocblas_int] ldb specifies the first dimension of B.
if trans = rocblas_operation_none, ldb >= max( 1, n ), otherwise ldb >= max( 1, k ).
beta – [in] beta specifies the scalar beta. When beta is zero then C need not be set before entry.
C – [in] device array of device pointers storing each matrix C_i on the GPU.
ldc – [in] [rocblas_int] ldc specifies the first dimension of C. ldc >= max( 1, n ).
batch_count – [in] [rocblas_int] number of instances in the batch.
-
rocblas_status rocblas_ssyr2k_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation trans, rocblas_int n, rocblas_int k, const float *alpha, const float *A, rocblas_int lda, rocblas_stride stride_A, const float *B, rocblas_int ldb, rocblas_stride stride_B, const float *beta, float *C, rocblas_int ldc, rocblas_stride stride_C, rocblas_int batch_count)#
-
rocblas_status rocblas_dsyr2k_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation trans, rocblas_int n, rocblas_int k, const double *alpha, const double *A, rocblas_int lda, rocblas_stride stride_A, const double *B, rocblas_int ldb, rocblas_stride stride_B, const double *beta, double *C, rocblas_int ldc, rocblas_stride stride_C, rocblas_int batch_count)#
-
rocblas_status rocblas_csyr2k_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation trans, rocblas_int n, rocblas_int k, const rocblas_float_complex *alpha, const rocblas_float_complex *A, rocblas_int lda, rocblas_stride stride_A, const rocblas_float_complex *B, rocblas_int ldb, rocblas_stride stride_B, const rocblas_float_complex *beta, rocblas_float_complex *C, rocblas_int ldc, rocblas_stride stride_C, rocblas_int batch_count)#
-
rocblas_status rocblas_zsyr2k_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation trans, rocblas_int n, rocblas_int k, const rocblas_double_complex *alpha, const rocblas_double_complex *A, rocblas_int lda, rocblas_stride stride_A, const rocblas_double_complex *B, rocblas_int ldb, rocblas_stride stride_B, const rocblas_double_complex *beta, rocblas_double_complex *C, rocblas_int ldc, rocblas_stride stride_C, rocblas_int batch_count)#
BLAS Level 3 API
syr2k_strided_batched performs a batch of the matrix-matrix operations for a symmetric rank-2k update:
C_i := alpha*(op( A_i )*op( B_i )^T + op( B_i )*op( A_i )^T) + beta*C_i, where alpha and beta are scalars, op(A_i) and op(B_i) are n by k matrix, and C_i is a symmetric n x n matrix stored as either upper or lower. op( A_i ) = A_i, op( B_i ) = B_i, and A_i and B_i are n by k if trans == rocblas_operation_none op( A_i ) = A_i^T, op( B_i ) = B_i^T, and A_i and B_i are k by n if trans == rocblas_operation_transpose or for ssyr2k_strided_batched and dsyr2k_strided_batched when trans == rocblas_operation_conjugate_transpose
rocblas_operation_conjugate_transpose is not supported for complex types in csyr2k_strided_batched and zsyr2k_strided_batched.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill]
rocblas_fill_upper: C_i is an upper triangular matrix
rocblas_fill_lower: C_i is a lower triangular matrix
trans – [in] [rocblas_operation]
rocblas_operation_transpose: op( A_i ) = A_i^T, op( B_i ) = B_i^T
rocblas_operation_none: op( A_i ) = A_i, op( B_i ) = B_i
rocblas_operation_conjugate_transpose: op( A_i ) = A_i^T, op( B_i ) = B_i^T
n – [in] [rocblas_int] n specifies the number of rows and columns of C_i. n >= 0.
k – [in] [rocblas_int] k specifies the number of columns of op(A). k >= 0.
alpha – [in] alpha specifies the scalar alpha. When alpha is zero then A is not referenced and A need not be set before entry.
A – [in] Device pointer to the first matrix A_1 on the GPU of dimension (lda, k) when trans is rocblas_operation_none, otherwise of dimension (lda, n).
lda – [in] [rocblas_int] lda specifies the first dimension of A_i.
if trans = rocblas_operation_none, lda >= max( 1, n ), otherwise lda >= max( 1, k ).
stride_A – [in] [rocblas_stride] stride from the start of one matrix (A_i) and the next one (A_i+1)
B – [in] Device pointer to the first matrix B_1 on the GPU of dimension (ldb, k) when trans is rocblas_operation_none, otherwise of dimension (ldb, n)
ldb – [in] [rocblas_int] ldb specifies the first dimension of B_i.
if trans = rocblas_operation_none, ldb >= max( 1, n ), otherwise ldb >= max( 1, k ).
stride_B – [in] [rocblas_stride] stride from the start of one matrix (B_i) and the next one (B_i+1)
beta – [in] beta specifies the scalar beta. When beta is zero then C need not be set before entry.
C – [in] Device pointer to the first matrix C_1 on the GPU.
ldc – [in] [rocblas_int] ldc specifies the first dimension of C. ldc >= max( 1, n ).
stride_C – [inout] [rocblas_stride] stride from the start of one matrix (C_i) and the next one (C_i+1).
batch_count – [in] [rocblas_int] number of instances in the batch.
rocblas_Xsyrkx + batched, strided_batched#
-
rocblas_status rocblas_ssyrkx(rocblas_handle handle, rocblas_fill uplo, rocblas_operation trans, rocblas_int n, rocblas_int k, const float *alpha, const float *A, rocblas_int lda, const float *B, rocblas_int ldb, const float *beta, float *C, rocblas_int ldc)#
-
rocblas_status rocblas_dsyrkx(rocblas_handle handle, rocblas_fill uplo, rocblas_operation trans, rocblas_int n, rocblas_int k, const double *alpha, const double *A, rocblas_int lda, const double *B, rocblas_int ldb, const double *beta, double *C, rocblas_int ldc)#
-
rocblas_status rocblas_csyrkx(rocblas_handle handle, rocblas_fill uplo, rocblas_operation trans, rocblas_int n, rocblas_int k, const rocblas_float_complex *alpha, const rocblas_float_complex *A, rocblas_int lda, const rocblas_float_complex *B, rocblas_int ldb, const rocblas_float_complex *beta, rocblas_float_complex *C, rocblas_int ldc)#
-
rocblas_status rocblas_zsyrkx(rocblas_handle handle, rocblas_fill uplo, rocblas_operation trans, rocblas_int n, rocblas_int k, const rocblas_double_complex *alpha, const rocblas_double_complex *A, rocblas_int lda, const rocblas_double_complex *B, rocblas_int ldb, const rocblas_double_complex *beta, rocblas_double_complex *C, rocblas_int ldc)#
BLAS Level 3 API
syrkx performs one of the matrix-matrix operations for a symmetric rank-k update:
C := alpha*op( A )*op( B )^T + beta*C, where alpha and beta are scalars, op(A) and op(B) are n by k matrix, and C is a symmetric n x n matrix stored as either upper or lower.
This routine should only be used when the caller can guarantee that the result of op( A )*op( B )^T will be symmetric.
op( A ) = A, op( B ) = B, and A and B are n by k if trans == rocblas_operation_none op( A ) = A^T, op( B ) = B^T, and A and B are k by n if trans == rocblas_operation_transpose or for ssyrkx and dsyrkx when trans == rocblas_operation_conjugate_transpose
rocblas_operation_conjugate_transpose is not supported for complex types in csyrkx and zsyrkx.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill]
rocblas_fill_upper: C is an upper triangular matrix
rocblas_fill_lower: C is a lower triangular matrix
trans – [in] [rocblas_operation]
rocblas_operation_transpose: op( A ) = A^T, op( B ) = B^T
rocblas_operation_none: op( A ) = A, op( B ) = B
rocblas_operation_conjugate_transpose: op( A ) = A^T, op( B ) = B^T
n – [in] [rocblas_int] n specifies the number of rows and columns of C. n >= 0.
k – [in] [rocblas_int] k specifies the number of columns of op(A) and op(B). k >= 0.
alpha – [in] alpha specifies the scalar alpha. When alpha is zero then A is not referenced and A need not be set before entry.
A – [in] pointer storing matrix A on the GPU. Matrix dimension is ( lda, k ) when if trans = rocblas_operation_none, otherwise (lda, n)
lda – [in] [rocblas_int] lda specifies the first dimension of A.
if trans = rocblas_operation_none, lda >= max( 1, n ), otherwise lda >= max( 1, k ).
B – [in] pointer storing matrix B on the GPU. Matrix dimension is ( ldb, k ) when if trans = rocblas_operation_none, otherwise (ldb, n)
ldb – [in] [rocblas_int] ldb specifies the first dimension of B.
if trans = rocblas_operation_none, ldb >= max( 1, n ), otherwise ldb >= max( 1, k ).
beta – [in] beta specifies the scalar beta. When beta is zero then C need not be set before entry.
C – [in] pointer storing matrix C on the GPU. only the upper/lower triangular part is accessed.
ldc – [in] [rocblas_int] ldc specifies the first dimension of C. ldc >= max( 1, n ).
-
rocblas_status rocblas_ssyrkx_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation trans, rocblas_int n, rocblas_int k, const float *alpha, const float *const A[], rocblas_int lda, const float *const B[], rocblas_int ldb, const float *beta, float *const C[], rocblas_int ldc, rocblas_int batch_count)#
-
rocblas_status rocblas_dsyrkx_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation trans, rocblas_int n, rocblas_int k, const double *alpha, const double *const A[], rocblas_int lda, const double *const B[], rocblas_int ldb, const double *beta, double *const C[], rocblas_int ldc, rocblas_int batch_count)#
-
rocblas_status rocblas_csyrkx_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation trans, rocblas_int n, rocblas_int k, const rocblas_float_complex *alpha, const rocblas_float_complex *const A[], rocblas_int lda, const rocblas_float_complex *const B[], rocblas_int ldb, const rocblas_float_complex *beta, rocblas_float_complex *const C[], rocblas_int ldc, rocblas_int batch_count)#
-
rocblas_status rocblas_zsyrkx_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation trans, rocblas_int n, rocblas_int k, const rocblas_double_complex *alpha, const rocblas_double_complex *const A[], rocblas_int lda, const rocblas_double_complex *const B[], rocblas_int ldb, const rocblas_double_complex *beta, rocblas_double_complex *const C[], rocblas_int ldc, rocblas_int batch_count)#
BLAS Level 3 API
syrkx_batched performs a batch of the matrix-matrix operations for a symmetric rank-k update:
C_i := alpha*op( A_i )*op( B_i )^T + beta*C_i, where alpha and beta are scalars, op(A_i) and op(B_i) are n by k matrix, and C_i is a symmetric n x n matrix stored as either upper or lower.
This routine should only be used when the caller can guarantee that the result of op( A_i )*op( B_i )^T will be symmetric.
op( A_i ) = A_i, op( B_i ) = B_i, and A_i and B_i are n by k if trans == rocblas_operation_none op( A_i ) = A_i^T, op( B_i ) = B_i^T, and A_i and B_i are k by n if trans == rocblas_operation_transpose or for ssyrkx_batched and dsyrkx_batched when trans == rocblas_operation_conjugate_transpose
rocblas_operation_conjugate_transpose is not supported for complex types in csyrkx_batched and zsyrkx_batched.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill]
rocblas_fill_upper: C_i is an upper triangular matrix
rocblas_fill_lower: C_i is a lower triangular matrix
trans – [in] [rocblas_operation]
rocblas_operation_transpose: op( A_i ) = A_i^T, op( B_i ) = B_i^T
rocblas_operation_none: op( A_i ) = A_i, op( B_i ) = B_i
rocblas_operation_conjugate_transpose: op( A_i ) = A_i^T, op( B_i ) = B_i^T
n – [in] [rocblas_int] n specifies the number of rows and columns of C_i. n >= 0.
k – [in] [rocblas_int] k specifies the number of columns of op(A). k >= 0.
alpha – [in] alpha specifies the scalar alpha. When alpha is zero then A is not referenced and A need not be set before entry.
A – [in] device array of device pointers storing each matrix_i A of dimension (lda, k) when trans is rocblas_operation_none, otherwise of dimension (lda, n)
lda – [in] [rocblas_int] lda specifies the first dimension of A_i.
if trans = rocblas_operation_none, lda >= max( 1, n ), otherwise lda >= max( 1, k ).
B – [in] device array of device pointers storing each matrix_i B of dimension (ldb, k) when trans is rocblas_operation_none, otherwise of dimension (ldb, n)
ldb – [in] [rocblas_int] ldb specifies the first dimension of B.
if trans = rocblas_operation_none, ldb >= max( 1, n ), otherwise ldb >= max( 1, k ).
beta – [in] beta specifies the scalar beta. When beta is zero then C need not be set before entry.
C – [in] device array of device pointers storing each matrix C_i on the GPU. only the upper/lower triangular part of each C_i is accessed.
ldc – [in] [rocblas_int] ldc specifies the first dimension of C. ldc >= max( 1, n ).
batch_count – [in] [rocblas_int] number of instances in the batch.
-
rocblas_status rocblas_ssyrkx_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation trans, rocblas_int n, rocblas_int k, const float *alpha, const float *A, rocblas_int lda, rocblas_stride stride_A, const float *B, rocblas_int ldb, rocblas_stride stride_B, const float *beta, float *C, rocblas_int ldc, rocblas_stride stride_C, rocblas_int batch_count)#
-
rocblas_status rocblas_dsyrkx_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation trans, rocblas_int n, rocblas_int k, const double *alpha, const double *A, rocblas_int lda, rocblas_stride stride_A, const double *B, rocblas_int ldb, rocblas_stride stride_B, const double *beta, double *C, rocblas_int ldc, rocblas_stride stride_C, rocblas_int batch_count)#
-
rocblas_status rocblas_csyrkx_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation trans, rocblas_int n, rocblas_int k, const rocblas_float_complex *alpha, const rocblas_float_complex *A, rocblas_int lda, rocblas_stride stride_A, const rocblas_float_complex *B, rocblas_int ldb, rocblas_stride stride_B, const rocblas_float_complex *beta, rocblas_float_complex *C, rocblas_int ldc, rocblas_stride stride_C, rocblas_int batch_count)#
-
rocblas_status rocblas_zsyrkx_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation trans, rocblas_int n, rocblas_int k, const rocblas_double_complex *alpha, const rocblas_double_complex *A, rocblas_int lda, rocblas_stride stride_A, const rocblas_double_complex *B, rocblas_int ldb, rocblas_stride stride_B, const rocblas_double_complex *beta, rocblas_double_complex *C, rocblas_int ldc, rocblas_stride stride_C, rocblas_int batch_count)#
BLAS Level 3 API
syrkx_strided_batched performs a batch of the matrix-matrix operations for a symmetric rank-k update:
C_i := alpha*op( A_i )*op( B_i )^T + beta*C_i, where alpha and beta are scalars, op(A_i) and op(B_i) are n by k matrix, and C_i is a symmetric n x n matrix stored as either upper or lower.
This routine should only be used when the caller can guarantee that the result of op( A_i )*op( B_i )^T will be symmetric.
op( A_i ) = A_i, op( B_i ) = B_i, and A_i and B_i are n by k if trans == rocblas_operation_none op( A_i ) = A_i^T, op( B_i ) = B_i^T, and A_i and B_i are k by n if trans == rocblas_operation_transpose or for ssyrkx_strided_batched and dsyrkx_strided_batched when trans == rocblas_operation_conjugate_transpose
rocblas_operation_conjugate_transpose is not supported for complex types in csyrkx_strided_batched and zsyrkx_strided_batched.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill]
rocblas_fill_upper: C_i is an upper triangular matrix
rocblas_fill_lower: C_i is a lower triangular matrix
trans – [in] [rocblas_operation]
rocblas_operation_transpose: op( A_i ) = A_i^T, op( B_i ) = B_i^T
rocblas_operation_none: op( A_i ) = A_i, op( B_i ) = B_i
rocblas_operation_conjugate_transpose: op( A_i ) = A_i^T, op( B_i ) = B_i^T
n – [in] [rocblas_int] n specifies the number of rows and columns of C_i. n >= 0.
k – [in] [rocblas_int] k specifies the number of columns of op(A). k >= 0.
alpha – [in] alpha specifies the scalar alpha. When alpha is zero then A is not referenced and A need not be set before entry.
A – [in] Device pointer to the first matrix A_1 on the GPU of dimension (lda, k) when trans is rocblas_operation_none, otherwise of dimension (lda, n)
lda – [in] [rocblas_int] lda specifies the first dimension of A_i.
if trans = rocblas_operation_none, lda >= max( 1, n ), otherwise lda >= max( 1, k ).
stride_A – [in] [rocblas_stride] stride from the start of one matrix (A_i) and the next one (A_i+1).
B – [in] Device pointer to the first matrix B_1 on the GPU of dimension (ldb, k) when trans is rocblas_operation_none, otherwise of dimension (ldb, n).
ldb – [in] [rocblas_int] ldb specifies the first dimension of B_i.
if trans = rocblas_operation_none, ldb >= max( 1, n ), otherwise ldb >= max( 1, k ).
stride_B – [in] [rocblas_stride] stride from the start of one matrix (B_i) and the next one (B_i+1).
beta – [in] beta specifies the scalar beta. When beta is zero then C need not be set before entry.
C – [in] Device pointer to the first matrix C_1 on the GPU. only the upper/lower triangular part of each C_i is accessed.
ldc – [in] [rocblas_int] ldc specifies the first dimension of C. ldc >= max( 1, n ).
stride_C – [inout] [rocblas_stride] stride from the start of one matrix (C_i) and the next one (C_i+1).
batch_count – [in] [rocblas_int] number of instances in the batch.
rocblas_Xtrmm + batched, strided_batched#
-
rocblas_status rocblas_strmm(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const float *alpha, const float *A, rocblas_int lda, float *B, rocblas_int ldb)#
-
rocblas_status rocblas_dtrmm(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const double *alpha, const double *A, rocblas_int lda, double *B, rocblas_int ldb)#
-
rocblas_status rocblas_ctrmm(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *A, rocblas_int lda, rocblas_float_complex *B, rocblas_int ldb)#
-
rocblas_status rocblas_ztrmm(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *A, rocblas_int lda, rocblas_double_complex *B, rocblas_int ldb)#
BLAS Level 3 API
The rocBLAS trmm API is from Legacy BLAS and it supports only in-place functionality. It is deprecated and it will be replaced with an API that supports both in-place and out-of-place functionality. The new API is available in rocBLAS versions 3.x.x and later. To get the new API compile with the directive -DROCBLAS_V3
#ifndef ROCBLAS_V3 // deprecated rocblas_status rocblas_strmm(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const float* alpha, const float* A, rocblas_int lda, float* B, rocblas_int ldb) #else // available in rocBLAS version 3.x.x and later with -DROCBLAS_V3 rocblas_status rocblas_strmm(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const float* alpha, const float* A, rocblas_int lda, const float* B, rocblas_int ldb, float* C, rocblas_int ldc) #endif #ifndef ROCBLAS_V3 // deprecated rocblas_status rocblas_dtrmm(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const double* alpha, const double* A, rocblas_int lda, double* B, rocblas_int ldb) #else // available in rocBLAS version 3.x.x and later with -DROCBLAS_V3 rocblas_status rocblas_dtrmm(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const double* alpha, const double* A, rocblas_int lda, const double* B, rocblas_int ldb, double* C, rocblas_int ldc) #endif #ifndef ROCBLAS_V3 // deprecated rocblas_status rocblas_ctrmm(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const rocblas_float_complex* alpha, const rocblas_float_complex* A, rocblas_int lda, rocblas_float_complex* B, rocblas_int ldb) #else // available in rocBLAS version 3.x.x and later with -DROCBLAS_V3 rocblas_status rocblas_ctrmm(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const rocblas_float_complex* alpha, const rocblas_float_complex* A, rocblas_int lda, const rocblas_float_complex* B, rocblas_int ldb, rocblas_float_complex* C, rocblas_int ldc) #endif #ifndef ROCBLAS_V3 // deprecated rocblas_status rocblas_ztrmm(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const rocblas_double_complex* alpha, const rocblas_double_complex* A, rocblas_int lda, rocblas_double_complex* B, rocblas_int ldb) #else // available in rocBLAS version 3.x.x and later with -DROCBLAS_V3 rocblas_status rocblas_ztrmm(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const rocblas_double_complex* alpha, const rocblas_double_complex* A, rocblas_int lda, const rocblas_double_complex* B, rocblas_int ldb, rocblas_double_complex* C, rocblas_int ldc) #endif
The deprecated Legacy BLAS in-place trmm performs one of the matrix-matrix operations:
B := alpha*op( A )*B, or B := alpha*B*op( A ),
The new trmm performs one of the matrix-matrix operations:
C := alpha*op( A )*B, or C := alpha*B*op( A ),
The in-place functionality is still available in the new trmmm by setting pointer C equal to pointer B, and ldc equal to ldb.
alpha is a scalar, B is an m by n matrix, C is an m by n matrix, A is a unit, or non-unit, upper or lower triangular matrix and op( A ) is one of op( A ) = A or op( A ) = A^T or op( A ) = A^H. When uplo == rocblas_fill_upper the leading k by k upper triangular part of the array A must contain the upper triangular matrix and the strictly lower triangular part of A is not referenced. Here k is m when side == rocblas_side_left and is n when side == rocblas_side_right. When uplo == rocblas_fill_lower the leading k by k lower triangular part of the array A must contain the lower triangular matrix and the strictly upper triangular part of A is not referenced. Here k is m when side == rocblas_side_left and is n when side == rocblas_side_right. Note that when diag == rocblas_diagonal_unit the diagonal elements of A are not referenced either, but are assumed to be unity.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
side – [in] [rocblas_side] Specifies whether op(A) multiplies B from the left or right as follows:
rocblas_side_left: B := alpha*op( A )*B
rocblas_side_right: B := alpha*B*op( A )
uplo – [in] [rocblas_fill] Specifies whether the matrix A is an upper or lower triangular matrix as follows:
rocblas_fill_upper: A is an upper triangular matrix.
rocblas_fill_lower: A is a lower triangular matrix.
transA – [in] [rocblas_operation] Specifies the form of op(A) to be used in the matrix multiplication as follows:
rocblas_operation_none: op(A) = A
rocblas_operation_transpose: op(A) = A^T
rocblas_operation_conjugate_transpose: op(A) = A^H
diag – [in] [rocblas_diagonal] Specifies whether or not A is unit triangular as follows:
rocblas_diagonal_unit: A is assumed to be unit triangular.
rocblas_diagonal_non_unit: A is not assumed to be unit triangular.
m – [in] [rocblas_int] m specifies the number of rows of B. m >= 0.
n – [in] [rocblas_int] n specifies the number of columns of B. n >= 0.
alpha – [in] alpha specifies the scalar alpha. When alpha is zero then A is not referenced and B need not be set before entry.
A – [in] Device pointer to matrix A on the GPU. A has dimension ( lda, k ), where k is m when side == rocblas_side_left and is n when side == rocblas_side_right.
lda – [in] [rocblas_int] lda specifies the first dimension of A.
if side == rocblas_side_left, lda >= max( 1, m ), if side == rocblas_side_right, lda >= max( 1, n ).
B – [inout] Device pointer to the first matrix B_0 on the GPU. On entry, the leading m by n part of the array B must contain the matrix B, and on exit is overwritten by the transformed matrix.
ldb – [in] [rocblas_int] ldb specifies the first dimension of B. ldb >= max( 1, m ).
-
rocblas_status rocblas_strmm_batched(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const float *alpha, const float *const A[], rocblas_int lda, float *const B[], rocblas_int ldb, rocblas_int batch_count)#
-
rocblas_status rocblas_dtrmm_batched(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const double *alpha, const double *const A[], rocblas_int lda, double *const B[], rocblas_int ldb, rocblas_int batch_count)#
-
rocblas_status rocblas_ctrmm_batched(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *const A[], rocblas_int lda, rocblas_float_complex *const B[], rocblas_int ldb, rocblas_int batch_count)#
-
rocblas_status rocblas_ztrmm_batched(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *const A[], rocblas_int lda, rocblas_double_complex *const B[], rocblas_int ldb, rocblas_int batch_count)#
BLAS Level 3 API
The rocBLAS trmm_batched API is from Legacy BLAS and it supports only in-place functionality. It is deprecated and it will be replaced with an API that supports both in-place and out-of-place functionality. The new API is available in rocBLAS versions 3.x.x and later. To get the new API compile with the directive -DROCBLAS_V3.
#ifndef ROCBLAS_V3 // deprecated rocblas_status rocblas_strmm_batched(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const float* alpha, const float* const A[], rocblas_int lda, float* const B[], rocblas_int ldb, rocblas_int batch_count) #else // available in rocBLAS version 3.x.x and later with -DROCBLAS_V3 rocblas_status rocblas_strmm_batched(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const float* alpha, const float* const A[], rocblas_int lda, const float* const B[], rocblas_int ldb, float* const C[], rocblas_int ldc, rocblas_int batch_count) #endif #ifndef ROCBLAS_V3 // deprecated rocblas_status rocblas_dtrmm_batched(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const double* alpha, const double* const A[], rocblas_int lda, double* const B[], rocblas_int ldb, rocblas_int batch_count) #else // available in rocBLAS version 3.x.x and later with -DROCBLAS_V3 rocblas_status rocblas_dtrmm_batched(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const double* alpha, const double* const A[], rocblas_int lda, const double* const B[], rocblas_int ldb, double* const C[], rocblas_int ldc, rocblas_int batch_count) #endif #ifndef ROCBLAS_V3 // deprecated rocblas_status rocblas_ctrmm_batched(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const rocblas_float_complex* alpha, const rocblas_float_complex* const A[], rocblas_int lda, rocblas_float_complex* const B[], rocblas_int ldb, rocblas_int batch_count) #else // available in rocBLAS version 3.x.x and later with -DROCBLAS_V3 rocblas_status rocblas_ctrmm_batched(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const rocblas_float_complex* alpha, const rocblas_float_complex* const A[], rocblas_int lda, const rocblas_float_complex* const B[], rocblas_int ldb, rocblas_float_complex* const C[], rocblas_int ldc, rocblas_int batch_count) #endif #ifndef ROCBLAS_V3 // deprecated rocblas_status rocblas_ztrmm_batched(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const rocblas_double_complex* alpha, const rocblas_double_complex* const A[], rocblas_int lda, rocblas_double_complex* const B[], rocblas_int ldb, rocblas_int batch_count) #else // available in rocBLAS version 3.x.x and later with -DROCBLAS_V3 rocblas_status rocblas_ztrmm_batched(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const rocblas_double_complex* alpha, const rocblas_double_complex* const A[], rocblas_int lda, const rocblas_double_complex* const B[], rocblas_int ldb, rocblas_double_complex* const C[], rocblas_int ldc, rocblas_int batch_count) #endif
The deprecated Legacy BLAS in-place trmm_batched performs one of the batched matrix-matrix operations:
B_i := alpha*op( A_i )*B_i, or B_i := alpha*B_i*op( A_i ) for i = 0, 1, ... batch_count -1,
The new trmm_batched performs one of the matrix-matrix operations:
C_i := alpha*op( A_i )*B_i, or C_i := alpha*B_i*op( A_i ) for i = 0, 1, ... batch_count -1,
The in-place functionality is still available in the new trmmm_batched by setting pointer C equal to pointer B and ldc equal to ldb.
alpha is a scalar, B_i is an m by n matrix, C_i is an m by n matrix, A_i is a unit, or non-unit, upper or lower triangular matrix and op( A_i ) is one of op( A_i ) = A_i or op( A_i ) = A_i^T or op( A_i ) = A_i^H.
Note that when diag == rocblas_diagonal_unit the diagonal elements of A_i are not referenced either, but are assumed to be unity.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
side – [in] [rocblas_side] Specifies whether op(A_i) multiplies B_i from the left or right as follows:
rocblas_side_left: B_i := alpha*op( A_i )*B_i
rocblas_side_right: B_i := alpha*B_i*op( A_i )
uplo – [in] [rocblas_fill] Specifies whether the matrix A is an upper or lower triangular matrix as follows:
rocblas_fill_upper: A is an upper triangular matrix.
rocblas_fill_lower: A is a lower triangular matrix.
transA – [in] [rocblas_operation] Specifies the form of op(A_i) to be used in the matrix multiplication as follows:
rocblas_operation_none: op(A_i) = A_i
rocblas_operation_transpose: op(A_i) = A_i^T
rocblas_operation_conjugate_transpose: op(A_i) = A_i^H
diag – [in] [rocblas_diagonal] Specifies whether or not A_i is unit triangular as follows:
rocblas_diagonal_unit: A_i is assumed to be unit triangular.
rocblas_diagonal_non_unit: A_i is not assumed to be unit triangular.
m – [in] [rocblas_int] m specifies the number of rows of B_i. m >= 0.
n – [in] [rocblas_int] n specifies the number of columns of B_i. n >= 0.
alpha – [in] alpha specifies the scalar alpha. When alpha is zero then A_i is not referenced and B_i need not be set before entry.
A – [in] Device array of device pointers storing each matrix A_i on the GPU. Each A_i is of dimension ( lda, k ), where k is m when side == rocblas_side_left and is n when side == rocblas_side_right.
When uplo == rocblas_fill_upper the leading k by k upper triangular part of the array A must contain the upper triangular matrix and the strictly lower triangular part of A is not referenced. When uplo == rocblas_fill_lower the leading k by k lower triangular part of the array A must contain the lower triangular matrix and the strictly upper triangular part of A is not referenced.
lda – [in] [rocblas_int] lda specifies the first dimension of A.
if side == rocblas_side_left, lda >= max( 1, m ), if side == rocblas_side_right, lda >= max( 1, n ).
B – [inout] device array of device pointers storing each matrix B_i on the GPU. On entry, the leading m by n part of the array B_i must contain the matrix B_i, and on exit is overwritten by the transformed matrix.
ldb – [in] [rocblas_int] ldb specifies the first dimension of B_i. ldb >= max( 1, m ).
batch_count – [in] [rocblas_int] number of instances i in the batch.
-
rocblas_status rocblas_strmm_strided_batched(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const float *alpha, const float *A, rocblas_int lda, rocblas_stride stride_A, float *B, rocblas_int ldb, rocblas_stride stride_B, rocblas_int batch_count)#
-
rocblas_status rocblas_dtrmm_strided_batched(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const double *alpha, const double *A, rocblas_int lda, rocblas_stride stride_A, double *B, rocblas_int ldb, rocblas_stride stride_B, rocblas_int batch_count)#
-
rocblas_status rocblas_ctrmm_strided_batched(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *A, rocblas_int lda, rocblas_stride stride_A, rocblas_float_complex *B, rocblas_int ldb, rocblas_stride stride_B, rocblas_int batch_count)#
-
rocblas_status rocblas_ztrmm_strided_batched(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *A, rocblas_int lda, rocblas_stride stride_A, rocblas_double_complex *B, rocblas_int ldb, rocblas_stride stride_B, rocblas_int batch_count)#
BLAS Level 3 API
The rocBLAS trmm_strided_batched API is from Legacy BLAS and it supports only in-place functionality. It is deprecated and it will be replaced with an API that supports both in-place and out-of-place functionality. The new API is available in rocBLAS versions 3.x.x and later. To get the new API compile with the directive -DROCBLAS_V3.
#ifndef ROCBLAS_V3 // deprecated rocblas_status rocblas_strmm_strided_batched(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const float* alpha, const float* A, rocblas_int lda, rocblas_stride stride_A, float* B, rocblas_int ldb, rocblas_stride stride_B, rocblas_int batch_count) #else // available in rocBLAS version 3.x.x and later with -DROCBLAS_V3 rocblas_status rocblas_strmm_strided_batched(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const float* alpha, const float* A, rocblas_int lda, rocblas_stride stride_A, const float* B, rocblas_int ldb, rocblas_stride stride_B, float* C, rocblas_int ldc, rocblas_stride stride_C, rocblas_int batch_count) #endif #ifndef ROCBLAS_V3 // deprecated rocblas_status rocblas_dtrmm_strided_batched(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const double* alpha, const double* A, rocblas_int lda, rocblas_stride stride_A, double* B, rocblas_int ldb, rocblas_stride stride_B, rocblas_int batch_count) #else // available in rocBLAS version 3.x.x and later with -DROCBLAS_V3 rocblas_status rocblas_dtrmm_strided_batched(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const double* alpha, const double* A, rocblas_int lda, rocblas_stride stride_A, const double* B, rocblas_int ldb, rocblas_stride stride_B, double* C, rocblas_int ldc, rocblas_stride stride_C, rocblas_int batch_count) #endif #ifndef ROCBLAS_V3 // deprecated rocblas_status rocblas_ctrmm_strided_batched(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const rocblas_float_complex* alpha, const rocblas_float_complex* A, rocblas_int lda, rocblas_stride stride_A, rocblas_float_complex* B, rocblas_int ldb, rocblas_stride stride_B, rocblas_int batch_count) #else // available in rocBLAS version 3.x.x and later with -DROCBLAS_V3 rocblas_status rocblas_ctrmm_strided_batched(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const rocblas_float_complex* alpha, const rocblas_float_complex* A, rocblas_int lda, rocblas_stride stride_A, const rocblas_float_complex* B, rocblas_int ldb, rocblas_stride stride_B, rocblas_float_complex* C, rocblas_int ldc, rocblas_stride stride_C, rocblas_int batch_count) #endif #ifndef ROCBLAS_V3 // deprecated rocblas_status rocblas_ztrmm_strided_batched(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const rocblas_double_complex* alpha, const rocblas_double_complex* A, rocblas_int lda, rocblas_stride stride_A, rocblas_double_complex* B, rocblas_int ldb, rocblas_stride stride_B, rocblas_int batch_count) #else // available in rocBLAS version 3.x.x and later with -DROCBLAS_V3 rocblas_status rocblas_ztrmm_strided_batched(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const rocblas_double_complex* alpha, const rocblas_double_complex* A, rocblas_int lda, rocblas_stride stride_A, const rocblas_double_complex* B, rocblas_int ldb, rocblas_stride stride_B, rocblas_double_complex* C, rocblas_int ldc, rocblas_stride stride_C, rocblas_int batch_count) #endif
The deprecated Legacy BLAS in-place trmm_strided_batched performs one of the strided_batched matrix-matrix operations:
B_i := alpha*op( A_i )*B_i, or B_i := alpha*B_i*op( A_i ) for i = 0, 1, ... batch_count -1,
The new trmm_batched performs one of the matrix-matrix operations:
C_i := alpha*op( A_i )*B_i, or C_i := alpha*B_i*op( A_i ) for i = 0, 1, ... batch_count -1,
The in-place functionality is still available in the new trmmm_batched by setting pointer C equal to pointer B, setting ldc equal to ldb, and setting stride_C equal to stride_B.
alpha is a scalar, B_i is an m by n matrix, C_i is an m by n matrix, A_i is a unit, or non-unit, upper or lower triangular matrix and op( A_i ) is one of op( A_i ) = A_i or op( A_i ) = A_i^T or op( A_i ) = A_i^H.
Note that when diag == rocblas_diagonal_unit the diagonal elements of A_i are not referenced either, but are assumed to be unity.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
side – [in] [rocblas_side] Specifies whether op(A_i) multiplies B_i from the left or right as follows:
rocblas_side_left: B_i := alpha*op( A_i )*B_i
rocblas_side_right: B_i := alpha*B_i*op( A_i )
uplo – [in] [rocblas_fill] Specifies whether the matrix A is an upper or lower triangular matrix as follows:
rocblas_fill_upper: A is an upper triangular matrix
rocblas_fill_lower: A is a lower triangular matrix
transA – [in] [rocblas_operation] Specifies the form of op(A_i) to be used in the matrix multiplication as follows:
rocblas_operation_none: op(A_i) = A_i
rocblas_operation_transpose: op(A_i) = A_i^T
rocblas_operation_conjugate_transpose: op(A_i) = A_i^H
diag – [in] [rocblas_diagonal] Specifies whether or not A_i is unit triangular as follows:
rocblas_diagonal_unit: A_i is assumed to be unit triangular.
rocblas_diagonal_non_unit: A_i is not assumed to be unit triangular.
m – [in] [rocblas_int] m specifies the number of rows of B_i. m >= 0.
n – [in] [rocblas_int] n specifies the number of columns of B_i. n >= 0.
alpha – [in] alpha specifies the scalar alpha. When alpha is zero then A_i is not referenced and B_i need not be set before entry.
A – [in] Device pointer to the first matrix A_0 on the GPU. Each A_i is of dimension ( lda, k ), where k is m when side == rocblas_side_left and is n when side == rocblas_side_right.
When uplo == rocblas_fill_upper the leading k by k upper triangular part of the array A must contain the upper triangular matrix and the strictly lower triangular part of A is not referenced. When uplo == rocblas_fill_lower the leading k by k lower triangular part of the array A must contain the lower triangular matrix and the strictly upper triangular part of A is not referenced.
lda – [in] [rocblas_int] lda specifies the first dimension of A.
if side == rocblas_side_left, lda >= max( 1, m ), if side == rocblas_side_right, lda >= max( 1, n ).
stride_A – [in] [rocblas_stride] stride from the start of one matrix (A_i) and the next one (A_i+1).
B – [inout] Device pointer to the first matrix B_0 on the GPU. On entry, the leading m by n part of the array B_i must contain the matrix B_i, and on exit is overwritten by the transformed matrix.
ldb – [in] [rocblas_int] ldb specifies the first dimension of B_i. ldb >= max( 1, m ).
stride_B – [in] [rocblas_stride] stride from the start of one matrix (B_i) and the next one (B_i+1).
batch_count – [in] [rocblas_int] number of instances i in the batch.
rocblas_Xtrsm + batched, strided_batched#
-
rocblas_status rocblas_strsm(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const float *alpha, const float *A, rocblas_int lda, float *B, rocblas_int ldb)#
-
rocblas_status rocblas_dtrsm(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const double *alpha, const double *A, rocblas_int lda, double *B, rocblas_int ldb)#
-
rocblas_status rocblas_ctrsm(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *A, rocblas_int lda, rocblas_float_complex *B, rocblas_int ldb)#
-
rocblas_status rocblas_ztrsm(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *A, rocblas_int lda, rocblas_double_complex *B, rocblas_int ldb)#
BLAS Level 3 API
trsm solves:
op(A)*X = alpha*B or X*op(A) = alpha*B, where alpha is a scalar, X and B are m by n matrices, A is triangular matrix and op(A) is one of op( A ) = A or op( A ) = A^T or op( A ) = A^H. The matrix X is overwritten on B.
Note about memory allocation: When trsm is launched with a k evenly divisible by the internal block size of 128, and is no larger than 10 of these blocks, the API takes advantage of utilizing pre-allocated memory found in the handle to increase overall performance. This memory can be managed by using the environment variable WORKBUF_TRSM_B_CHNK. When this variable is not set the device memory used for temporary storage will default to 1 MB and may result in chunking, which in turn may reduce performance. Under these circumstances it is recommended that WORKBUF_TRSM_B_CHNK be set to the desired chunk of right hand sides to be used at a time (where k is m when rocblas_side_left and is n when rocblas_side_right).
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
side – [in] [rocblas_side]
rocblas_side_left: op(A)*X = alpha*B
rocblas_side_right: X*op(A) = alpha*B
uplo – [in] [rocblas_fill]
rocblas_fill_upper: A is an upper triangular matrix.
rocblas_fill_lower: A is a lower triangular matrix.
transA – [in] [rocblas_operation]
transB: op(A) = A.
rocblas_operation_transpose: op(A) = A^T
rocblas_operation_conjugate_transpose: op(A) = A^H
diag – [in] [rocblas_diagonal]
rocblas_diagonal_unit: A is assumed to be unit triangular.
rocblas_diagonal_non_unit: A is not assumed to be unit triangular.
m – [in] [rocblas_int] m specifies the number of rows of B. m >= 0.
n – [in] [rocblas_int] n specifies the number of columns of B. n >= 0.
alpha – [in] device pointer or host pointer specifying the scalar alpha. When alpha is &zero then A is not referenced and B need not be set before entry.
A – [in] device pointer storing matrix A. of dimension ( lda, k ), where k is m when rocblas_side_left and is n when rocblas_side_right only the upper/lower triangular part is accessed.
lda – [in] [rocblas_int] lda specifies the first dimension of A.
if side = rocblas_side_left, lda >= max( 1, m ), if side = rocblas_side_right, lda >= max( 1, n ).
B – [inout] device pointer storing matrix B.
ldb – [in] [rocblas_int] ldb specifies the first dimension of B. ldb >= max( 1, m ).
-
rocblas_status rocblas_strsm_batched(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const float *alpha, const float *const A[], rocblas_int lda, float *const B[], rocblas_int ldb, rocblas_int batch_count)#
-
rocblas_status rocblas_dtrsm_batched(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const double *alpha, const double *const A[], rocblas_int lda, double *const B[], rocblas_int ldb, rocblas_int batch_count)#
-
rocblas_status rocblas_ctrsm_batched(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *const A[], rocblas_int lda, rocblas_float_complex *const B[], rocblas_int ldb, rocblas_int batch_count)#
-
rocblas_status rocblas_ztrsm_batched(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *const A[], rocblas_int lda, rocblas_double_complex *const B[], rocblas_int ldb, rocblas_int batch_count)#
BLAS Level 3 API
trsm_batched performs the following batched operation:
op(A_i)*X_i = alpha*B_i or X_i*op(A_i) = alpha*B_i, for i = 1, ..., batch_count, where alpha is a scalar, X and B are batched m by n matrices, A is triangular batched matrix and op(A) is one of op( A ) = A or op( A ) = A^T or op( A ) = A^H. Each matrix X_i is overwritten on B_i for i = 1, ..., batch_count.
Note about memory allocation: When trsm is launched with a k evenly divisible by the internal block size of 128, and is no larger than 10 of these blocks, the API takes advantage of utilizing pre-allocated memory found in the handle to increase overall performance. This memory can be managed by using the environment variable WORKBUF_TRSM_B_CHNK. When this variable is not set the device memory used for temporary storage will default to 1 MB and may result in chunking, which in turn may reduce performance. Under these circumstances it is recommended that WORKBUF_TRSM_B_CHNK be set to the desired chunk of right hand sides to be used at a time (where k is m when rocblas_side_left and is n when rocblas_side_right).
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
side – [in] [rocblas_side]
rocblas_side_left: op(A)*X = alpha*B
rocblas_side_right: X*op(A) = alpha*B
uplo – [in] [rocblas_fill]
rocblas_fill_upper: each A_i is an upper triangular matrix.
rocblas_fill_lower: each A_i is a lower triangular matrix.
transA – [in] [rocblas_operation]
transB: op(A) = A
rocblas_operation_transpose: op(A) = A^T
rocblas_operation_conjugate_transpose: op(A) = A^H
diag – [in] [rocblas_diagonal]
rocblas_diagonal_unit: each A_i is assumed to be unit triangular.
rocblas_diagonal_non_unit: each A_i is not assumed to be unit triangular.
m – [in] [rocblas_int] m specifies the number of rows of each B_i. m >= 0.
n – [in] [rocblas_int] n specifies the number of columns of each B_i. n >= 0.
alpha – [in] device pointer or host pointer specifying the scalar alpha. When alpha is &zero then A is not referenced and B need not be set before entry.
A – [in] device array of device pointers storing each matrix A_i on the GPU. Matricies are of dimension ( lda, k ), where k is m when rocblas_side_left and is n when rocblas_side_right only the upper/lower triangular part is accessed.
lda – [in] [rocblas_int] lda specifies the first dimension of each A_i.
if side = rocblas_side_left, lda >= max( 1, m ), if side = rocblas_side_right, lda >= max( 1, n ).
B – [inout] device array of device pointers storing each matrix B_i on the GPU.
ldb – [in] [rocblas_int] ldb specifies the first dimension of each B_i. ldb >= max( 1, m ).
batch_count – [in] [rocblas_int] number of trsm operatons in the batch.
-
rocblas_status rocblas_strsm_strided_batched(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const float *alpha, const float *A, rocblas_int lda, rocblas_stride stride_a, float *B, rocblas_int ldb, rocblas_stride stride_b, rocblas_int batch_count)#
-
rocblas_status rocblas_dtrsm_strided_batched(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const double *alpha, const double *A, rocblas_int lda, rocblas_stride stride_a, double *B, rocblas_int ldb, rocblas_stride stride_b, rocblas_int batch_count)#
-
rocblas_status rocblas_ctrsm_strided_batched(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *A, rocblas_int lda, rocblas_stride stride_a, rocblas_float_complex *B, rocblas_int ldb, rocblas_stride stride_b, rocblas_int batch_count)#
-
rocblas_status rocblas_ztrsm_strided_batched(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *A, rocblas_int lda, rocblas_stride stride_a, rocblas_double_complex *B, rocblas_int ldb, rocblas_stride stride_b, rocblas_int batch_count)#
BLAS Level 3 API
trsm_srided_batched performs the following strided batched operation:
op(A_i)*X_i = alpha*B_i or X_i*op(A_i) = alpha*B_i, for i = 1, ..., batch_count, where alpha is a scalar, X and B are strided batched m by n matrices, A is triangular strided batched matrix and op(A) is one of op( A ) = A or op( A ) = A^T or op( A ) = A^H. Each matrix X_i is overwritten on B_i for i = 1, ..., batch_count.
Note about memory allocation: When trsm is launched with a k evenly divisible by the internal block size of 128, and is no larger than 10 of these blocks, the API takes advantage of utilizing pre-allocated memory found in the handle to increase overall performance. This memory can be managed by using the environment variable WORKBUF_TRSM_B_CHNK. When this variable is not set the device memory used for temporary storage will default to 1 MB and may result in chunking, which in turn may reduce performance. Under these circumstances it is recommended that WORKBUF_TRSM_B_CHNK be set to the desired chunk of right hand sides to be used at a time (where k is m when rocblas_side_left and is n when rocblas_side_right).
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
side – [in] [rocblas_side]
rocblas_side_left: op(A)*X = alpha*B.
rocblas_side_right: X*op(A) = alpha*B.
uplo – [in] [rocblas_fill]
rocblas_fill_upper: each A_i is an upper triangular matrix.
rocblas_fill_lower: each A_i is a lower triangular matrix.
transA – [in] [rocblas_operation]
transB: op(A) = A.
rocblas_operation_transpose: op(A) = A^T.
rocblas_operation_conjugate_transpose: op(A) = A^H.
diag – [in] [rocblas_diagonal]
rocblas_diagonal_unit: each A_i is assumed to be unit triangular.
rocblas_diagonal_non_unit: each A_i is not assumed to be unit triangular.
m – [in] [rocblas_int] m specifies the number of rows of each B_i. m >= 0.
n – [in] [rocblas_int] n specifies the number of columns of each B_i. n >= 0.
alpha – [in] device pointer or host pointer specifying the scalar alpha. When alpha is &zero then A is not referenced and B need not be set before entry.
A – [in] device pointer pointing to the first matrix A_1. of dimension ( lda, k ), where k is m when rocblas_side_left and is n when rocblas_side_right only the upper/lower triangular part is accessed.
lda – [in] [rocblas_int] lda specifies the first dimension of each A_i.
if side = rocblas_side_left, lda >= max( 1, m ). if side = rocblas_side_right, lda >= max( 1, n ).
stride_a – [in] [rocblas_stride] stride from the start of one A_i matrix to the next A_(i + 1).
B – [inout] device pointer pointing to the first matrix B_1.
ldb – [in] [rocblas_int] ldb specifies the first dimension of each B_i. ldb >= max( 1, m ).
stride_b – [in] [rocblas_stride] stride from the start of one B_i matrix to the next B_(i + 1).
batch_count – [in] [rocblas_int] number of trsm operatons in the batch.
rocblas_Xhemm + batched, strided_batched#
-
rocblas_status rocblas_chemm(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_int m, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *A, rocblas_int lda, const rocblas_float_complex *B, rocblas_int ldb, const rocblas_float_complex *beta, rocblas_float_complex *C, rocblas_int ldc)#
-
rocblas_status rocblas_zhemm(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_int m, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *A, rocblas_int lda, const rocblas_double_complex *B, rocblas_int ldb, const rocblas_double_complex *beta, rocblas_double_complex *C, rocblas_int ldc)#
BLAS Level 3 API
hemm performs one of the matrix-matrix operations:
C := alpha*A*B + beta*C if side == rocblas_side_left, C := alpha*B*A + beta*C if side == rocblas_side_right, where alpha and beta are scalars, B and C are m by n matrices, and A is a Hermitian matrix stored as either upper or lower.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
side – [in] [rocblas_side]
rocblas_side_left: C := alpha*A*B + beta*C
rocblas_side_right: C := alpha*B*A + beta*C
uplo – [in] [rocblas_fill]
rocblas_fill_upper: A is an upper triangular matrix
rocblas_fill_lower: A is a lower triangular matrix
m – [in] [rocblas_int] m specifies the number of rows of B and C. m >= 0.
n – [in] [rocblas_int] n specifies the number of columns of B and C. n >= 0.
alpha – [in] alpha specifies the scalar alpha. When alpha is zero then A and B are not referenced.
A – [in] pointer storing matrix A on the GPU.
A is m by m if side == rocblas_side_left
A is n by n if side == rocblas_side_right Only the upper/lower triangular part is accessed. The imaginary component of the diagonal elements is not used.
lda – [in] [rocblas_int] lda specifies the first dimension of A.
if side = rocblas_side_left, lda >= max( 1, m ), otherwise lda >= max( 1, n ).
B – [in] pointer storing matrix B on the GPU. Matrix dimension is m by n
ldb – [in] [rocblas_int] ldb specifies the first dimension of B. ldb >= max( 1, m ).
beta – [in] beta specifies the scalar beta. When beta is zero then C need not be set before entry.
C – [in] pointer storing matrix C on the GPU. Matrix dimension is m by n
ldc – [in] [rocblas_int] ldc specifies the first dimension of C. ldc >= max( 1, m ).
-
rocblas_status rocblas_chemm_batched(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_int m, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *const A[], rocblas_int lda, const rocblas_float_complex *const B[], rocblas_int ldb, const rocblas_float_complex *beta, rocblas_float_complex *const C[], rocblas_int ldc, rocblas_int batch_count)#
-
rocblas_status rocblas_zhemm_batched(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_int m, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *const A[], rocblas_int lda, const rocblas_double_complex *const B[], rocblas_int ldb, const rocblas_double_complex *beta, rocblas_double_complex *const C[], rocblas_int ldc, rocblas_int batch_count)#
BLAS Level 3 API
hemm_batched performs a batch of the matrix-matrix operations:
C_i := alpha*A_i*B_i + beta*C_i if side == rocblas_side_left, C_i := alpha*B_i*A_i + beta*C_i if side == rocblas_side_right, where alpha and beta are scalars, B_i and C_i are m by n matrices, and A_i is a Hermitian matrix stored as either upper or lower.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
side – [in] [rocblas_side]
rocblas_side_left: C_i := alpha*A_i*B_i + beta*C_i
rocblas_side_right: C_i := alpha*B_i*A_i + beta*C_i
uplo – [in] [rocblas_fill]
rocblas_fill_upper: A_i is an upper triangular matrix
rocblas_fill_lower: A_i is a lower triangular matrix
m – [in] [rocblas_int] m specifies the number of rows of B_i and C_i. m >= 0.
n – [in] [rocblas_int] n specifies the number of columns of B_i and C_i. n >= 0.
alpha – [in] alpha specifies the scalar alpha. When alpha is zero then A_i and B_i are not referenced.
A – [in] device array of device pointers storing each matrix A_i on the GPU.
A_i is m by m if side == rocblas_side_left
A_i is n by n if side == rocblas_side_right Only the upper/lower triangular part is accessed. The imaginary component of the diagonal elements is not used.
lda – [in] [rocblas_int] lda specifies the first dimension of A_i.
if side = rocblas_side_left, lda >= max( 1, m ), otherwise lda >= max( 1, n ).
B – [in] device array of device pointers storing each matrix B_i on the GPU. Matrix dimension is m by n
ldb – [in] [rocblas_int] ldb specifies the first dimension of B_i. ldb >= max( 1, m ).
beta – [in] beta specifies the scalar beta. When beta is zero then C_i need not be set before entry.
C – [in] device array of device pointers storing each matrix C_i on the GPU. Matrix dimension is m by n
ldc – [in] [rocblas_int] ldc specifies the first dimension of C_i. ldc >= max( 1, m ).
batch_count – [in] [rocblas_int] number of instances in the batch.
-
rocblas_status rocblas_chemm_strided_batched(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_int m, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *A, rocblas_int lda, rocblas_stride stride_A, const rocblas_float_complex *B, rocblas_int ldb, rocblas_stride stride_B, const rocblas_float_complex *beta, rocblas_float_complex *C, rocblas_int ldc, rocblas_stride stride_C, rocblas_int batch_count)#
-
rocblas_status rocblas_zhemm_strided_batched(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_int m, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *A, rocblas_int lda, rocblas_stride stride_A, const rocblas_double_complex *B, rocblas_int ldb, rocblas_stride stride_B, const rocblas_double_complex *beta, rocblas_double_complex *C, rocblas_int ldc, rocblas_stride stride_C, rocblas_int batch_count)#
BLAS Level 3 API
hemm_strided_batched performs a batch of the matrix-matrix operations:
C_i := alpha*A_i*B_i + beta*C_i if side == rocblas_side_left, C_i := alpha*B_i*A_i + beta*C_i if side == rocblas_side_right, where alpha and beta are scalars, B_i and C_i are m by n matrices, and A_i is a Hermitian matrix stored as either upper or lower.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
side – [in] [rocblas_side]
rocblas_side_left: C_i := alpha*A_i*B_i + beta*C_i
rocblas_side_right: C_i := alpha*B_i*A_i + beta*C_i
uplo – [in] [rocblas_fill]
rocblas_fill_upper: A_i is an upper triangular matrix
rocblas_fill_lower: A_i is a lower triangular matrix
m – [in] [rocblas_int] m specifies the number of rows of B_i and C_i. m >= 0.
n – [in] [rocblas_int] n specifies the number of columns of B_i and C_i. n >= 0.
alpha – [in] alpha specifies the scalar alpha. When alpha is zero then A_i and B_i are not referenced.
A – [in] device pointer to first matrix A_1
A_i is m by m if side == rocblas_side_left
A_i is n by n if side == rocblas_side_right Only the upper/lower triangular part is accessed. The imaginary component of the diagonal elements is not used.
lda – [in] [rocblas_int] lda specifies the first dimension of A_i.
if side = rocblas_side_left, lda >= max( 1, m ), otherwise lda >= max( 1, n ).
stride_A – [in] [rocblas_stride] stride from the start of one matrix (A_i) and the next one (A_i+1).
B – [in] device pointer to first matrix B_1 of dimension (ldb, n) on the GPU
ldb – [in] [rocblas_int] ldb specifies the first dimension of B_i.
if side = rocblas_operation_none, ldb >= max( 1, m ), otherwise ldb >= max( 1, n ).
stride_B – [in] [rocblas_stride] stride from the start of one matrix (B_i) and the next one (B_i+1).
beta – [in] beta specifies the scalar beta. When beta is zero then C need not be set before entry.
C – [in] device pointer to first matrix C_1 of dimension (ldc, n) on the GPU.
ldc – [in] [rocblas_int] ldc specifies the first dimension of C. ldc >= max( 1, m ).
stride_C – [inout] [rocblas_stride] stride from the start of one matrix (C_i) and the next one (C_i+1).
batch_count – [in] [rocblas_int] number of instances in the batch.
rocblas_Xherk + batched, strided_batched#
-
rocblas_status rocblas_cherk(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_int n, rocblas_int k, const float *alpha, const rocblas_float_complex *A, rocblas_int lda, const float *beta, rocblas_float_complex *C, rocblas_int ldc)#
-
rocblas_status rocblas_zherk(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_int n, rocblas_int k, const double *alpha, const rocblas_double_complex *A, rocblas_int lda, const double *beta, rocblas_double_complex *C, rocblas_int ldc)#
BLAS Level 3 API
herk performs one of the matrix-matrix operations for a Hermitian rank-k update:
C := alpha*op( A )*op( A )^H + beta*C, where alpha and beta are scalars, op(A) is an n by k matrix, and C is a n x n Hermitian matrix stored as either upper or lower. op( A ) = A, and A is n by k if transA == rocblas_operation_none op( A ) = A^H and A is k by n if transA == rocblas_operation_conjugate_transpose
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill]
rocblas_fill_upper: C is an upper triangular matrix
rocblas_fill_lower: C is a lower triangular matrix
transA – [in] [rocblas_operation]
rocblas_operation_conjugate_transpose: op(A) = A^H
rocblas_operation_none: op(A) = A
n – [in] [rocblas_int] n specifies the number of rows and columns of C. n >= 0.
k – [in] [rocblas_int] k specifies the number of columns of op(A). k >= 0.
alpha – [in] alpha specifies the scalar alpha. When alpha is zero then A is not referenced and A need not be set before entry.
A – [in] pointer storing matrix A on the GPU. Matrix dimension is ( lda, k ) when if transA = rocblas_operation_none, otherwise (lda, n)
lda – [in] [rocblas_int] lda specifies the first dimension of A.
if transA = rocblas_operation_none, lda >= max( 1, n ), otherwise lda >= max( 1, k ).
beta – [in] beta specifies the scalar beta. When beta is zero then C need not be set before entry.
C – [in] pointer storing matrix C on the GPU. The imaginary component of the diagonal elements are not used but are set to zero unless quick return. only the upper/lower triangular part is accessed.
ldc – [in] [rocblas_int] ldc specifies the first dimension of C. ldc >= max( 1, n ).
-
rocblas_status rocblas_cherk_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_int n, rocblas_int k, const float *alpha, const rocblas_float_complex *const A[], rocblas_int lda, const float *beta, rocblas_float_complex *const C[], rocblas_int ldc, rocblas_int batch_count)#
-
rocblas_status rocblas_zherk_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_int n, rocblas_int k, const double *alpha, const rocblas_double_complex *const A[], rocblas_int lda, const double *beta, rocblas_double_complex *const C[], rocblas_int ldc, rocblas_int batch_count)#
BLAS Level 3 API
herk_batched performs a batch of the matrix-matrix operations for a Hermitian rank-k update:
C_i := alpha*op( A_i )*op( A_i )^H + beta*C_i, where alpha and beta are scalars, op(A) is an n by k matrix, and C_i is a n x n Hermitian matrix stored as either upper or lower. op( A_i ) = A_i, and A_i is n by k if transA == rocblas_operation_none op( A_i ) = A_i^H and A_i is k by n if transA == rocblas_operation_conjugate_transpose
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill]
rocblas_fill_upper: C_i is an upper triangular matrix
rocblas_fill_lower: C_i is a lower triangular matrix
transA – [in] [rocblas_operation]
rocblas_operation_conjugate_transpose: op(A) = A^H
rocblas_operation_none: op(A) = A
n – [in] [rocblas_int] n specifies the number of rows and columns of C_i. n >= 0.
k – [in] [rocblas_int] k specifies the number of columns of op(A). k >= 0.
alpha – [in] alpha specifies the scalar alpha. When alpha is zero then A is not referenced and A need not be set before entry.
A – [in] device array of device pointers storing each matrix_i A of dimension (lda, k) when transA is rocblas_operation_none, otherwise of dimension (lda, n).
lda – [in] [rocblas_int] lda specifies the first dimension of A_i.
if transA = rocblas_operation_none, lda >= max( 1, n ), otherwise lda >= max( 1, k ).
beta – [in] beta specifies the scalar beta. When beta is zero then C need not be set before entry.
C – [in] device array of device pointers storing each matrix C_i on the GPU. The imaginary component of the diagonal elements are not used but are set to zero unless quick return. only the upper/lower triangular part of each C_i is accessed.
ldc – [in] [rocblas_int] ldc specifies the first dimension of C. ldc >= max( 1, n ).
batch_count – [in] [rocblas_int] number of instances in the batch.
-
rocblas_status rocblas_cherk_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_int n, rocblas_int k, const float *alpha, const rocblas_float_complex *A, rocblas_int lda, rocblas_stride stride_A, const float *beta, rocblas_float_complex *C, rocblas_int ldc, rocblas_stride stride_C, rocblas_int batch_count)#
-
rocblas_status rocblas_zherk_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation transA, rocblas_int n, rocblas_int k, const double *alpha, const rocblas_double_complex *A, rocblas_int lda, rocblas_stride stride_A, const double *beta, rocblas_double_complex *C, rocblas_int ldc, rocblas_stride stride_C, rocblas_int batch_count)#
BLAS Level 3 API
herk_strided_batched performs a batch of the matrix-matrix operations for a Hermitian rank-k update:
C_i := alpha*op( A_i )*op( A_i )^H + beta*C_i, where alpha and beta are scalars, op(A) is an n by k matrix, and C_i is a n x n Hermitian matrix stored as either upper or lower. op( A_i ) = A_i, and A_i is n by k if transA == rocblas_operation_none op( A_i ) = A_i^H and A_i is k by n if transA == rocblas_operation_conjugate_transpose
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill]
rocblas_fill_upper: C_i is an upper triangular matrix
rocblas_fill_lower: C_i is a lower triangular matrix
transA – [in] [rocblas_operation]
rocblas_operation_conjugate_transpose: op(A) = A^H
rocblas_operation_none: op(A) = A
n – [in] [rocblas_int] n specifies the number of rows and columns of C_i. n >= 0.
k – [in] [rocblas_int] k specifies the number of columns of op(A). k >= 0.
alpha – [in] alpha specifies the scalar alpha. When alpha is zero then A is not referenced and A need not be set before entry.
A – [in] Device pointer to the first matrix A_1 on the GPU of dimension (lda, k) when transA is rocblas_operation_none, otherwise of dimension (lda, n)
lda – [in] [rocblas_int] lda specifies the first dimension of A_i.
if transA = rocblas_operation_none, lda >= max( 1, n ), otherwise lda >= max( 1, k ).
stride_A – [in] [rocblas_stride] stride from the start of one matrix (A_i) and the next one (A_i+1).
beta – [in] beta specifies the scalar beta. When beta is zero then C need not be set before entry.
C – [in] Device pointer to the first matrix C_1 on the GPU. The imaginary component of the diagonal elements are not used but are set to zero unless quick return. only the upper/lower triangular part of each C_i is accessed.
ldc – [in] [rocblas_int] ldc specifies the first dimension of C. ldc >= max( 1, n ).
stride_C – [inout] [rocblas_stride] stride from the start of one matrix (C_i) and the next one (C_i+1).
batch_count – [in] [rocblas_int] number of instances in the batch.
rocblas_Xher2k + batched, strided_batched#
-
rocblas_status rocblas_cher2k(rocblas_handle handle, rocblas_fill uplo, rocblas_operation trans, rocblas_int n, rocblas_int k, const rocblas_float_complex *alpha, const rocblas_float_complex *A, rocblas_int lda, const rocblas_float_complex *B, rocblas_int ldb, const float *beta, rocblas_float_complex *C, rocblas_int ldc)#
-
rocblas_status rocblas_zher2k(rocblas_handle handle, rocblas_fill uplo, rocblas_operation trans, rocblas_int n, rocblas_int k, const rocblas_double_complex *alpha, const rocblas_double_complex *A, rocblas_int lda, const rocblas_double_complex *B, rocblas_int ldb, const double *beta, rocblas_double_complex *C, rocblas_int ldc)#
BLAS Level 3 API
her2k performs one of the matrix-matrix operations for a Hermitian rank-2k update:
C := alpha*op( A )*op( B )^H + conj(alpha)*op( B )*op( A )^H + beta*C, where alpha and beta are scalars, op(A) and op(B) are n by k matrices, and C is a n x n Hermitian matrix stored as either upper or lower. op( A ) = A, op( B ) = B, and A and B are n by k if trans == rocblas_operation_none op( A ) = A^H, op( B ) = B^H, and A and B are k by n if trans == rocblas_operation_conjugate_transpose
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill]
rocblas_fill_upper: C is an upper triangular matrix
rocblas_fill_lower: C is a lower triangular matrix
trans – [in] [rocblas_operation]
rocblas_operation_conjugate_transpose: op( A ) = A^H, op( B ) = B^H
rocblas_operation_none: op( A ) = A, op( B ) = B
n – [in] [rocblas_int] n specifies the number of rows and columns of C. n >= 0.
k – [in] [rocblas_int] k specifies the number of columns of op(A). k >= 0.
alpha – [in] alpha specifies the scalar alpha. When alpha is zero then A is not referenced and A need not be set before entry.
A – [in] pointer storing matrix A on the GPU. Matrix dimension is ( lda, k ) when if trans = rocblas_operation_none, otherwise (lda, n)
lda – [in] [rocblas_int] lda specifies the first dimension of A.
if trans = rocblas_operation_none, lda >= max( 1, n ), otherwise lda >= max( 1, k ).
B – [in] pointer storing matrix B on the GPU. Matrix dimension is ( ldb, k ) when if trans = rocblas_operation_none, otherwise (ldb, n)
ldb – [in] [rocblas_int] ldb specifies the first dimension of B.
if trans = rocblas_operation_none, ldb >= max( 1, n ), otherwise ldb >= max( 1, k ).
beta – [in] beta specifies the scalar beta. When beta is zero then C need not be set before entry.
C – [in] pointer storing matrix C on the GPU. The imaginary component of the diagonal elements are not used but are set to zero unless quick return. only the upper/lower triangular part is accessed.
ldc – [in] [rocblas_int] ldc specifies the first dimension of C. ldc >= max( 1, n ).
-
rocblas_status rocblas_cher2k_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation trans, rocblas_int n, rocblas_int k, const rocblas_float_complex *alpha, const rocblas_float_complex *const A[], rocblas_int lda, const rocblas_float_complex *const B[], rocblas_int ldb, const float *beta, rocblas_float_complex *const C[], rocblas_int ldc, rocblas_int batch_count)#
-
rocblas_status rocblas_zher2k_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation trans, rocblas_int n, rocblas_int k, const rocblas_double_complex *alpha, const rocblas_double_complex *const A[], rocblas_int lda, const rocblas_double_complex *const B[], rocblas_int ldb, const double *beta, rocblas_double_complex *const C[], rocblas_int ldc, rocblas_int batch_count)#
BLAS Level 3 API
her2k_batched performs a batch of the matrix-matrix operations for a Hermitian rank-2k update:
C_i := alpha*op( A_i )*op( B_i )^H + conj(alpha)*op( B_i )*op( A_i )^H + beta*C_i, where alpha and beta are scalars, op(A_i) and op(B_i) are n by k matrices, and C_i is a n x n Hermitian matrix stored as either upper or lower. op( A_i ) = A_i, op( B_i ) = B_i, and A_i and B_i are n by k if trans == rocblas_operation_none op( A_i ) = A_i^H, op( B_i ) = B_i^H, and A_i and B_i are k by n if trans == rocblas_operation_conjugate_transpose
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill]
rocblas_fill_upper: C_i is an upper triangular matrix
rocblas_fill_lower: C_i is a lower triangular matrix
trans – [in] [rocblas_operation]
rocblas_operation_conjugate_transpose: op(A) = A^H
rocblas_operation_none: op(A) = A
n – [in] [rocblas_int] n specifies the number of rows and columns of C_i. n >= 0.
k – [in] [rocblas_int] k specifies the number of columns of op(A). k >= 0.
alpha – [in] alpha specifies the scalar alpha. When alpha is zero then A is not referenced and A need not be set before entry.
A – [in] device array of device pointers storing each matrix_i A of dimension (lda, k) when trans is rocblas_operation_none, otherwise of dimension (lda, n).
lda – [in] [rocblas_int] lda specifies the first dimension of A_i.
if trans = rocblas_operation_none, lda >= max( 1, n ), otherwise lda >= max( 1, k ).
B – [in] device array of device pointers storing each matrix_i B of dimension (ldb, k) when trans is rocblas_operation_none, otherwise of dimension (ldb, n).
ldb – [in] [rocblas_int] ldb specifies the first dimension of B_i.
if trans = rocblas_operation_none, ldb >= max( 1, n ), otherwise ldb >= max( 1, k ).
beta – [in] beta specifies the scalar beta. When beta is zero then C need not be set before entry.
C – [in] device array of device pointers storing each matrix C_i on the GPU. The imaginary component of the diagonal elements are not used but are set to zero unless quick return. only the upper/lower triangular part of each C_i is accessed.
ldc – [in] [rocblas_int] ldc specifies the first dimension of C. ldc >= max( 1, n ).
batch_count – [in] [rocblas_int] number of instances in the batch.
-
rocblas_status rocblas_cher2k_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation trans, rocblas_int n, rocblas_int k, const rocblas_float_complex *alpha, const rocblas_float_complex *A, rocblas_int lda, rocblas_stride stride_A, const rocblas_float_complex *B, rocblas_int ldb, rocblas_stride stride_B, const float *beta, rocblas_float_complex *C, rocblas_int ldc, rocblas_stride stride_C, rocblas_int batch_count)#
-
rocblas_status rocblas_zher2k_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation trans, rocblas_int n, rocblas_int k, const rocblas_double_complex *alpha, const rocblas_double_complex *A, rocblas_int lda, rocblas_stride stride_A, const rocblas_double_complex *B, rocblas_int ldb, rocblas_stride stride_B, const double *beta, rocblas_double_complex *C, rocblas_int ldc, rocblas_stride stride_C, rocblas_int batch_count)#
BLAS Level 3 API
her2k_strided_batched performs a batch of the matrix-matrix operations for a Hermitian rank-2k update:
C_i := alpha*op( A_i )*op( B_i )^H + conj(alpha)*op( B_i )*op( A_i )^H + beta*C_i, where alpha and beta are scalars, op(A_i) and op(B_i) are n by k matrices, and C_i is a n x n Hermitian matrix stored as either upper or lower. op( A_i ) = A_i, op( B_i ) = B_i, and A_i and B_i are n by k if trans == rocblas_operation_none op( A_i ) = A_i^H, op( B_i ) = B_i^H, and A_i and B_i are k by n if trans == rocblas_operation_conjugate_transpose
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill]
rocblas_fill_upper: C_i is an upper triangular matrix
rocblas_fill_lower: C_i is a lower triangular matrix
trans – [in] [rocblas_operation]
rocblas_operation_conjugate_transpose: op( A_i ) = A_i^H, op( B_i ) = B_i^H
rocblas_operation_none: op( A_i ) = A_i, op( B_i ) = B_i
n – [in] [rocblas_int] n specifies the number of rows and columns of C_i. n >= 0.
k – [in] [rocblas_int] k specifies the number of columns of op(A). k >= 0.
alpha – [in] alpha specifies the scalar alpha. When alpha is zero then A is not referenced and A need not be set before entry.
A – [in] Device pointer to the first matrix A_1 on the GPU of dimension (lda, k) when trans is rocblas_operation_none, otherwise of dimension (lda, n).
lda – [in] [rocblas_int] lda specifies the first dimension of A_i.
if trans = rocblas_operation_none, lda >= max( 1, n ), otherwise lda >= max( 1, k ).
stride_A – [in] [rocblas_stride] stride from the start of one matrix (A_i) and the next one (A_i+1).
B – [in] Device pointer to the first matrix B_1 on the GPU of dimension (ldb, k) when trans is rocblas_operation_none, otherwise of dimension (ldb, n).
ldb – [in] [rocblas_int] ldb specifies the first dimension of B_i.
if trans = rocblas_operation_none, ldb >= max( 1, n ), otherwise ldb >= max( 1, k ).
stride_B – [in] [rocblas_stride] stride from the start of one matrix (B_i) and the next one (B_i+1).
beta – [in] beta specifies the scalar beta. When beta is zero then C need not be set before entry.
C – [in] Device pointer to the first matrix C_1 on the GPU. The imaginary component of the diagonal elements are not used but are set to zero unless quick return. only the upper/lower triangular part of each C_i is accessed.
ldc – [in] [rocblas_int] ldc specifies the first dimension of C. ldc >= max( 1, n ).
stride_C – [inout] [rocblas_stride] stride from the start of one matrix (C_i) and the next one (C_i+1).
batch_count – [in] [rocblas_int] number of instances in the batch.
rocblas_Xherkx + batched, strided_batched#
-
rocblas_status rocblas_cherkx(rocblas_handle handle, rocblas_fill uplo, rocblas_operation trans, rocblas_int n, rocblas_int k, const rocblas_float_complex *alpha, const rocblas_float_complex *A, rocblas_int lda, const rocblas_float_complex *B, rocblas_int ldb, const float *beta, rocblas_float_complex *C, rocblas_int ldc)#
-
rocblas_status rocblas_zherkx(rocblas_handle handle, rocblas_fill uplo, rocblas_operation trans, rocblas_int n, rocblas_int k, const rocblas_double_complex *alpha, const rocblas_double_complex *A, rocblas_int lda, const rocblas_double_complex *B, rocblas_int ldb, const double *beta, rocblas_double_complex *C, rocblas_int ldc)#
BLAS Level 3 API
herkx performs one of the matrix-matrix operations for a Hermitian rank-k update:
C := alpha*op( A )*op( B )^H + beta*C, where alpha and beta are scalars, op(A) and op(B) are n by k matrices, and C is a n x n Hermitian matrix stored as either upper or lower.
This routine should only be used when the caller can guarantee that the result of op( A )*op( B )^T will be Hermitian.
op( A ) = A, op( B ) = B, and A and B are n by k if trans == rocblas_operation_none op( A ) = A^H, op( B ) = B^H, and A and B are k by n if trans == rocblas_operation_conjugate_transpose
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill]
rocblas_fill_upper: C is an upper triangular matrix
rocblas_fill_lower: C is a lower triangular matrix
trans – [in] [rocblas_operation]
rocblas_operation_conjugate_transpose: op( A ) = A^H, op( B ) = B^H
rocblas_operation_none: op( A ) = A, op( B ) = B
n – [in] [rocblas_int] n specifies the number of rows and columns of C. n >= 0.
k – [in] [rocblas_int] k specifies the number of columns of op(A). k >= 0.
alpha – [in] alpha specifies the scalar alpha. When alpha is zero then A is not referenced and A need not be set before entry.
A – [in] pointer storing matrix A on the GPU. Matrix dimension is ( lda, k ) when if trans = rocblas_operation_none, otherwise (lda, n)
lda – [in] [rocblas_int] lda specifies the first dimension of A.
if trans = rocblas_operation_none, lda >= max( 1, n ), otherwise lda >= max( 1, k ).
B – [in] pointer storing matrix B on the GPU. Matrix dimension is ( ldb, k ) when if trans = rocblas_operation_none, otherwise (ldb, n)
ldb – [in] [rocblas_int] ldb specifies the first dimension of B.
if trans = rocblas_operation_none, ldb >= max( 1, n ), otherwise ldb >= max( 1, k ).
beta – [in] beta specifies the scalar beta. When beta is zero then C need not be set before entry.
C – [in] pointer storing matrix C on the GPU. The imaginary component of the diagonal elements are not used but are set to zero unless quick return. only the upper/lower triangular part is accessed.
ldc – [in] [rocblas_int] ldc specifies the first dimension of C. ldc >= max( 1, n ).
-
rocblas_status rocblas_cherkx_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation trans, rocblas_int n, rocblas_int k, const rocblas_float_complex *alpha, const rocblas_float_complex *const A[], rocblas_int lda, const rocblas_float_complex *const B[], rocblas_int ldb, const float *beta, rocblas_float_complex *const C[], rocblas_int ldc, rocblas_int batch_count)#
-
rocblas_status rocblas_zherkx_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation trans, rocblas_int n, rocblas_int k, const rocblas_double_complex *alpha, const rocblas_double_complex *const A[], rocblas_int lda, const rocblas_double_complex *const B[], rocblas_int ldb, const double *beta, rocblas_double_complex *const C[], rocblas_int ldc, rocblas_int batch_count)#
BLAS Level 3 API
herkx_batched performs a batch of the matrix-matrix operations for a Hermitian rank-k update:
C_i := alpha*op( A_i )*op( B_i )^H + beta*C_i, where alpha and beta are scalars, op(A_i) and op(B_i) are n by k matrices, and C_i is a n x n Hermitian matrix stored as either upper or lower.
This routine should only be used when the caller can guarantee that the result of op( A )*op( B )^T will be Hermitian.
op( A_i ) = A_i, op( B_i ) = B_i, and A_i and B_i are n by k if trans == rocblas_operation_none op( A_i ) = A_i^H, op( B_i ) = B_i^H, and A_i and B_i are k by n if trans == rocblas_operation_conjugate_transpose
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill]
rocblas_fill_upper: C_i is an upper triangular matrix
rocblas_fill_lower: C_i is a lower triangular matrix
trans – [in] [rocblas_operation]
rocblas_operation_conjugate_transpose: op(A) = A^H
rocblas_operation_none: op(A) = A
n – [in] [rocblas_int] n specifies the number of rows and columns of C_i. n >= 0.
k – [in] [rocblas_int] k specifies the number of columns of op(A). k >= 0.
alpha – [in] alpha specifies the scalar alpha. When alpha is zero then A is not referenced and A need not be set before entry.
A – [in] device array of device pointers storing each matrix_i A of dimension (lda, k) when trans is rocblas_operation_none, otherwise of dimension (lda, n)
lda – [in] [rocblas_int] lda specifies the first dimension of A_i.
if trans = rocblas_operation_none, lda >= max( 1, n ), otherwise lda >= max( 1, k ).
B – [in] device array of device pointers storing each matrix_i B of dimension (ldb, k) when trans is rocblas_operation_none, otherwise of dimension (ldb, n)
ldb – [in] [rocblas_int] ldb specifies the first dimension of B_i.
if trans = rocblas_operation_none, ldb >= max( 1, n ), otherwise ldb >= max( 1, k ).
beta – [in] beta specifies the scalar beta. When beta is zero then C need not be set before entry.
C – [in] device array of device pointers storing each matrix C_i on the GPU. The imaginary component of the diagonal elements are not used but are set to zero unless quick return. only the upper/lower triangular part of each C_i is accessed.
ldc – [in] [rocblas_int] ldc specifies the first dimension of C. ldc >= max( 1, n ).
batch_count – [in] [rocblas_int] number of instances in the batch.
-
rocblas_status rocblas_cherkx_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation trans, rocblas_int n, rocblas_int k, const rocblas_float_complex *alpha, const rocblas_float_complex *A, rocblas_int lda, rocblas_stride stride_A, const rocblas_float_complex *B, rocblas_int ldb, rocblas_stride stride_B, const float *beta, rocblas_float_complex *C, rocblas_int ldc, rocblas_stride stride_C, rocblas_int batch_count)#
-
rocblas_status rocblas_zherkx_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_operation trans, rocblas_int n, rocblas_int k, const rocblas_double_complex *alpha, const rocblas_double_complex *A, rocblas_int lda, rocblas_stride stride_A, const rocblas_double_complex *B, rocblas_int ldb, rocblas_stride stride_B, const double *beta, rocblas_double_complex *C, rocblas_int ldc, rocblas_stride stride_C, rocblas_int batch_count)#
BLAS Level 3 API
herkx_strided_batched performs a batch of the matrix-matrix operations for a Hermitian rank-k update:
C_i := alpha*op( A_i )*op( B_i )^H + beta*C_i, where alpha and beta are scalars, op(A_i) and op(B_i) are n by k matrices, and C_i is a n x n Hermitian matrix stored as either upper or lower.
This routine should only be used when the caller can guarantee that the result of op( A )*op( B )^T will be Hermitian.
op( A_i ) = A_i, op( B_i ) = B_i, and A_i and B_i are n by k if trans == rocblas_operation_none op( A_i ) = A_i^H, op( B_i ) = B_i^H, and A_i and B_i are k by n if trans == rocblas_operation_conjugate_transpose
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill]
rocblas_fill_upper: C_i is an upper triangular matrix
rocblas_fill_lower: C_i is a lower triangular matrix
trans – [in] [rocblas_operation]
rocblas_operation_conjugate_transpose: op( A_i ) = A_i^H, op( B_i ) = B_i^H
rocblas_operation_none: op( A_i ) = A_i, op( B_i ) = B_i
n – [in] [rocblas_int] n specifies the number of rows and columns of C_i. n >= 0.
k – [in] [rocblas_int] k specifies the number of columns of op(A). k >= 0.
alpha – [in] alpha specifies the scalar alpha. When alpha is zero then A is not referenced and A need not be set before entry.
A – [in] Device pointer to the first matrix A_1 on the GPU of dimension (lda, k) when trans is rocblas_operation_none, otherwise of dimension (lda, n).
lda – [in] [rocblas_int] lda specifies the first dimension of A_i.
if trans = rocblas_operation_none, lda >= max( 1, n ), otherwise lda >= max( 1, k ).
stride_A – [in] [rocblas_stride] stride from the start of one matrix (A_i) and the next one (A_i+1)
B – [in] Device pointer to the first matrix B_1 on the GPU of dimension (ldb, k) when trans is rocblas_operation_none, otherwise of dimension (ldb, n).
ldb – [in] [rocblas_int] ldb specifies the first dimension of B_i.
if trans = rocblas_operation_none, ldb >= max( 1, n ), otherwise ldb >= max( 1, k ).
stride_B – [in] [rocblas_stride] stride from the start of one matrix (B_i) and the next one (B_i+1)
beta – [in] beta specifies the scalar beta. When beta is zero then C need not be set before entry.
C – [in] Device pointer to the first matrix C_1 on the GPU. The imaginary component of the diagonal elements are not used but are set to zero unless quick return. only the upper/lower triangular part of each C_i is accessed.
ldc – [in] [rocblas_int] ldc specifies the first dimension of C. ldc >= max( 1, n ).
stride_C – [inout] [rocblas_stride] stride from the start of one matrix (C_i) and the next one (C_i+1).
batch_count – [in] [rocblas_int] number of instances in the batch.
rocblas_Xtrtri + batched, strided_batched#
-
rocblas_status rocblas_strtri(rocblas_handle handle, rocblas_fill uplo, rocblas_diagonal diag, rocblas_int n, const float *A, rocblas_int lda, float *invA, rocblas_int ldinvA)#
-
rocblas_status rocblas_dtrtri(rocblas_handle handle, rocblas_fill uplo, rocblas_diagonal diag, rocblas_int n, const double *A, rocblas_int lda, double *invA, rocblas_int ldinvA)#
BLAS Level 3 API
trtri compute the inverse of a matrix A, namely, invA and write the result into invA;
if rocblas_fill_upper, the lower part of A is not referenced if rocblas_fill_lower, the upper part of A is not referenced
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill] specifies whether the upper ‘rocblas_fill_upper’ or lower ‘rocblas_fill_lower’
diag – [in] [rocblas_diagonal]
’rocblas_diagonal_non_unit’, A is non-unit triangular;
’rocblas_diagonal_unit’, A is unit triangular;
n – [in] [rocblas_int] size of matrix A and invA.
A – [in] device pointer storing matrix A.
lda – [in] [rocblas_int] specifies the leading dimension of A.
invA – [out] device pointer storing matrix invA. Partial inplace operation is supported. See below: -If UPLO = ‘U’, the leading N-by-N upper triangular part of the invA will store the inverse of the upper triangular matrix, and the strictly lower triangular part of invA may be cleared.
If UPLO = ‘L’, the leading N-by-N lower triangular part of the invA will store the inverse of the lower triangular matrix, and the strictly upper triangular part of invA may be cleared.
ldinvA – [in] [rocblas_int] specifies the leading dimension of invA.
-
rocblas_status rocblas_strtri_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_diagonal diag, rocblas_int n, const float *const A[], rocblas_int lda, float *const invA[], rocblas_int ldinvA, rocblas_int batch_count)#
-
rocblas_status rocblas_dtrtri_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_diagonal diag, rocblas_int n, const double *const A[], rocblas_int lda, double *const invA[], rocblas_int ldinvA, rocblas_int batch_count)#
BLAS Level 3 API
trtri_batched compute the inverse of A_i and write into invA_i where A_i and invA_i are the i-th matrices in the batch, for i = 1, …, batch_count.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill] specifies whether the upper ‘rocblas_fill_upper’ or lower ‘rocblas_fill_lower’
diag – [in] [rocblas_diagonal]
’rocblas_diagonal_non_unit’, A is non-unit triangular;
’rocblas_diagonal_unit’, A is unit triangular;
n – [in] [rocblas_int]
A – [in] device array of device pointers storing each matrix A_i.
lda – [in] [rocblas_int] specifies the leading dimension of each A_i.
invA – [out] device array of device pointers storing the inverse of each matrix A_i. Partial inplace operation is supported. See below: -If UPLO = ‘U’, the leading N-by-N upper triangular part of the invA will store the inverse of the upper triangular matrix, and the strictly lower triangular part of invA may be cleared.
If UPLO = ‘L’, the leading N-by-N lower triangular part of the invA will store the inverse of the lower triangular matrix, and the strictly upper triangular part of invA may be cleared.
ldinvA – [in] [rocblas_int] specifies the leading dimension of each invA_i.
batch_count – [in] [rocblas_int] numbers of matrices in the batch.
-
rocblas_status rocblas_strtri_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_diagonal diag, rocblas_int n, const float *A, rocblas_int lda, rocblas_stride stride_a, float *invA, rocblas_int ldinvA, rocblas_stride stride_invA, rocblas_int batch_count)#
-
rocblas_status rocblas_dtrtri_strided_batched(rocblas_handle handle, rocblas_fill uplo, rocblas_diagonal diag, rocblas_int n, const double *A, rocblas_int lda, rocblas_stride stride_a, double *invA, rocblas_int ldinvA, rocblas_stride stride_invA, rocblas_int batch_count)#
BLAS Level 3 API
trtri_strided_batched compute the inverse of A_i and write into invA_i where A_i and invA_i are the i-th matrices in the batch, for i = 1, …, batch_count.
If UPLO = ‘U’, the leading N-by-N upper triangular part of the invA will store the inverse of the upper triangular matrix, and the strictly lower triangular part of invA may be cleared.
If UPLO = ‘L’, the leading N-by-N lower triangular part of the invA will store the inverse of the lower triangular matrix, and the strictly upper triangular part of invA may be cleared.
- Parameters:
ldinvA – [in] [rocblas_int] specifies the leading dimension of each invA_i.
stride_invA – [in] [rocblas_stride] “batch stride invA”: stride from the start of one invA_i matrix to the next invA_(i + 1).
batch_count – [in] [rocblas_int] numbers of matrices in the batch.
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
uplo – [in] [rocblas_fill] specifies whether the upper ‘rocblas_fill_upper’ or lower ‘rocblas_fill_lower’
diag – [in] [rocblas_diagonal]
’rocblas_diagonal_non_unit’, A is non-unit triangular;
’rocblas_diagonal_unit’, A is unit triangular;
n – [in] [rocblas_int]
A – [in] device pointer pointing to address of first matrix A_1.
lda – [in] [rocblas_int] specifies the leading dimension of each A.
stride_a – [in] [rocblas_stride] “batch stride a”: stride from the start of one A_i matrix to the next A_(i + 1).
invA – [out] device pointer storing the inverses of each matrix A_i. Partial inplace operation is supported. See below:
rocBLAS Extension#
rocblas_axpy_ex + batched, strided_batched#
-
rocblas_status rocblas_axpy_ex(rocblas_handle handle, rocblas_int n, const void *alpha, rocblas_datatype alpha_type, const void *x, rocblas_datatype x_type, rocblas_int incx, void *y, rocblas_datatype y_type, rocblas_int incy, rocblas_datatype execution_type)#
BLAS EX API
axpy_ex computes constant alpha multiplied by vector x, plus vector y.
y := alpha * x + y
Currently supported datatypes are as follows:
alpha_type
x_type
y_type
execution_type
bf16_r
bf16_r
bf16_r
f32_r
f32_r
bf16_r
bf16_r
f32_r
f16_r
f16_r
f16_r
f16_r
f16_r
f16_r
f16_r
f32_r
f32_r
f16_r
f16_r
f32_r
f32_r
f32_r
f32_r
f32_r
f64_r
f64_r
f64_r
f64_r
f32_c
f32_c
f32_c
f32_c
f64_c
f64_c
f64_c
f64_c
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] the number of elements in x and y.
alpha – [in] device pointer or host pointer to specify the scalar alpha.
alpha_type – [in] [rocblas_datatype] specifies the datatype of alpha.
x – [in] device pointer storing vector x.
x_type – [in] [rocblas_datatype] specifies the datatype of vector x.
incx – [in] [rocblas_int] specifies the increment for the elements of x.
y – [inout] device pointer storing vector y.
y_type – [in] [rocblas_datatype] specifies the datatype of vector y.
incy – [in] [rocblas_int] specifies the increment for the elements of y.
execution_type – [in] [rocblas_datatype] specifies the datatype of computation.
-
rocblas_status rocblas_axpy_batched_ex(rocblas_handle handle, rocblas_int n, const void *alpha, rocblas_datatype alpha_type, const void *x, rocblas_datatype x_type, rocblas_int incx, void *y, rocblas_datatype y_type, rocblas_int incy, rocblas_int batch_count, rocblas_datatype execution_type)#
BLAS EX API
axpy_batched_ex computes constant alpha multiplied by vector x, plus vector y over a set of batched vectors.
y := alpha * x + y
Currently supported datatypes are as follows:
alpha_type
x_type
y_type
execution_type
bf16_r
bf16_r
bf16_r
f32_r
f32_r
bf16_r
bf16_r
f32_r
f16_r
f16_r
f16_r
f16_r
f16_r
f16_r
f16_r
f32_r
f32_r
f16_r
f16_r
f32_r
f32_r
f32_r
f32_r
f32_r
f64_r
f64_r
f64_r
f64_r
f32_c
f32_c
f32_c
f32_c
f64_c
f64_c
f64_c
f64_c
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] the number of elements in each x_i and y_i.
alpha – [in] device pointer or host pointer to specify the scalar alpha.
alpha_type – [in] [rocblas_datatype] specifies the datatype of alpha.
x – [in] device array of device pointers storing each vector x_i.
x_type – [in] [rocblas_datatype] specifies the datatype of each vector x_i.
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i.
y – [inout] device array of device pointers storing each vector y_i.
y_type – [in] [rocblas_datatype] specifies the datatype of each vector y_i.
incy – [in] [rocblas_int] specifies the increment for the elements of each y_i.
batch_count – [in] [rocblas_int] number of instances in the batch.
execution_type – [in] [rocblas_datatype] specifies the datatype of computation.
-
rocblas_status rocblas_axpy_strided_batched_ex(rocblas_handle handle, rocblas_int n, const void *alpha, rocblas_datatype alpha_type, const void *x, rocblas_datatype x_type, rocblas_int incx, rocblas_stride stridex, void *y, rocblas_datatype y_type, rocblas_int incy, rocblas_stride stridey, rocblas_int batch_count, rocblas_datatype execution_type)#
BLAS EX API
axpy_strided_batched_ex computes constant alpha multiplied by vector x, plus vector y over a set of strided batched vectors.
y := alpha * x + y
Currently supported datatypes are as follows:
alpha_type
x_type
y_type
execution_type
bf16_r
bf16_r
bf16_r
f32_r
f32_r
bf16_r
bf16_r
f32_r
f16_r
f16_r
f16_r
f16_r
f16_r
f16_r
f16_r
f32_r
f32_r
f16_r
f16_r
f32_r
f32_r
f32_r
f32_r
f32_r
f64_r
f64_r
f64_r
f64_r
f32_c
f32_c
f32_c
f32_c
f64_c
f64_c
f64_c
f64_c
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] the number of elements in each x_i and y_i.
alpha – [in] device pointer or host pointer to specify the scalar alpha.
alpha_type – [in] [rocblas_datatype] specifies the datatype of alpha.
x – [in] device pointer to the first vector x_1.
x_type – [in] [rocblas_datatype] specifies the datatype of each vector x_i.
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i.
stridex – [in] [rocblas_stride] stride from the start of one vector (x_i) to the next one (x_i+1). There are no restrictions placed on stridex. However, ensure that stridex is of appropriate size. For a typical case this means stridex >= n * incx.
y – [inout] device pointer to the first vector y_1.
y_type – [in] [rocblas_datatype] specifies the datatype of each vector y_i.
incy – [in] [rocblas_int] specifies the increment for the elements of each y_i.
stridey – [in] [rocblas_stride] stride from the start of one vector (y_i) to the next one (y_i+1). There are no restrictions placed on stridey. However, ensure that stridey is of appropriate size. For a typical case this means stridey >= n * incy.
batch_count – [in] [rocblas_int] number of instances in the batch.
execution_type – [in] [rocblas_datatype] specifies the datatype of computation.
rocblas_dot_ex + batched, strided_batched#
-
rocblas_status rocblas_dot_ex(rocblas_handle handle, rocblas_int n, const void *x, rocblas_datatype x_type, rocblas_int incx, const void *y, rocblas_datatype y_type, rocblas_int incy, void *result, rocblas_datatype result_type, rocblas_datatype execution_type)#
BLAS EX API
dot_ex performs the dot product of vectors x and y.
result = x * y;
dotc_ex performs the dot product of the conjugate of complex vector x and complex vector y
result = conjugate (x) * y;
Currently supported datatypes are as follows:
x_type
y_type
result_type
execution_type
f16_r
f16_r
f16_r
f16_r
f16_r
f16_r
f16_r
f32_r
bf16_r
bf16_r
bf16_r
f32_r
f32_r
f32_r
f32_r
f32_r
f64_r
f64_r
f64_r
f64_r
f32_c
f32_c
f32_c
f32_c
f64_c
f64_c
f64_c
f64_c
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] the number of elements in x and y.
x – [in] device pointer storing vector x.
x_type – [in] [rocblas_datatype] specifies the datatype of vector x.
incx – [in] [rocblas_int] specifies the increment for the elements of y.
y – [in] device pointer storing vector y.
y_type – [in] [rocblas_datatype] specifies the datatype of vector y.
incy – [in] [rocblas_int] specifies the increment for the elements of y.
result – [inout] device pointer or host pointer to store the dot product. return is 0.0 if n <= 0.
result_type – [in] [rocblas_datatype] specifies the datatype of the result.
execution_type – [in] [rocblas_datatype] specifies the datatype of computation.
-
rocblas_status rocblas_dot_batched_ex(rocblas_handle handle, rocblas_int n, const void *x, rocblas_datatype x_type, rocblas_int incx, const void *y, rocblas_datatype y_type, rocblas_int incy, rocblas_int batch_count, void *result, rocblas_datatype result_type, rocblas_datatype execution_type)#
BLAS EX API
dot_batched_ex performs a batch of dot products of vectors x and y.
result_i = x_i * y_i;
dotc_batched_ex performs a batch of dot products of the conjugate of complex vector x and complex vector y
result_i = conjugate (x_i) * y_i;
where (x_i, y_i) is the i-th instance of the batch. x_i and y_i are vectors, for i = 1, …, batch_count
Currently supported datatypes are as follows:
x_type
y_type
result_type
execution_type
f16_r
f16_r
f16_r
f16_r
f16_r
f16_r
f16_r
f32_r
bf16_r
bf16_r
bf16_r
f32_r
f32_r
f32_r
f32_r
f32_r
f64_r
f64_r
f64_r
f64_r
f32_c
f32_c
f32_c
f32_c
f64_c
f64_c
f64_c
f64_c
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] the number of elements in each x_i and y_i.
x – [in] device array of device pointers storing each vector x_i.
x_type – [in] [rocblas_datatype] specifies the datatype of each vector x_i.
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i.
y – [in] device array of device pointers storing each vector y_i.
y_type – [in] [rocblas_datatype] specifies the datatype of each vector y_i.
incy – [in] [rocblas_int] specifies the increment for the elements of each y_i.
batch_count – [in] [rocblas_int] number of instances in the batch.
result – [inout] device array or host array of batch_count size to store the dot products of each batch. return 0.0 for each element if n <= 0.
result_type – [in] [rocblas_datatype] specifies the datatype of the result.
execution_type – [in] [rocblas_datatype] specifies the datatype of computation.
-
rocblas_status rocblas_dot_strided_batched_ex(rocblas_handle handle, rocblas_int n, const void *x, rocblas_datatype x_type, rocblas_int incx, rocblas_stride stride_x, const void *y, rocblas_datatype y_type, rocblas_int incy, rocblas_stride stride_y, rocblas_int batch_count, void *result, rocblas_datatype result_type, rocblas_datatype execution_type)#
BLAS EX API
dot_strided_batched_ex performs a batch of dot products of vectors x and y.
result_i = x_i * y_i;
dotc_strided_batched_ex performs a batch of dot products of the conjugate of complex vector x and complex vector y
result_i = conjugate (x_i) * y_i;
where (x_i, y_i) is the i-th instance of the batch. x_i and y_i are vectors, for i = 1, …, batch_count
Currently supported datatypes are as follows:
x_type
y_type
result_type
execution_type
f16_r
f16_r
f16_r
f16_r
f16_r
f16_r
f16_r
f32_r
bf16_r
bf16_r
bf16_r
f32_r
f32_r
f32_r
f32_r
f32_r
f64_r
f64_r
f64_r
f64_r
f32_c
f32_c
f32_c
f32_c
f64_c
f64_c
f64_c
f64_c
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] the number of elements in each x_i and y_i.
x – [in] device pointer to the first vector (x_1) in the batch.
x_type – [in] [rocblas_datatype] specifies the datatype of each vector x_i.
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i.
stride_x – [in] [rocblas_stride] stride from the start of one vector (x_i) and the next one (x_i+1)
y – [in] device pointer to the first vector (y_1) in the batch.
y_type – [in] [rocblas_datatype] specifies the datatype of each vector y_i.
incy – [in] [rocblas_int] specifies the increment for the elements of each y_i.
stride_y – [in] [rocblas_stride] stride from the start of one vector (y_i) and the next one (y_i+1)
batch_count – [in] [rocblas_int] number of instances in the batch.
result – [inout] device array or host array of batch_count size to store the dot products of each batch. return 0.0 for each element if n <= 0.
result_type – [in] [rocblas_datatype] specifies the datatype of the result.
execution_type – [in] [rocblas_datatype] specifies the datatype of computation.
rocblas_dotc_ex + batched, strided_batched#
-
rocblas_status rocblas_dotc_ex(rocblas_handle handle, rocblas_int n, const void *x, rocblas_datatype x_type, rocblas_int incx, const void *y, rocblas_datatype y_type, rocblas_int incy, void *result, rocblas_datatype result_type, rocblas_datatype execution_type)#
BLAS EX API
dot_ex performs the dot product of vectors x and y.
result = x * y;
dotc_ex performs the dot product of the conjugate of complex vector x and complex vector y
result = conjugate (x) * y;
Currently supported datatypes are as follows:
x_type
y_type
result_type
execution_type
f16_r
f16_r
f16_r
f16_r
f16_r
f16_r
f16_r
f32_r
bf16_r
bf16_r
bf16_r
f32_r
f32_r
f32_r
f32_r
f32_r
f64_r
f64_r
f64_r
f64_r
f32_c
f32_c
f32_c
f32_c
f64_c
f64_c
f64_c
f64_c
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] the number of elements in x and y.
x – [in] device pointer storing vector x.
x_type – [in] [rocblas_datatype] specifies the datatype of vector x.
incx – [in] [rocblas_int] specifies the increment for the elements of y.
y – [in] device pointer storing vector y.
y_type – [in] [rocblas_datatype] specifies the datatype of vector y.
incy – [in] [rocblas_int] specifies the increment for the elements of y.
result – [inout] device pointer or host pointer to store the dot product. return is 0.0 if n <= 0.
result_type – [in] [rocblas_datatype] specifies the datatype of the result.
execution_type – [in] [rocblas_datatype] specifies the datatype of computation.
-
rocblas_status rocblas_dotc_batched_ex(rocblas_handle handle, rocblas_int n, const void *x, rocblas_datatype x_type, rocblas_int incx, const void *y, rocblas_datatype y_type, rocblas_int incy, rocblas_int batch_count, void *result, rocblas_datatype result_type, rocblas_datatype execution_type)#
BLAS EX API
dot_batched_ex performs a batch of dot products of vectors x and y.
result_i = x_i * y_i;
dotc_batched_ex performs a batch of dot products of the conjugate of complex vector x and complex vector y
result_i = conjugate (x_i) * y_i;
where (x_i, y_i) is the i-th instance of the batch. x_i and y_i are vectors, for i = 1, …, batch_count
Currently supported datatypes are as follows:
x_type
y_type
result_type
execution_type
f16_r
f16_r
f16_r
f16_r
f16_r
f16_r
f16_r
f32_r
bf16_r
bf16_r
bf16_r
f32_r
f32_r
f32_r
f32_r
f32_r
f64_r
f64_r
f64_r
f64_r
f32_c
f32_c
f32_c
f32_c
f64_c
f64_c
f64_c
f64_c
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] the number of elements in each x_i and y_i.
x – [in] device array of device pointers storing each vector x_i.
x_type – [in] [rocblas_datatype] specifies the datatype of each vector x_i.
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i.
y – [in] device array of device pointers storing each vector y_i.
y_type – [in] [rocblas_datatype] specifies the datatype of each vector y_i.
incy – [in] [rocblas_int] specifies the increment for the elements of each y_i.
batch_count – [in] [rocblas_int] number of instances in the batch.
result – [inout] device array or host array of batch_count size to store the dot products of each batch. return 0.0 for each element if n <= 0.
result_type – [in] [rocblas_datatype] specifies the datatype of the result.
execution_type – [in] [rocblas_datatype] specifies the datatype of computation.
-
rocblas_status rocblas_dotc_strided_batched_ex(rocblas_handle handle, rocblas_int n, const void *x, rocblas_datatype x_type, rocblas_int incx, rocblas_stride stride_x, const void *y, rocblas_datatype y_type, rocblas_int incy, rocblas_stride stride_y, rocblas_int batch_count, void *result, rocblas_datatype result_type, rocblas_datatype execution_type)#
BLAS EX API
dot_strided_batched_ex performs a batch of dot products of vectors x and y.
result_i = x_i * y_i;
dotc_strided_batched_ex performs a batch of dot products of the conjugate of complex vector x and complex vector y
result_i = conjugate (x_i) * y_i;
where (x_i, y_i) is the i-th instance of the batch. x_i and y_i are vectors, for i = 1, …, batch_count
Currently supported datatypes are as follows:
x_type
y_type
result_type
execution_type
f16_r
f16_r
f16_r
f16_r
f16_r
f16_r
f16_r
f32_r
bf16_r
bf16_r
bf16_r
f32_r
f32_r
f32_r
f32_r
f32_r
f64_r
f64_r
f64_r
f64_r
f32_c
f32_c
f32_c
f32_c
f64_c
f64_c
f64_c
f64_c
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] the number of elements in each x_i and y_i.
x – [in] device pointer to the first vector (x_1) in the batch.
x_type – [in] [rocblas_datatype] specifies the datatype of each vector x_i.
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i.
stride_x – [in] [rocblas_stride] stride from the start of one vector (x_i) and the next one (x_i+1)
y – [in] device pointer to the first vector (y_1) in the batch.
y_type – [in] [rocblas_datatype] specifies the datatype of each vector y_i.
incy – [in] [rocblas_int] specifies the increment for the elements of each y_i.
stride_y – [in] [rocblas_stride] stride from the start of one vector (y_i) and the next one (y_i+1)
batch_count – [in] [rocblas_int] number of instances in the batch.
result – [inout] device array or host array of batch_count size to store the dot products of each batch. return 0.0 for each element if n <= 0.
result_type – [in] [rocblas_datatype] specifies the datatype of the result.
execution_type – [in] [rocblas_datatype] specifies the datatype of computation.
rocblas_nrm2_ex + batched, strided_batched#
-
rocblas_status rocblas_nrm2_ex(rocblas_handle handle, rocblas_int n, const void *x, rocblas_datatype x_type, rocblas_int incx, void *results, rocblas_datatype result_type, rocblas_datatype execution_type)#
BLAS_EX API.
nrm2_ex computes the euclidean norm of a real or complex vector.
result := sqrt( x'*x ) for real vectors result := sqrt( x**H*x ) for complex vectors
Currently supported datatypes are as follows:
x_type
result
execution_type
bf16_r
bf16_r
f32_r
f16_r
f16_r
f32_r
f32_r
f32_r
f32_r
f64_r
f64_r
f64_r
f32_c
f32_r
f32_r
f64_c
f64_r
f64_r
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] the number of elements in x.
x – [in] device pointer storing vector x.
x_type – [in] [rocblas_datatype] specifies the datatype of the vector x.
incx – [in] [rocblas_int] specifies the increment for the elements of y.
results – [inout] device pointer or host pointer to store the nrm2 product. return is 0.0 if n, incx<=0.
result_type – [in] [rocblas_datatype] specifies the datatype of the result.
execution_type – [in] [rocblas_datatype] specifies the datatype of computation.
-
rocblas_status rocblas_nrm2_batched_ex(rocblas_handle handle, rocblas_int n, const void *x, rocblas_datatype x_type, rocblas_int incx, rocblas_int batch_count, void *results, rocblas_datatype result_type, rocblas_datatype execution_type)#
BLAS_EX API.
nrm2_batched_ex computes the euclidean norm over a batch of real or complex vectors.
result := sqrt( x_i'*x_i ) for real vectors x, for i = 1, ..., batch_count result := sqrt( x_i**H*x_i ) for complex vectors x, for i = 1, ..., batch_count
Currently supported datatypes are as follows:
x_type
result
execution_type
bf16_r
bf16_r
f32_r
f16_r
f16_r
f32_r
f32_r
f32_r
f32_r
f64_r
f64_r
f64_r
f32_c
f32_r
f32_r
f64_c
f64_r
f64_r
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] number of elements in each x_i.
x – [in] device array of device pointers storing each vector x_i.
x_type – [in] [rocblas_datatype] specifies the datatype of each vector x_i.
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i. incx must be > 0.
batch_count – [in] [rocblas_int] number of instances in the batch.
results – [out] device pointer or host pointer to array of batch_count size for nrm2 results. return is 0.0 for each element if n <= 0, incx<=0.
result_type – [in] [rocblas_datatype] specifies the datatype of the result.
execution_type – [in] [rocblas_datatype] specifies the datatype of computation.
-
rocblas_status rocblas_nrm2_strided_batched_ex(rocblas_handle handle, rocblas_int n, const void *x, rocblas_datatype x_type, rocblas_int incx, rocblas_stride stride_x, rocblas_int batch_count, void *results, rocblas_datatype result_type, rocblas_datatype execution_type)#
BLAS_EX API.
nrm2_strided_batched_ex computes the euclidean norm over a batch of real or complex vectors.
result := sqrt( x_i'*x_i ) for real vectors x, for i = 1, ..., batch_count result := sqrt( x_i**H*x_i ) for complex vectors, for i = 1, ..., batch_count
Currently supported datatypes are as follows:
x_type
result
execution_type
bf16_r
bf16_r
f32_r
f16_r
f16_r
f32_r
f32_r
f32_r
f32_r
f64_r
f64_r
f64_r
f32_c
f32_r
f32_r
f64_c
f64_r
f64_r
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] number of elements in each x_i.
x – [in] device pointer to the first vector x_1.
x_type – [in] [rocblas_datatype] specifies the datatype of each vector x_i.
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i. incx must be > 0.
stride_x – [in] [rocblas_stride] stride from the start of one vector (x_i) and the next one (x_i+1). There are no restrictions placed on stride_x. However, ensure that stride_x is of appropriate size. For a typical case this means stride_x >= n * incx.
batch_count – [in] [rocblas_int] number of instances in the batch.
results – [out] device pointer or host pointer to array for storing contiguous batch_count results. return is 0.0 for each element if n <= 0, incx<=0.
result_type – [in] [rocblas_datatype] specifies the datatype of the result.
execution_type – [in] [rocblas_datatype] specifies the datatype of computation.
rocblas_rot_ex + batched, strided_batched#
-
rocblas_status rocblas_rot_ex(rocblas_handle handle, rocblas_int n, void *x, rocblas_datatype x_type, rocblas_int incx, void *y, rocblas_datatype y_type, rocblas_int incy, const void *c, const void *s, rocblas_datatype cs_type, rocblas_datatype execution_type)#
BLAS EX API
rot_ex applies the Givens rotation matrix defined by c=cos(alpha) and s=sin(alpha) to vectors x and y. Scalars c and s may be stored in either host or device memory. Location is specified by calling rocblas_set_pointer_mode.
In the case where cs_type is real:
x := c * x + s * y y := c * y - s * x
In the case where cs_type is complex, the imaginary part of c is ignored:
x := real(c) * x + s * y y := real(c) * y - conj(s) * x
Currently supported datatypes are as follows:
x_type
y_type
cs_type
execution_type
bf16_r
bf16_r
bf16_r
f32_r
f16_r
f16_r
f16_r
f32_r
f32_r
f32_r
f32_r
f32_r
f64_r
f64_r
f64_r
f64_r
f32_c
f32_c
f32_c
f32_c
f32_c
f32_c
f32_r
f32_c
f64_c
f64_c
f64_c
f64_c
f64_c
f64_c
f64_r
f64_c
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] number of elements in the x and y vectors.
x – [inout] device pointer storing vector x.
x_type – [in] [rocblas_datatype] specifies the datatype of vector x.
incx – [in] [rocblas_int] specifies the increment between elements of x.
y – [inout] device pointer storing vector y.
y_type – [in] [rocblas_datatype] specifies the datatype of vector y.
incy – [in] [rocblas_int] specifies the increment between elements of y.
c – [in] device pointer or host pointer storing scalar cosine component of the rotation matrix.
s – [in] device pointer or host pointer storing scalar sine component of the rotation matrix.
cs_type – [in] [rocblas_datatype] specifies the datatype of c and s.
execution_type – [in] [rocblas_datatype] specifies the datatype of computation.
-
rocblas_status rocblas_rot_batched_ex(rocblas_handle handle, rocblas_int n, void *x, rocblas_datatype x_type, rocblas_int incx, void *y, rocblas_datatype y_type, rocblas_int incy, const void *c, const void *s, rocblas_datatype cs_type, rocblas_int batch_count, rocblas_datatype execution_type)#
BLAS EX API
rot_batched_ex applies the Givens rotation matrix defined by c=cos(alpha) and s=sin(alpha) to batched vectors x_i and y_i, for i = 1, …, batch_count. Scalars c and s may be stored in either host or device memory. Location is specified by calling rocblas_set_pointer_mode.
In the case where cs_type is real:
x := c * x + s * y y := c * y - s * x
In the case where cs_type is complex, the imaginary part of c is ignored:
x := real(c) * x + s * y y := real(c) * y - conj(s) * x
Currently supported datatypes are as follows:
x_type
y_type
cs_type
execution_type
bf16_r
bf16_r
bf16_r
f32_r
f16_r
f16_r
f16_r
f32_r
f32_r
f32_r
f32_r
f32_r
f64_r
f64_r
f64_r
f64_r
f32_c
f32_c
f32_c
f32_c
f32_c
f32_c
f32_r
f32_c
f64_c
f64_c
f64_c
f64_c
f64_c
f64_c
f64_r
f64_c
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] number of elements in each x_i and y_i vectors.
x – [inout] device array of deivce pointers storing each vector x_i.
x_type – [in] [rocblas_datatype] specifies the datatype of each vector x_i.
incx – [in] [rocblas_int] specifies the increment between elements of each x_i.
y – [inout] device array of device pointers storing each vector y_i.
y_type – [in] [rocblas_datatype] specifies the datatype of each vector y_i.
incy – [in] [rocblas_int] specifies the increment between elements of each y_i.
c – [in] device pointer or host pointer to scalar cosine component of the rotation matrix.
s – [in] device pointer or host pointer to scalar sine component of the rotation matrix.
cs_type – [in] [rocblas_datatype] specifies the datatype of c and s.
batch_count – [in] [rocblas_int] the number of x and y arrays, the number of batches.
execution_type – [in] [rocblas_datatype] specifies the datatype of computation.
-
rocblas_status rocblas_rot_strided_batched_ex(rocblas_handle handle, rocblas_int n, void *x, rocblas_datatype x_type, rocblas_int incx, rocblas_stride stride_x, void *y, rocblas_datatype y_type, rocblas_int incy, rocblas_stride stride_y, const void *c, const void *s, rocblas_datatype cs_type, rocblas_int batch_count, rocblas_datatype execution_type)#
BLAS Level 1 API
rot_strided_batched_ex applies the Givens rotation matrix defined by c=cos(alpha) and s=sin(alpha) to strided batched vectors x_i and y_i, for i = 1, …, batch_count. Scalars c and s may be stored in either host or device memory. Location is specified by calling rocblas_set_pointer_mode.
In the case where cs_type is real:
x := c * x + s * y y := c * y - s * x
In the case where cs_type is complex, the imaginary part of c is ignored:
x := real(c) * x + s * y y := real(c) * y - conj(s) * x
Currently supported datatypes are as follows:
x_type
y_type
cs_type
execution_type
bf16_r
bf16_r
bf16_r
f32_r
f16_r
f16_r
f16_r
f32_r
f32_r
f32_r
f32_r
f32_r
f64_r
f64_r
f64_r
f64_r
f32_c
f32_c
f32_c
f32_c
f32_c
f32_c
f32_r
f32_c
f64_c
f64_c
f64_c
f64_c
f64_c
f64_c
f64_r
f64_c
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] number of elements in each x_i and y_i vectors.
x – [inout] device pointer to the first vector x_1.
x_type – [in] [rocblas_datatype] specifies the datatype of each vector x_i.
incx – [in] [rocblas_int] specifies the increment between elements of each x_i.
stride_x – [in] [rocblas_stride] specifies the increment from the beginning of x_i to the beginning of x_(i+1)
y – [inout] device pointer to the first vector y_1.
y_type – [in] [rocblas_datatype] specifies the datatype of each vector y_i.
incy – [in] [rocblas_int] specifies the increment between elements of each y_i.
stride_y – [in] [rocblas_stride] specifies the increment from the beginning of y_i to the beginning of y_(i+1)
c – [in] device pointer or host pointer to scalar cosine component of the rotation matrix.
s – [in] device pointer or host pointer to scalar sine component of the rotation matrix.
cs_type – [in] [rocblas_datatype] specifies the datatype of c and s.
batch_count – [in] [rocblas_int] the number of x and y arrays, the number of batches.
execution_type – [in] [rocblas_datatype] specifies the datatype of computation.
rocblas_scal_ex + batched, strided_batched#
-
rocblas_status rocblas_scal_ex(rocblas_handle handle, rocblas_int n, const void *alpha, rocblas_datatype alpha_type, void *x, rocblas_datatype x_type, rocblas_int incx, rocblas_datatype execution_type)#
BLAS EX API
scal_ex scales each element of vector x with scalar alpha.
x := alpha * x
Currently supported datatypes are as follows:
alpha_type
x_type
execution_type
f32_r
bf16_r
f32_r
bf16_r
bf16_r
f32_r
f16_r
f16_r
f16_r
f16_r
f16_r
f32_r
f32_r
f16_r
f32_r
f32_r
f32_r
f32_r
f64_r
f64_r
f64_r
f32_c
f32_c
f32_c
f64_c
f64_c
f64_c
f32_r
f32_c
f32_c
f64_r
f64_c
f64_c
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] the number of elements in x.
alpha – [in] device pointer or host pointer for the scalar alpha.
alpha_type – [in] [rocblas_datatype] specifies the datatype of alpha.
x – [inout] device pointer storing vector x.
x_type – [in] [rocblas_datatype] specifies the datatype of vector x.
incx – [in] [rocblas_int] specifies the increment for the elements of x.
execution_type – [in] [rocblas_datatype] specifies the datatype of computation.
-
rocblas_status rocblas_scal_batched_ex(rocblas_handle handle, rocblas_int n, const void *alpha, rocblas_datatype alpha_type, void *x, rocblas_datatype x_type, rocblas_int incx, rocblas_int batch_count, rocblas_datatype execution_type)#
BLAS EX API
scal_batched_ex scales each element of each vector x_i with scalar alpha.
x_i := alpha * x_i
Currently supported datatypes are as follows:
alpha_type
x_type
execution_type
f32_r
bf16_r
f32_r
bf16_r
bf16_r
f32_r
f16_r
f16_r
f16_r
f16_r
f16_r
f32_r
f32_r
f16_r
f32_r
f32_r
f32_r
f32_r
f64_r
f64_r
f64_r
f32_c
f32_c
f32_c
f64_c
f64_c
f64_c
f32_r
f32_c
f32_c
f64_r
f64_c
f64_c
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] the number of elements in x.
alpha – [in] device pointer or host pointer for the scalar alpha.
alpha_type – [in] [rocblas_datatype] specifies the datatype of alpha.
x – [inout] device array of device pointers storing each vector x_i.
x_type – [in] [rocblas_datatype] specifies the datatype of each vector x_i.
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i.
batch_count – [in] [rocblas_int] number of instances in the batch.
execution_type – [in] [rocblas_datatype] specifies the datatype of computation.
-
rocblas_status rocblas_scal_strided_batched_ex(rocblas_handle handle, rocblas_int n, const void *alpha, rocblas_datatype alpha_type, void *x, rocblas_datatype x_type, rocblas_int incx, rocblas_stride stridex, rocblas_int batch_count, rocblas_datatype execution_type)#
BLAS EX API
scal_strided_batched_ex scales each element of vector x with scalar alpha over a set of strided batched vectors.
x := alpha * x
Currently supported datatypes are as follows:
alpha_type
x_type
execution_type
f32_r
bf16_r
f32_r
bf16_r
bf16_r
f32_r
f16_r
f16_r
f16_r
f16_r
f16_r
f32_r
f32_r
f16_r
f32_r
f32_r
f32_r
f32_r
f64_r
f64_r
f64_r
f32_c
f32_c
f32_c
f64_c
f64_c
f64_c
f32_r
f32_c
f32_c
f64_r
f64_c
f64_c
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
n – [in] [rocblas_int] the number of elements in x.
alpha – [in] device pointer or host pointer for the scalar alpha.
alpha_type – [in] [rocblas_datatype] specifies the datatype of alpha.
x – [inout] device pointer to the first vector x_1.
x_type – [in] [rocblas_datatype] specifies the datatype of each vector x_i.
incx – [in] [rocblas_int] specifies the increment for the elements of each x_i.
stridex – [in] [rocblas_stride] stride from the start of one vector (x_i) to the next one (x_i+1). There are no restrictions placed on stridex. However, ensure that stridex is of appropriate size. For a typical case this means stridex >= n * incx.
batch_count – [in] [rocblas_int] number of instances in the batch.
execution_type – [in] [rocblas_datatype] specifies the datatype of computation.
rocblas_gemm_ex + batched, strided_batched#
-
rocblas_status rocblas_gemm_ex(rocblas_handle handle, rocblas_operation transA, rocblas_operation transB, rocblas_int m, rocblas_int n, rocblas_int k, const void *alpha, const void *a, rocblas_datatype a_type, rocblas_int lda, const void *b, rocblas_datatype b_type, rocblas_int ldb, const void *beta, const void *c, rocblas_datatype c_type, rocblas_int ldc, void *d, rocblas_datatype d_type, rocblas_int ldd, rocblas_datatype compute_type, rocblas_gemm_algo algo, int32_t solution_index, uint32_t flags)#
BLAS EX API
gemm_ex performs one of the matrix-matrix operations:
D = alpha*op( A )*op( B ) + beta*C,
where op( X ) is one of
op( X ) = X or op( X ) = X**T or op( X ) = X**H,
alpha and beta are scalars, and A, B, C, and D are matrices, with op( A ) an m by k matrix, op( B ) a k by n matrix and C and D are m by n matrices. C and D may point to the same matrix if their parameters are identical.
Supported types are as follows:
rocblas_datatype_f64_r = a_type = b_type = c_type = d_type = compute_type
rocblas_datatype_f32_r = a_type = b_type = c_type = d_type = compute_type
rocblas_datatype_f16_r = a_type = b_type = c_type = d_type = compute_type
rocblas_datatype_f16_r = a_type = b_type = c_type = d_type; rocblas_datatype_f32_r = compute_type
rocblas_datatype_f16_r = a_type = b_type; rocblas_datatype_f32_r = c_type = d_type = compute_type
rocblas_datatype_bf16_r = a_type = b_type = c_type = d_type; rocblas_datatype_f32_r = compute_type
rocblas_datatype_bf16_r = a_type = b_type; rocblas_datatype_f32_r = c_type = d_type = compute_type
rocblas_datatype_i8_r = a_type = b_type; rocblas_datatype_i32_r = c_type = d_type = compute_type
rocblas_datatype_f32_c = a_type = b_type = c_type = d_type = compute_type
rocblas_datatype_f64_c = a_type = b_type = c_type = d_type = compute_type
Two int8 datatypes are supported: int8_t and rocblas_int8x4. int8_t is the C99 signed 8 bit integer. The default is int8_t and it is recommended int8_t be used. rocblas_int8x4 is a packed datatype. The packed int 8 datatype occurs if the user sets:
flags |= rocblas_gemm_flags_pack_int8x4;
For this packed int8 datatype matrices A and B are packed into int8x4 in the k dimension. This will impose the following size restrictions on A or B:
- k must be a multiple of 4 - if transA == rocblas_operation_transpose then lda must be a multiple of 4 - if transB == rocblas_operation_none then ldb must be a multiple of 4 - if transA == rocblas_operation_none the matrix A must have each 4 consecutive values in the k dimension packed - if transB == rocblas_operation_transpose the matrix B must have each 4 consecutive values in the k dimension packed.
This packing can be achieved with the following pseudo-code. The code assumes the original matrices are in A and B, and the packed matrices are A_packed and B_packed. The size of the A_packed and B_packed are the same as the size of the A and B respectively.
if(transA == rocblas_operation_none) { int nb = 4; for(int i_m = 0; i_m < m; i_m++) { for(int i_k = 0; i_k < k; i_k++) { A_packed[i_k % nb + (i_m + (i_k / nb) * lda) * nb] = A[i_m + i_k * lda]; } } } else { A_packed = A; } if(transB == rocblas_operation_transpose) { int nb = 4; for(int i_n = 0; i_n < m; i_n++) { for(int i_k = 0; i_k < k; i_k++) { B_packed[i_k % nb + (i_n + (i_k / nb) * ldb) * nb] = B[i_n + i_k * ldb]; } } } else { B_packed = B; }
Please note that the use of packed int8x4 is deprecated and will be removed in a future release. It is strongly recommended that users do not use the rocblas_gemm_flags_pack_int8x4 flag.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
transA – [in] [rocblas_operation] specifies the form of op( A ).
transB – [in] [rocblas_operation] specifies the form of op( B ).
m – [in] [rocblas_int] matrix dimension m.
n – [in] [rocblas_int] matrix dimension n.
k – [in] [rocblas_int] matrix dimension k.
alpha – [in] [const void *] device pointer or host pointer specifying the scalar alpha. Same datatype as compute_type.
a – [in] [void *] device pointer storing matrix A.
a_type – [in] [rocblas_datatype] specifies the datatype of matrix A.
lda – [in] [rocblas_int] specifies the leading dimension of A.
b – [in] [void *] device pointer storing matrix B.
b_type – [in] [rocblas_datatype] specifies the datatype of matrix B.
ldb – [in] [rocblas_int] specifies the leading dimension of B.
beta – [in] [const void *] device pointer or host pointer specifying the scalar beta. Same datatype as compute_type.
c – [in] [void *] device pointer storing matrix C.
c_type – [in] [rocblas_datatype] specifies the datatype of matrix C.
ldc – [in] [rocblas_int] specifies the leading dimension of C.
d – [out] [void *] device pointer storing matrix D. If d and c pointers are to the same matrix then d_type must equal c_type and ldd must equal ldc or the respective invalid status will be returned.
d_type – [in] [rocblas_datatype] specifies the datatype of matrix D.
ldd – [in] [rocblas_int] specifies the leading dimension of D.
compute_type – [in] [rocblas_datatype] specifies the datatype of computation.
algo – [in] [rocblas_gemm_algo] enumerant specifying the algorithm type.
solution_index – [in] [int32_t] if algo is rocblas_gemm_algo_solution_index, this controls which solution is used. When algo is not rocblas_gemm_algo_solution_index, or if solution_index <= 0, the default solution is used. This parameter was unused in previous releases and instead always used the default solution
flags – [in] [uint32_t] optional gemm flags.
-
rocblas_status rocblas_gemm_batched_ex(rocblas_handle handle, rocblas_operation transA, rocblas_operation transB, rocblas_int m, rocblas_int n, rocblas_int k, const void *alpha, const void *a, rocblas_datatype a_type, rocblas_int lda, const void *b, rocblas_datatype b_type, rocblas_int ldb, const void *beta, const void *c, rocblas_datatype c_type, rocblas_int ldc, void *d, rocblas_datatype d_type, rocblas_int ldd, rocblas_int batch_count, rocblas_datatype compute_type, rocblas_gemm_algo algo, int32_t solution_index, uint32_t flags)#
BLAS EX API
gemm_batched_ex performs one of the batched matrix-matrix operations: D_i = alpha*op(A_i)*op(B_i) + beta*C_i, for i = 1, …, batch_count. where op( X ) is one of op( X ) = X or op( X ) = X**T or op( X ) = X**H, alpha and beta are scalars, and A, B, C, and D are batched pointers to matrices, with op( A ) an m by k by batch_count batched matrix, op( B ) a k by n by batch_count batched matrix and C and D are m by n by batch_count batched matrices. The batched matrices are an array of pointers to matrices. The number of pointers to matrices is batch_count. C and D may point to the same matrices if their parameters are identical.
Supported types are as follows:
rocblas_datatype_f64_r = a_type = b_type = c_type = d_type = compute_type
rocblas_datatype_f32_r = a_type = b_type = c_type = d_type = compute_type
rocblas_datatype_f16_r = a_type = b_type = c_type = d_type = compute_type
rocblas_datatype_f16_r = a_type = b_type = c_type = d_type; rocblas_datatype_f32_r = compute_type
rocblas_datatype_bf16_r = a_type = b_type = c_type = d_type; rocblas_datatype_f32_r = compute_type
rocblas_datatype_i8_r = a_type = b_type; rocblas_datatype_i32_r = c_type = d_type = compute_type
rocblas_datatype_f32_c = a_type = b_type = c_type = d_type = compute_type
rocblas_datatype_f64_c = a_type = b_type = c_type = d_type = compute_type
Two int8 datatypes are supported: int8_t and rocblas_int8x4. int8_t is the C99 signed 8 bit integer. The default is int8_t and it is recommended int8_t be used. rocblas_int8x4 is a packed datatype. The packed int 8 datatype occurs if the user sets:
flags |= rocblas_gemm_flags_pack_int8x4;
For this packed int8 datatype matrices A and B are packed into int8x4 in the k dimension. This will impose the following size restrictions on A or B:
- k must be a multiple of 4 - if transA == rocblas_operation_transpose then lda must be a multiple of 4 - if transB == rocblas_operation_none then ldb must be a multiple of 4 - if transA == rocblas_operation_none the matrix A must have each 4 consecutive values in the k dimension packed - if transB == rocblas_operation_transpose the matrix B must have each 4 consecutive values in the k dimension packed.
This packing can be achieved with the following pseudo-code. The code assumes the original matrices are in A and B, and the packed matrices are A_packed and B_packed. The size of the A_packed and B_packed are the same as the size of the A and B respectively.
if(transA == rocblas_operation_none) { int nb = 4; for(int i_m = 0; i_m < m; i_m++) { for(int i_k = 0; i_k < k; i_k++) { A_packed[i_k % nb + (i_m + (i_k / nb) * lda) * nb] = A[i_m + i_k * lda]; } } } else { A_packed = A; } if(transB == rocblas_operation_transpose) { int nb = 4; for(int i_n = 0; i_n < m; i_n++) { for(int i_k = 0; i_k < k; i_k++) { B_packed[i_k % nb + (i_n + (i_k / nb) * ldb) * nb] = B[i_n + i_k * ldb]; } } } else { B_packed = B; }
Please note that the use of packed int8x4 is deprecated and will be removed in a future release. It is strongly recommended that users do not use the rocblas_gemm_flags_pack_int8x4 flag.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
transA – [in] [rocblas_operation] specifies the form of op( A ).
transB – [in] [rocblas_operation] specifies the form of op( B ).
m – [in] [rocblas_int] matrix dimension m.
n – [in] [rocblas_int] matrix dimension n.
k – [in] [rocblas_int] matrix dimension k.
alpha – [in] [const void *] device pointer or host pointer specifying the scalar alpha. Same datatype as compute_type.
a – [in] [void *] device pointer storing array of pointers to each matrix A_i.
a_type – [in] [rocblas_datatype] specifies the datatype of each matrix A_i.
lda – [in] [rocblas_int] specifies the leading dimension of each A_i.
b – [in] [void *] device pointer storing array of pointers to each matrix B_i.
b_type – [in] [rocblas_datatype] specifies the datatype of each matrix B_i.
ldb – [in] [rocblas_int] specifies the leading dimension of each B_i.
beta – [in] [const void *] device pointer or host pointer specifying the scalar beta. Same datatype as compute_type.
c – [in] [void *] device array of device pointers to each matrix C_i.
c_type – [in] [rocblas_datatype] specifies the datatype of each matrix C_i.
ldc – [in] [rocblas_int] specifies the leading dimension of each C_i.
d – [out] [void *] device array of device pointers to each matrix D_i. If d and c are the same array of matrix pointers then d_type must equal c_type and ldd must equal ldc or the respective invalid status will be returned.
d_type – [in] [rocblas_datatype] specifies the datatype of each matrix D_i.
ldd – [in] [rocblas_int] specifies the leading dimension of each D_i.
batch_count – [in] [rocblas_int] number of gemm operations in the batch.
compute_type – [in] [rocblas_datatype] specifies the datatype of computation.
algo – [in] [rocblas_gemm_algo] enumerant specifying the algorithm type.
solution_index – [in] [int32_t] if algo is rocblas_gemm_algo_solution_index, this controls which solution is used. When algo is not rocblas_gemm_algo_solution_index, or if solution_index <= 0, the default solution is used. This parameter was unused in previous releases and instead always used the default solution
flags – [in] [uint32_t] optional gemm flags.
-
rocblas_status rocblas_gemm_strided_batched_ex(rocblas_handle handle, rocblas_operation transA, rocblas_operation transB, rocblas_int m, rocblas_int n, rocblas_int k, const void *alpha, const void *a, rocblas_datatype a_type, rocblas_int lda, rocblas_stride stride_a, const void *b, rocblas_datatype b_type, rocblas_int ldb, rocblas_stride stride_b, const void *beta, const void *c, rocblas_datatype c_type, rocblas_int ldc, rocblas_stride stride_c, void *d, rocblas_datatype d_type, rocblas_int ldd, rocblas_stride stride_d, rocblas_int batch_count, rocblas_datatype compute_type, rocblas_gemm_algo algo, int32_t solution_index, uint32_t flags)#
BLAS EX API
gemm_strided_batched_ex performs one of the strided_batched matrix-matrix operations:
D_i = alpha*op(A_i)*op(B_i) + beta*C_i, for i = 1, ..., batch_count
where op( X ) is one of
op( X ) = X or op( X ) = X**T or op( X ) = X**H,
alpha and beta are scalars, and A, B, C, and D are strided_batched matrices, with op( A ) an m by k by batch_count strided_batched matrix, op( B ) a k by n by batch_count strided_batched matrix and C and D are m by n by batch_count strided_batched matrices. C and D may point to the same matrices if their parameters are identical.
The strided_batched matrices are multiple matrices separated by a constant stride. The number of matrices is batch_count.
Supported types are as follows:
rocblas_datatype_f64_r = a_type = b_type = c_type = d_type = compute_type
rocblas_datatype_f32_r = a_type = b_type = c_type = d_type = compute_type
rocblas_datatype_f16_r = a_type = b_type = c_type = d_type = compute_type
rocblas_datatype_f16_r = a_type = b_type = c_type = d_type; rocblas_datatype_f32_r = compute_type
rocblas_datatype_bf16_r = a_type = b_type = c_type = d_type; rocblas_datatype_f32_r = compute_type
rocblas_datatype_i8_r = a_type = b_type; rocblas_datatype_i32_r = c_type = d_type = compute_type
rocblas_datatype_f32_c = a_type = b_type = c_type = d_type = compute_type
rocblas_datatype_f64_c = a_type = b_type = c_type = d_type = compute_type
Two int8 datatypes are supported: int8_t and rocblas_int8x4. int8_t is the C99 signed 8 bit integer. The default is int8_t and it is recommended int8_t be used. rocblas_int8x4 is a packed datatype. The packed int 8 datatype occurs if the user sets:
flags |= rocblas_gemm_flags_pack_int8x4;
For this packed int8 datatype matrices A and B are packed into int8x4 in the k dimension. This will impose the following size restrictions on A or B:
- k must be a multiple of 4 - if transA == rocblas_operation_transpose then lda must be a multiple of 4 - if transB == rocblas_operation_none then ldb must be a multiple of 4 - if transA == rocblas_operation_none the matrix A must have each 4 consecutive values in the k dimension packed - if transB == rocblas_operation_transpose the matrix B must have each 4 consecutive values in the k dimension packed.
This packing can be achieved with the following pseudo-code. The code assumes the original matrices are in A and B, and the packed matrices are A_packed and B_packed. The size of the A_packed and B_packed are the same as the size of the A and B respectively.
if(transA == rocblas_operation_none) { int nb = 4; for(int i_m = 0; i_m < m; i_m++) { for(int i_k = 0; i_k < k; i_k++) { A_packed[i_k % nb + (i_m + (i_k / nb) * lda) * nb] = A[i_m + i_k * lda]; } } } else { A_packed = A; } if(transB == rocblas_operation_transpose) { int nb = 4; for(int i_n = 0; i_n < m; i_n++) { for(int i_k = 0; i_k < k; i_k++) { B_packed[i_k % nb + (i_n + (i_k / nb) * ldb) * nb] = B[i_n + i_k * ldb]; } } } else { B_packed = B; }
Please note that the use of packed int8x4 is deprecated and will be removed in a future release. It is strongly recommended that users do not use the rocblas_gemm_flags_pack_int8x4 flag.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
transA – [in] [rocblas_operation] specifies the form of op( A ).
transB – [in] [rocblas_operation] specifies the form of op( B ).
m – [in] [rocblas_int] matrix dimension m.
n – [in] [rocblas_int] matrix dimension n.
k – [in] [rocblas_int] matrix dimension k.
alpha – [in] [const void *] device pointer or host pointer specifying the scalar alpha. Same datatype as compute_type.
a – [in] [void *] device pointer pointing to first matrix A_1.
a_type – [in] [rocblas_datatype] specifies the datatype of each matrix A_i.
lda – [in] [rocblas_int] specifies the leading dimension of each A_i.
stride_a – [in] [rocblas_stride] specifies stride from start of one A_i matrix to the next A_(i + 1).
b – [in] [void *] device pointer pointing to first matrix B_1.
b_type – [in] [rocblas_datatype] specifies the datatype of each matrix B_i.
ldb – [in] [rocblas_int] specifies the leading dimension of each B_i.
stride_b – [in] [rocblas_stride] specifies stride from start of one B_i matrix to the next B_(i + 1).
beta – [in] [const void *] device pointer or host pointer specifying the scalar beta. Same datatype as compute_type.
c – [in] [void *] device pointer pointing to first matrix C_1.
c_type – [in] [rocblas_datatype] specifies the datatype of each matrix C_i.
ldc – [in] [rocblas_int] specifies the leading dimension of each C_i.
stride_c – [in] [rocblas_stride] specifies stride from start of one C_i matrix to the next C_(i + 1).
d – [out] [void *] device pointer storing each matrix D_i. If d and c pointers are to the same matrix then d_type must equal c_type and ldd must equal ldc and stride_d must equal stride_c or the respective invalid status will be returned.
d_type – [in] [rocblas_datatype] specifies the datatype of each matrix D_i.
ldd – [in] [rocblas_int] specifies the leading dimension of each D_i.
stride_d – [in] [rocblas_stride] specifies stride from start of one D_i matrix to the next D_(i + 1).
batch_count – [in] [rocblas_int] number of gemm operations in the batch.
compute_type – [in] [rocblas_datatype] specifies the datatype of computation.
algo – [in] [rocblas_gemm_algo] enumerant specifying the algorithm type.
solution_index – [in] [int32_t] if algo is rocblas_gemm_algo_solution_index, this controls which solution is used. When algo is not rocblas_gemm_algo_solution_index, or if solution_index <= 0, the default solution is used. This parameter was unused in previous releases and instead always used the default solution
flags – [in] [uint32_t] optional gemm flags.
rocblas_trsm_ex + batched, strided_batched#
-
rocblas_status rocblas_trsm_ex(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const void *alpha, const void *A, rocblas_int lda, void *B, rocblas_int ldb, const void *invA, rocblas_int invA_size, rocblas_datatype compute_type)#
BLAS EX API
trsm_ex solves:
op(A)*X = alpha*B or X*op(A) = alpha*B,
where alpha is a scalar, X and B are m by n matrices, A is triangular matrix and op(A) is one of
op( A ) = A or op( A ) = A^T or op( A ) = A^H.
The matrix X is overwritten on B.
This function gives the user the ability to reuse the invA matrix between runs. If invA == NULL, rocblas_trsm_ex will automatically calculate invA on every run.
Setting up invA: The accepted invA matrix consists of the packed 128x128 inverses of the diagonal blocks of matrix A, followed by any smaller diagonal block that remains. To set up invA it is recommended that rocblas_trtri_batched be used with matrix A as the input.
Device memory of size 128 x k should be allocated for invA ahead of time, where k is m when rocblas_side_left and is n when rocblas_side_right. The actual number of elements in invA should be passed as invA_size.
To begin, rocblas_trtri_batched must be called on the full 128x128-sized diagonal blocks of matrix A. Below are the restricted parameters:
n = 128
ldinvA = 128
stride_invA = 128x128
batch_count = k / 128,
Then any remaining block may be added:
n = k % 128
invA = invA + stride_invA * previous_batch_count
ldinvA = 128
batch_count = 1
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
side – [in] [rocblas_side]
rocblas_side_left: op(A)*X = alpha*B
rocblas_side_right: X*op(A) = alpha*B
uplo – [in] [rocblas_fill]
rocblas_fill_upper: A is an upper triangular matrix.
rocblas_fill_lower: A is a lower triangular matrix.
transA – [in] [rocblas_operation]
transB: op(A) = A.
rocblas_operation_transpose: op(A) = A^T
rocblas_operation_conjugate_transpose: op(A) = A^H
diag – [in] [rocblas_diagonal]
rocblas_diagonal_unit: A is assumed to be unit triangular.
rocblas_diagonal_non_unit: A is not assumed to be unit triangular.
m – [in] [rocblas_int] m specifies the number of rows of B. m >= 0.
n – [in] [rocblas_int] n specifies the number of columns of B. n >= 0.
alpha – [in] [void *] device pointer or host pointer specifying the scalar alpha. When alpha is &zero then A is not referenced, and B need not be set before entry.
A – [in] [void *] device pointer storing matrix A. of dimension ( lda, k ), where k is m when rocblas_side_left and is n when rocblas_side_right only the upper/lower triangular part is accessed.
lda – [in] [rocblas_int] lda specifies the first dimension of A.
if side = rocblas_side_left, lda >= max( 1, m ), if side = rocblas_side_right, lda >= max( 1, n ).
B – [inout] [void *] device pointer storing matrix B. B is of dimension ( ldb, n ). Before entry, the leading m by n part of the array B must contain the right-hand side matrix B, and on exit is overwritten by the solution matrix X.
ldb – [in] [rocblas_int] ldb specifies the first dimension of B. ldb >= max( 1, m ).
invA – [in] [void *] device pointer storing the inverse diagonal blocks of A. invA is of dimension ( ld_invA, k ), where k is m when rocblas_side_left and is n when rocblas_side_right. ld_invA must be equal to 128.
invA_size – [in] [rocblas_int] invA_size specifies the number of elements of device memory in invA.
compute_type – [in] [rocblas_datatype] specifies the datatype of computation.
-
rocblas_status rocblas_trsm_batched_ex(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const void *alpha, const void *A, rocblas_int lda, void *B, rocblas_int ldb, rocblas_int batch_count, const void *invA, rocblas_int invA_size, rocblas_datatype compute_type)#
BLAS EX API
trsm_batched_ex solves:
op(A_i)*X_i = alpha*B_i or X_i*op(A_i) = alpha*B_i,
for i = 1, …, batch_count; and where alpha is a scalar, X and B are arrays of m by n matrices, A is an array of triangular matrix and each op(A_i) is one of
op( A_i ) = A_i or op( A_i ) = A_i^T or op( A_i ) = A_i^H.
Each matrix X_i is overwritten on B_i.
This function gives the user the ability to reuse the invA matrix between runs. If invA == NULL, rocblas_trsm_batched_ex will automatically calculate each invA_i on every run.
Setting up invA: Each accepted invA_i matrix consists of the packed 128x128 inverses of the diagonal blocks of matrix A_i, followed by any smaller diagonal block that remains. To set up each invA_i it is recommended that rocblas_trtri_batched be used with matrix A_i as the input. invA is an array of pointers of batch_count length holding each invA_i.
Device memory of size 128 x k should be allocated for each invA_i ahead of time, where k is m when rocblas_side_left and is n when rocblas_side_right. The actual number of elements in each invA_i should be passed as invA_size.
To begin, rocblas_trtri_batched must be called on the full 128x128-sized diagonal blocks of each matrix A_i. Below are the restricted parameters:
n = 128
ldinvA = 128
stride_invA = 128x128
batch_count = k / 128,
Then any remaining block may be added:
n = k % 128
invA = invA + stride_invA * previous_batch_count
ldinvA = 128
batch_count = 1
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
side – [in] [rocblas_side]
rocblas_side_left: op(A)*X = alpha*B
rocblas_side_right: X*op(A) = alpha*B
uplo – [in] [rocblas_fill]
rocblas_fill_upper: each A_i is an upper triangular matrix.
rocblas_fill_lower: each A_i is a lower triangular matrix.
transA – [in] [rocblas_operation]
transB: op(A) = A.
rocblas_operation_transpose: op(A) = A^T
rocblas_operation_conjugate_transpose: op(A) = A^H
diag – [in] [rocblas_diagonal]
rocblas_diagonal_unit: each A_i is assumed to be unit triangular.
rocblas_diagonal_non_unit: each A_i is not assumed to be unit triangular.
m – [in] [rocblas_int] m specifies the number of rows of each B_i. m >= 0.
n – [in] [rocblas_int] n specifies the number of columns of each B_i. n >= 0.
alpha – [in] [void *] device pointer or host pointer alpha specifying the scalar alpha. When alpha is &zero then A is not referenced, and B need not be set before entry.
A – [in] [void *] device array of device pointers storing each matrix A_i. each A_i is of dimension ( lda, k ), where k is m when rocblas_side_left and is n when rocblas_side_right only the upper/lower triangular part is accessed.
lda – [in] [rocblas_int] lda specifies the first dimension of each A_i.
if side = rocblas_side_left, lda >= max( 1, m ), if side = rocblas_side_right, lda >= max( 1, n ).
B – [inout] [void *] device array of device pointers storing each matrix B_i. each B_i is of dimension ( ldb, n ). Before entry, the leading m by n part of the array B_i must contain the right-hand side matrix B_i, and on exit is overwritten by the solution matrix X_i
ldb – [in] [rocblas_int] ldb specifies the first dimension of each B_i. ldb >= max( 1, m ).
batch_count – [in] [rocblas_int] specifies how many batches.
invA – [in] [void *] device array of device pointers storing the inverse diagonal blocks of each A_i. each invA_i is of dimension ( ld_invA, k ), where k is m when rocblas_side_left and is n when rocblas_side_right. ld_invA must be equal to 128.
invA_size – [in] [rocblas_int] invA_size specifies the number of elements of device memory in each invA_i.
compute_type – [in] [rocblas_datatype] specifies the datatype of computation.
-
rocblas_status rocblas_trsm_strided_batched_ex(rocblas_handle handle, rocblas_side side, rocblas_fill uplo, rocblas_operation transA, rocblas_diagonal diag, rocblas_int m, rocblas_int n, const void *alpha, const void *A, rocblas_int lda, rocblas_stride stride_A, void *B, rocblas_int ldb, rocblas_stride stride_B, rocblas_int batch_count, const void *invA, rocblas_int invA_size, rocblas_stride stride_invA, rocblas_datatype compute_type)#
BLAS EX API
trsm_strided_batched_ex solves:
op(A_i)*X_i = alpha*B_i or X_i*op(A_i) = alpha*B_i,
for i = 1, …, batch_count; and where alpha is a scalar, X and B are strided batched m by n matrices, A is a strided batched triangular matrix and op(A_i) is one of
op( A_i ) = A_i or op( A_i ) = A_i^T or op( A_i ) = A_i^H.
Each matrix X_i is overwritten on B_i.
This function gives the user the ability to reuse each invA_i matrix between runs. If invA == NULL, rocblas_trsm_batched_ex will automatically calculate each invA_i on every run.
Setting up invA: Each accepted invA_i matrix consists of the packed 128x128 inverses of the diagonal blocks of matrix A_i, followed by any smaller diagonal block that remains. To set up invA_i it is recommended that rocblas_trtri_batched be used with matrix A_i as the input. invA is a contiguous piece of memory holding each invA_i.
Device memory of size 128 x k should be allocated for each invA_i ahead of time, where k is m when rocblas_side_left and is n when rocblas_side_right. The actual number of elements in each invA_i should be passed as invA_size.
To begin, rocblas_trtri_batched must be called on the full 128x128-sized diagonal blocks of each matrix A_i. Below are the restricted parameters:
n = 128
ldinvA = 128
stride_invA = 128x128
batch_count = k / 128
Then any remaining block may be added:
n = k % 128
invA = invA + stride_invA * previous_batch_count
ldinvA = 128
batch_count = 1
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
side – [in] [rocblas_side]
rocblas_side_left: op(A)*X = alpha*B
rocblas_side_right: X*op(A) = alpha*B
uplo – [in] [rocblas_fill]
rocblas_fill_upper: each A_i is an upper triangular matrix.
rocblas_fill_lower: each A_i is a lower triangular matrix.
transA – [in] [rocblas_operation]
transB: op(A) = A.
rocblas_operation_transpose: op(A) = A^T
rocblas_operation_conjugate_transpose: op(A) = A^H
diag – [in] [rocblas_diagonal]
rocblas_diagonal_unit: each A_i is assumed to be unit triangular.
rocblas_diagonal_non_unit: each A_i is not assumed to be unit triangular.
m – [in] [rocblas_int] m specifies the number of rows of each B_i. m >= 0.
n – [in] [rocblas_int] n specifies the number of columns of each B_i. n >= 0.
alpha – [in] [void *] device pointer or host pointer specifying the scalar alpha. When alpha is &zero then A is not referenced, and B need not be set before entry.
A – [in] [void *] device pointer storing matrix A. of dimension ( lda, k ), where k is m when rocblas_side_left and is n when rocblas_side_right only the upper/lower triangular part is accessed.
lda – [in] [rocblas_int] lda specifies the first dimension of A.
if side = rocblas_side_left, lda >= max( 1, m ), if side = rocblas_side_right, lda >= max( 1, n ).
stride_A – [in] [rocblas_stride] The stride between each A matrix.
B – [inout] [void *] device pointer pointing to first matrix B_i. each B_i is of dimension ( ldb, n ). Before entry, the leading m by n part of each array B_i must contain the right-hand side of matrix B_i, and on exit is overwritten by the solution matrix X_i.
ldb – [in] [rocblas_int] ldb specifies the first dimension of each B_i. ldb >= max( 1, m ).
stride_B – [in] [rocblas_stride] The stride between each B_i matrix.
batch_count – [in] [rocblas_int] specifies how many batches.
invA – [in] [void *] device pointer storing the inverse diagonal blocks of each A_i. invA points to the first invA_1. each invA_i is of dimension ( ld_invA, k ), where k is m when rocblas_side_left and is n when rocblas_side_right. ld_invA must be equal to 128.
invA_size – [in] [rocblas_int] invA_size specifies the number of elements of device memory in each invA_i.
stride_invA – [in] [rocblas_stride] The stride between each invA matrix.
compute_type – [in] [rocblas_datatype] specifies the datatype of computation.
rocblas_Xgeam + batched, strided_batched#
-
rocblas_status rocblas_sgeam(rocblas_handle handle, rocblas_operation transA, rocblas_operation transB, rocblas_int m, rocblas_int n, const float *alpha, const float *A, rocblas_int lda, const float *beta, const float *B, rocblas_int ldb, float *C, rocblas_int ldc)#
-
rocblas_status rocblas_dgeam(rocblas_handle handle, rocblas_operation transA, rocblas_operation transB, rocblas_int m, rocblas_int n, const double *alpha, const double *A, rocblas_int lda, const double *beta, const double *B, rocblas_int ldb, double *C, rocblas_int ldc)#
-
rocblas_status rocblas_cgeam(rocblas_handle handle, rocblas_operation transA, rocblas_operation transB, rocblas_int m, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *A, rocblas_int lda, const rocblas_float_complex *beta, const rocblas_float_complex *B, rocblas_int ldb, rocblas_float_complex *C, rocblas_int ldc)#
-
rocblas_status rocblas_zgeam(rocblas_handle handle, rocblas_operation transA, rocblas_operation transB, rocblas_int m, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *A, rocblas_int lda, const rocblas_double_complex *beta, const rocblas_double_complex *B, rocblas_int ldb, rocblas_double_complex *C, rocblas_int ldc)#
BLAS Level 3 API
geam performs one of the matrix-matrix operations:
C = alpha*op( A ) + beta*op( B ), where op( X ) is one of op( X ) = X or op( X ) = X**T or op( X ) = X**H, alpha and beta are scalars, and A, B and C are matrices, with op( A ) an m by n matrix, op( B ) an m by n matrix, and C an m by n matrix.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
transA – [in] [rocblas_operation] specifies the form of op( A ).
transB – [in] [rocblas_operation] specifies the form of op( B ).
m – [in] [rocblas_int] matrix dimension m.
n – [in] [rocblas_int] matrix dimension n.
alpha – [in] device pointer or host pointer specifying the scalar alpha.
A – [in] device pointer storing matrix A.
lda – [in] [rocblas_int] specifies the leading dimension of A.
beta – [in] device pointer or host pointer specifying the scalar beta.
B – [in] device pointer storing matrix B.
ldb – [in] [rocblas_int] specifies the leading dimension of B.
C – [inout] device pointer storing matrix C.
ldc – [in] [rocblas_int] specifies the leading dimension of C.
-
rocblas_status rocblas_sgeam_batched(rocblas_handle handle, rocblas_operation transA, rocblas_operation transB, rocblas_int m, rocblas_int n, const float *alpha, const float *const A[], rocblas_int lda, const float *beta, const float *const B[], rocblas_int ldb, float *const C[], rocblas_int ldc, rocblas_int batch_count)#
-
rocblas_status rocblas_dgeam_batched(rocblas_handle handle, rocblas_operation transA, rocblas_operation transB, rocblas_int m, rocblas_int n, const double *alpha, const double *const A[], rocblas_int lda, const double *beta, const double *const B[], rocblas_int ldb, double *const C[], rocblas_int ldc, rocblas_int batch_count)#
-
rocblas_status rocblas_cgeam_batched(rocblas_handle handle, rocblas_operation transA, rocblas_operation transB, rocblas_int m, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *const A[], rocblas_int lda, const rocblas_float_complex *beta, const rocblas_float_complex *const B[], rocblas_int ldb, rocblas_float_complex *const C[], rocblas_int ldc, rocblas_int batch_count)#
-
rocblas_status rocblas_zgeam_batched(rocblas_handle handle, rocblas_operation transA, rocblas_operation transB, rocblas_int m, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *const A[], rocblas_int lda, const rocblas_double_complex *beta, const rocblas_double_complex *const B[], rocblas_int ldb, rocblas_double_complex *const C[], rocblas_int ldc, rocblas_int batch_count)#
BLAS Level 3 API
geam_batched performs one of the batched matrix-matrix operations:
C_i = alpha*op( A_i ) + beta*op( B_i ) for i = 0, 1, ... batch_count - 1, where alpha and beta are scalars, and op(A_i), op(B_i) and C_i are m by n matrices and op( X ) is one of op( X ) = X or op( X ) = X**T
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
transA – [in] [rocblas_operation] specifies the form of op( A ).
transB – [in] [rocblas_operation] specifies the form of op( B ).
m – [in] [rocblas_int] matrix dimension m.
n – [in] [rocblas_int] matrix dimension n.
alpha – [in] device pointer or host pointer specifying the scalar alpha.
A – [in] device array of device pointers storing each matrix A_i on the GPU. Each A_i is of dimension ( lda, k ), where k is m when transA == rocblas_operation_none and is n when transA == rocblas_operation_transpose.
lda – [in] [rocblas_int] specifies the leading dimension of A.
beta – [in] device pointer or host pointer specifying the scalar beta.
B – [in] device array of device pointers storing each matrix B_i on the GPU. Each B_i is of dimension ( ldb, k ), where k is m when transB == rocblas_operation_none and is n when transB == rocblas_operation_transpose.
ldb – [in] [rocblas_int] specifies the leading dimension of B.
C – [inout] device array of device pointers storing each matrix C_i on the GPU. Each C_i is of dimension ( ldc, n ).
ldc – [in] [rocblas_int] specifies the leading dimension of C.
batch_count – [in] [rocblas_int] number of instances i in the batch.
-
rocblas_status rocblas_sgeam_strided_batched(rocblas_handle handle, rocblas_operation transA, rocblas_operation transB, rocblas_int m, rocblas_int n, const float *alpha, const float *A, rocblas_int lda, rocblas_stride stride_A, const float *beta, const float *B, rocblas_int ldb, rocblas_stride stride_B, float *C, rocblas_int ldc, rocblas_stride stride_C, rocblas_int batch_count)#
-
rocblas_status rocblas_dgeam_strided_batched(rocblas_handle handle, rocblas_operation transA, rocblas_operation transB, rocblas_int m, rocblas_int n, const double *alpha, const double *A, rocblas_int lda, rocblas_stride stride_A, const double *beta, const double *B, rocblas_int ldb, rocblas_stride stride_B, double *C, rocblas_int ldc, rocblas_stride stride_C, rocblas_int batch_count)#
-
rocblas_status rocblas_cgeam_strided_batched(rocblas_handle handle, rocblas_operation transA, rocblas_operation transB, rocblas_int m, rocblas_int n, const rocblas_float_complex *alpha, const rocblas_float_complex *A, rocblas_int lda, rocblas_stride stride_A, const rocblas_float_complex *beta, const rocblas_float_complex *B, rocblas_int ldb, rocblas_stride stride_B, rocblas_float_complex *C, rocblas_int ldc, rocblas_stride stride_C, rocblas_int batch_count)#
-
rocblas_status rocblas_zgeam_strided_batched(rocblas_handle handle, rocblas_operation transA, rocblas_operation transB, rocblas_int m, rocblas_int n, const rocblas_double_complex *alpha, const rocblas_double_complex *A, rocblas_int lda, rocblas_stride stride_A, const rocblas_double_complex *beta, const rocblas_double_complex *B, rocblas_int ldb, rocblas_stride stride_B, rocblas_double_complex *C, rocblas_int ldc, rocblas_stride stride_C, rocblas_int batch_count)#
BLAS Level 3 API
geam_strided_batched performs one of the batched matrix-matrix operations:
C_i = alpha*op( A_i ) + beta*op( B_i ) for i = 0, 1, ... batch_count - 1, where alpha and beta are scalars, and op(A_i), op(B_i) and C_i are m by n matrices and op( X ) is one of op( X ) = X or op( X ) = X**T
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
transA – [in] [rocblas_operation] specifies the form of op( A ).
transB – [in] [rocblas_operation] specifies the form of op( B ).
m – [in] [rocblas_int] matrix dimension m.
n – [in] [rocblas_int] matrix dimension n.
alpha – [in] device pointer or host pointer specifying the scalar alpha.
A – [in] device pointer to the first matrix A_0 on the GPU. Each A_i is of dimension ( lda, k ), where k is m when transA == rocblas_operation_none and is n when transA == rocblas_operation_transpose.
lda – [in] [rocblas_int] specifies the leading dimension of A.
stride_A – [in] [rocblas_stride] stride from the start of one matrix (A_i) and the next one (A_i+1).
beta – [in] device pointer or host pointer specifying the scalar beta.
B – [in] pointer to the first matrix B_0 on the GPU. Each B_i is of dimension ( ldb, k ), where k is m when transB == rocblas_operation_none and is n when transB == rocblas_operation_transpose.
ldb – [in] [rocblas_int] specifies the leading dimension of B.
stride_B – [in] [rocblas_stride] stride from the start of one matrix (B_i) and the next one (B_i+1)
C – [inout] pointer to the first matrix C_0 on the GPU. Each C_i is of dimension ( ldc, n ).
ldc – [in] [rocblas_int] specifies the leading dimension of C.
stride_C – [in] [rocblas_stride] stride from the start of one matrix (C_i) and the next one (C_i+1).
batch_count – [in] [rocblas_int] number of instances i in the batch.
rocblas_Xdgmm + batched, strided_batched#
-
rocblas_status rocblas_sdgmm(rocblas_handle handle, rocblas_side side, rocblas_int m, rocblas_int n, const float *A, rocblas_int lda, const float *x, rocblas_int incx, float *C, rocblas_int ldc)#
-
rocblas_status rocblas_ddgmm(rocblas_handle handle, rocblas_side side, rocblas_int m, rocblas_int n, const double *A, rocblas_int lda, const double *x, rocblas_int incx, double *C, rocblas_int ldc)#
-
rocblas_status rocblas_cdgmm(rocblas_handle handle, rocblas_side side, rocblas_int m, rocblas_int n, const rocblas_float_complex *A, rocblas_int lda, const rocblas_float_complex *x, rocblas_int incx, rocblas_float_complex *C, rocblas_int ldc)#
-
rocblas_status rocblas_zdgmm(rocblas_handle handle, rocblas_side side, rocblas_int m, rocblas_int n, const rocblas_double_complex *A, rocblas_int lda, const rocblas_double_complex *x, rocblas_int incx, rocblas_double_complex *C, rocblas_int ldc)#
BLAS Level 3 API
dgmm performs one of the matrix-matrix operations:
C = A * diag(x) if side == rocblas_side_right C = diag(x) * A if side == rocblas_side_left where C and A are m by n dimensional matrices. diag( x ) is a diagonal matrix and x is vector of dimension n if side == rocblas_side_right and dimension m if side == rocblas_side_left.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
side – [in] [rocblas_side] specifies the side of diag(x).
m – [in] [rocblas_int] matrix dimension m.
n – [in] [rocblas_int] matrix dimension n.
A – [in] device pointer storing matrix A.
lda – [in] [rocblas_int] specifies the leading dimension of A.
x – [in] device pointer storing vector x.
incx – [in] [rocblas_int] specifies the increment between values of x
C – [inout] device pointer storing matrix C.
ldc – [in] [rocblas_int] specifies the leading dimension of C.
-
rocblas_status rocblas_sdgmm_batched(rocblas_handle handle, rocblas_side side, rocblas_int m, rocblas_int n, const float *const A[], rocblas_int lda, const float *const x[], rocblas_int incx, float *const C[], rocblas_int ldc, rocblas_int batch_count)#
-
rocblas_status rocblas_ddgmm_batched(rocblas_handle handle, rocblas_side side, rocblas_int m, rocblas_int n, const double *const A[], rocblas_int lda, const double *const x[], rocblas_int incx, double *const C[], rocblas_int ldc, rocblas_int batch_count)#
-
rocblas_status rocblas_cdgmm_batched(rocblas_handle handle, rocblas_side side, rocblas_int m, rocblas_int n, const rocblas_float_complex *const A[], rocblas_int lda, const rocblas_float_complex *const x[], rocblas_int incx, rocblas_float_complex *const C[], rocblas_int ldc, rocblas_int batch_count)#
-
rocblas_status rocblas_zdgmm_batched(rocblas_handle handle, rocblas_side side, rocblas_int m, rocblas_int n, const rocblas_double_complex *const A[], rocblas_int lda, const rocblas_double_complex *const x[], rocblas_int incx, rocblas_double_complex *const C[], rocblas_int ldc, rocblas_int batch_count)#
BLAS Level 3 API
dgmm_batched performs one of the batched matrix-matrix operations:
C_i = A_i * diag(x_i) for i = 0, 1, ... batch_count-1 if side == rocblas_side_right C_i = diag(x_i) * A_i for i = 0, 1, ... batch_count-1 if side == rocblas_side_left, where C_i and A_i are m by n dimensional matrices. diag(x_i) is a diagonal matrix and x_i is vector of dimension n if side == rocblas_side_right and dimension m if side == rocblas_side_left.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
side – [in] [rocblas_side] specifies the side of diag(x).
m – [in] [rocblas_int] matrix dimension m.
n – [in] [rocblas_int] matrix dimension n.
A – [in] device array of device pointers storing each matrix A_i on the GPU. Each A_i is of dimension ( lda, n ).
lda – [in] [rocblas_int] specifies the leading dimension of A_i.
x – [in] device array of device pointers storing each vector x_i on the GPU. Each x_i is of dimension n if side == rocblas_side_right and dimension m if side == rocblas_side_left.
incx – [in] [rocblas_int] specifies the increment between values of x_i.
C – [inout] device array of device pointers storing each matrix C_i on the GPU. Each C_i is of dimension ( ldc, n ).
ldc – [in] [rocblas_int] specifies the leading dimension of C_i.
batch_count – [in] [rocblas_int] number of instances in the batch.
-
rocblas_status rocblas_sdgmm_strided_batched(rocblas_handle handle, rocblas_side side, rocblas_int m, rocblas_int n, const float *A, rocblas_int lda, rocblas_stride stride_A, const float *x, rocblas_int incx, rocblas_stride stride_x, float *C, rocblas_int ldc, rocblas_stride stride_C, rocblas_int batch_count)#
-
rocblas_status rocblas_ddgmm_strided_batched(rocblas_handle handle, rocblas_side side, rocblas_int m, rocblas_int n, const double *A, rocblas_int lda, rocblas_stride stride_A, const double *x, rocblas_int incx, rocblas_stride stride_x, double *C, rocblas_int ldc, rocblas_stride stride_C, rocblas_int batch_count)#
-
rocblas_status rocblas_cdgmm_strided_batched(rocblas_handle handle, rocblas_side side, rocblas_int m, rocblas_int n, const rocblas_float_complex *A, rocblas_int lda, rocblas_stride stride_A, const rocblas_float_complex *x, rocblas_int incx, rocblas_stride stride_x, rocblas_float_complex *C, rocblas_int ldc, rocblas_stride stride_C, rocblas_int batch_count)#
-
rocblas_status rocblas_zdgmm_strided_batched(rocblas_handle handle, rocblas_side side, rocblas_int m, rocblas_int n, const rocblas_double_complex *A, rocblas_int lda, rocblas_stride stride_A, const rocblas_double_complex *x, rocblas_int incx, rocblas_stride stride_x, rocblas_double_complex *C, rocblas_int ldc, rocblas_stride stride_C, rocblas_int batch_count)#
BLAS Level 3 API
dgmm_strided_batched performs one of the batched matrix-matrix operations:
C_i = A_i * diag(x_i) if side == rocblas_side_right for i = 0, 1, ... batch_count-1 C_i = diag(x_i) * A_i if side == rocblas_side_left for i = 0, 1, ... batch_count-1, where C_i and A_i are m by n dimensional matrices. diag(x_i) is a diagonal matrix and x_i is vector of dimension n if side == rocblas_side_right and dimension m if side == rocblas_side_left.
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
side – [in] [rocblas_side] specifies the side of diag(x).
m – [in] [rocblas_int] matrix dimension m.
n – [in] [rocblas_int] matrix dimension n.
A – [in] device pointer to the first matrix A_0 on the GPU. Each A_i is of dimension ( lda, n ).
lda – [in] [rocblas_int] specifies the leading dimension of A.
stride_A – [in] [rocblas_stride] stride from the start of one matrix (A_i) and the next one (A_i+1).
x – [in] pointer to the first vector x_0 on the GPU. Each x_i is of dimension n if side == rocblas_side_right and dimension m if side == rocblas_side_left.
incx – [in] [rocblas_int] specifies the increment between values of x.
stride_x – [in] [rocblas_stride] stride from the start of one vector(x_i) and the next one (x_i+1).
C – [inout] device pointer to the first matrix C_0 on the GPU. Each C_i is of dimension ( ldc, n ).
ldc – [in] [rocblas_int] specifies the leading dimension of C.
stride_C – [in] [rocblas_stride] stride from the start of one matrix (C_i) and the next one (C_i+1).
batch_count – [in] [rocblas_int] number of instances i in the batch.
rocBLAS Beta Features#
To allow for future growth and changes, the features in this section are not subject to the same level of backwards compatibility and support as the normal rocBLAS API. These features are subject to change and/or removal in future release of rocBLAS.
To use the following beta API features, ROCBLAS_BETA_FEATURES_API must be defined before including rocblas.h.
rocblas_gemm_ex_get_solutions + batched, strided_batched#
-
rocblas_status rocblas_gemm_ex_get_solutions(rocblas_handle handle, rocblas_operation transA, rocblas_operation transB, rocblas_int m, rocblas_int n, rocblas_int k, const void *alpha, const void *a, rocblas_datatype a_type, rocblas_int lda, const void *b, rocblas_datatype b_type, rocblas_int ldb, const void *beta, const void *c, rocblas_datatype c_type, rocblas_int ldc, void *d, rocblas_datatype d_type, rocblas_int ldd, rocblas_datatype compute_type, rocblas_gemm_algo algo, uint32_t flags, rocblas_int *list_array, rocblas_int *list_size)#
BLAS BETA API
gemm_ex_get_solutions gets the indices for all the solutions that can solve a corresponding call to gemm_ex. Which solution is used by gemm_ex is controlled by the solution_index parameter.
All parameters correspond to gemm_ex except for list_array and list_size, which are used as input and output for getting the solution indices. If list_array is NULL, list_size is an output and will be filled with the number of solutions that can solve the GEMM. If list_array is not NULL, then it must be pointing to an array with at least list_size elements and will be filled with the solution indices that can solve the GEMM: the number of elements filled is min(list_size, # of solutions).
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
transA – [in] [rocblas_operation] specifies the form of op( A ).
transB – [in] [rocblas_operation] specifies the form of op( B ).
m – [in] [rocblas_int] matrix dimension m.
n – [in] [rocblas_int] matrix dimension n.
k – [in] [rocblas_int] matrix dimension k.
alpha – [in] [const void *] device pointer or host pointer specifying the scalar alpha. Same datatype as compute_type.
a – [in] [void *] device pointer storing matrix A.
a_type – [in] [rocblas_datatype] specifies the datatype of matrix A.
lda – [in] [rocblas_int] specifies the leading dimension of A.
b – [in] [void *] device pointer storing matrix B.
b_type – [in] [rocblas_datatype] specifies the datatype of matrix B.
ldb – [in] [rocblas_int] specifies the leading dimension of B.
beta – [in] [const void *] device pointer or host pointer specifying the scalar beta. Same datatype as compute_type.
c – [in] [void *] device pointer storing matrix C.
c_type – [in] [rocblas_datatype] specifies the datatype of matrix C.
ldc – [in] [rocblas_int] specifies the leading dimension of C.
d – [out] [void *] device pointer storing matrix D. If d and c pointers are to the same matrix then d_type must equal c_type and ldd must equal ldc or the respective invalid status will be returned.
d_type – [in] [rocblas_datatype] specifies the datatype of matrix D.
ldd – [in] [rocblas_int] specifies the leading dimension of D.
compute_type – [in] [rocblas_datatype] specifies the datatype of computation.
algo – [in] [rocblas_gemm_algo] enumerant specifying the algorithm type.
flags – [in] [uint32_t] optional gemm flags.
list_array – [out] [rocblas_int *] output array for solution indices or NULL if getting number of solutions
list_size – [inout] [rocblas_int *] size of list_array if getting solution indices or output with number of solutions if list_array is NULL
-
rocblas_status rocblas_gemm_batched_ex_get_solutions(rocblas_handle handle, rocblas_operation transA, rocblas_operation transB, rocblas_int m, rocblas_int n, rocblas_int k, const void *alpha, const void *a, rocblas_datatype a_type, rocblas_int lda, const void *b, rocblas_datatype b_type, rocblas_int ldb, const void *beta, const void *c, rocblas_datatype c_type, rocblas_int ldc, void *d, rocblas_datatype d_type, rocblas_int ldd, rocblas_int batch_count, rocblas_datatype compute_type, rocblas_gemm_algo algo, uint32_t flags, rocblas_int *list_array, rocblas_int *list_size)#
BLAS BETA API
rocblas_gemm_batched_ex_get_solutions gets the indices for all the solutions that can solve a corresponding call to gemm_batched_ex. Which solution is used by gemm_batched_ex is controlled by the solution_index parameter.
All parameters correspond to gemm_batched_ex except for list_array and list_size, which are used as input and output for getting the solution indices. If list_array is NULL, list_size is an output and will be filled with the number of solutions that can solve the GEMM. If list_array is not NULL, then it must be pointing to an array with at least list_size elements and will be filled with the solution indices that can solve the GEMM: the number of elements filled is min(list_size, # of solutions).
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
transA – [in] [rocblas_operation] specifies the form of op( A ).
transB – [in] [rocblas_operation] specifies the form of op( B ).
m – [in] [rocblas_int] matrix dimension m.
n – [in] [rocblas_int] matrix dimension n.
k – [in] [rocblas_int] matrix dimension k.
alpha – [in] [const void *] device pointer or host pointer specifying the scalar alpha. Same datatype as compute_type.
a – [in] [void *] device pointer storing array of pointers to each matrix A_i.
a_type – [in] [rocblas_datatype] specifies the datatype of each matrix A_i.
lda – [in] [rocblas_int] specifies the leading dimension of each A_i.
b – [in] [void *] device pointer storing array of pointers to each matrix B_i.
b_type – [in] [rocblas_datatype] specifies the datatype of each matrix B_i.
ldb – [in] [rocblas_int] specifies the leading dimension of each B_i.
beta – [in] [const void *] device pointer or host pointer specifying the scalar beta. Same datatype as compute_type.
c – [in] [void *] device array of device pointers to each matrix C_i.
c_type – [in] [rocblas_datatype] specifies the datatype of each matrix C_i.
ldc – [in] [rocblas_int] specifies the leading dimension of each C_i.
d – [out] [void *] device array of device pointers to each matrix D_i. If d and c are the same array of matrix pointers then d_type must equal c_type and ldd must equal ldc or the respective invalid status will be returned.
d_type – [in] [rocblas_datatype] specifies the datatype of each matrix D_i.
ldd – [in] [rocblas_int] specifies the leading dimension of each D_i.
batch_count – [in] [rocblas_int] number of gemm operations in the batch.
compute_type – [in] [rocblas_datatype] specifies the datatype of computation.
algo – [in] [rocblas_gemm_algo] enumerant specifying the algorithm type.
flags – [in] [uint32_t] optional gemm flags.
list_array – [out] [rocblas_int *] output array for solution indices or NULL if getting number of solutions
list_size – [inout] [rocblas_int *] size of list_array if getting solution indices or output with number of solutions if list_array is NULL
-
rocblas_status rocblas_gemm_strided_batched_ex_get_solutions(rocblas_handle handle, rocblas_operation transA, rocblas_operation transB, rocblas_int m, rocblas_int n, rocblas_int k, const void *alpha, const void *a, rocblas_datatype a_type, rocblas_int lda, rocblas_stride stride_a, const void *b, rocblas_datatype b_type, rocblas_int ldb, rocblas_stride stride_b, const void *beta, const void *c, rocblas_datatype c_type, rocblas_int ldc, rocblas_stride stride_c, void *d, rocblas_datatype d_type, rocblas_int ldd, rocblas_stride stride_d, rocblas_int batch_count, rocblas_datatype compute_type, rocblas_gemm_algo algo, uint32_t flags, rocblas_int *list_array, rocblas_int *list_size)#
BLAS BETA API
gemm_strided_batched_ex_get_solutions gets the indices for all the solutions that can solve a corresponding call to gemm_strided_batched_ex. Which solution is used by gemm_strided_batched_ex is controlled by the solution_index parameter.
All parameters correspond to gemm_strided_batched_ex except for list_array and list_size, which are used as input and output for getting the solution indices. If list_array is NULL, list_size is an output and will be filled with the number of solutions that can solve the GEMM. If list_array is not NULL, then it must be pointing to an array with at least list_size elements and will be filled with the solution indices that can solve the GEMM: the number of elements filled is min(list_size, # of solutions).
- Parameters:
handle – [in] [rocblas_handle] handle to the rocblas library context queue.
transA – [in] [rocblas_operation] specifies the form of op( A ).
transB – [in] [rocblas_operation] specifies the form of op( B ).
m – [in] [rocblas_int] matrix dimension m.
n – [in] [rocblas_int] matrix dimension n.
k – [in] [rocblas_int] matrix dimension k.
alpha – [in] [const void *] device pointer or host pointer specifying the scalar alpha. Same datatype as compute_type.
a – [in] [void *] device pointer pointing to first matrix A_1.
a_type – [in] [rocblas_datatype] specifies the datatype of each matrix A_i.
lda – [in] [rocblas_int] specifies the leading dimension of each A_i.
stride_a – [in] [rocblas_stride] specifies stride from start of one A_i matrix to the next A_(i + 1).
b – [in] [void *] device pointer pointing to first matrix B_1.
b_type – [in] [rocblas_datatype] specifies the datatype of each matrix B_i.
ldb – [in] [rocblas_int] specifies the leading dimension of each B_i.
stride_b – [in] [rocblas_stride] specifies stride from start of one B_i matrix to the next B_(i + 1).
beta – [in] [const void *] device pointer or host pointer specifying the scalar beta. Same datatype as compute_type.
c – [in] [void *] device pointer pointing to first matrix C_1.
c_type – [in] [rocblas_datatype] specifies the datatype of each matrix C_i.
ldc – [in] [rocblas_int] specifies the leading dimension of each C_i.
stride_c – [in] [rocblas_stride] specifies stride from start of one C_i matrix to the next C_(i + 1).
d – [out] [void *] device pointer storing each matrix D_i. If d and c pointers are to the same matrix then d_type must equal c_type and ldd must equal ldc and stride_d must equal stride_c or the respective invalid status will be returned.
d_type – [in] [rocblas_datatype] specifies the datatype of each matrix D_i.
ldd – [in] [rocblas_int] specifies the leading dimension of each D_i.
stride_d – [in] [rocblas_stride] specifies stride from start of one D_i matrix to the next D_(i + 1).
batch_count – [in] [rocblas_int] number of gemm operations in the batch.
compute_type – [in] [rocblas_datatype] specifies the datatype of computation.
algo – [in] [rocblas_gemm_algo] enumerant specifying the algorithm type.
flags – [in] [uint32_t] optional gemm flags.
list_array – [out] [rocblas_int *] output array for solution indices or NULL if getting number of solutions
list_size – [inout] [rocblas_int *] size of list_array if getting solution indices or output with number of solutions if list_array is NULL
Graph Support for rocBLAS#
Graph support is added as a beta feature in rocBLAS. Most of the rocBLAS functions can be captured into a graph node via Graph ManagementHIP APIs, except those listed in Functions Unsupported with Graph Capture. For complete list of support graph APIs, refer to Graph ManagementHIP API.
CHECK_HIP_ERROR((hipStreamBeginCapture(stream, hipStreamCaptureModeGlobal));
rocblas_<function>(<arguments>);
CHECK_HIP_ERROR(hipStreamEndCapture(stream, &graph));
The above code will create a graph with rocblas_function() as graph node. The captured graph can be launched as shown below:
CHECK_HIP_ERROR(hipGraphInstantiate(&instance, graph, NULL, NULL, 0));
CHECK_HIP_ERROR(hipGraphLaunch(instance, stream));
Graph support requires Asynchronous HIP APIs, hence, users must enable stream-order memory allocation. For more details refer to section Stream-Ordered Memory Allocation.
During stream capture, rocBLAS stores the allocated host and device memory in the handle and the allocated memory will be freed when the handle is destroyed.
Functions Unsupported with Graph Capture#
The following Level-1 functions place results into host buffers (in pointer mode host) which enforces synchronization.
dot
asum
nrm2
imax
imin
BLAS Level-3 and BLAS-EX functions in pointer mode device do not support HIP Graph. Support will be added in future releases.
HIP Graph Known Issues in rocBLAS#
On Windows platform, batched functions (Level-1, Level-2 and Level-3) produce incorrect results.
Device Memory Allocation in rocBLAS#
The following computational functions use temporary device memory.
Function |
use of temporary device memory |
|---|---|
|
reduction array |
|
result array before overwriting input column reductions of skinny transposed matrices |
|
block of matrix |
|
buffer to compress noncontiguous arrays |
For temporary device memory, rocBLAS uses a per-handle memory allocation with out-of-band management. The temporary device memory is stored in the handle. This allows for recycling temporary device memory across multiple computational kernels that use the same handle. Each handle has a single stream, and kernels execute in order in the stream, with each kernel completing before the next kernel in the stream starts. There are 4 schemes for temporary device memory:
rocBLAS_managed: This is the default scheme. If there is not enough memory in the handle, computational functions allocate the memory they require. Note that any memory allocated persists in the handle, so it is available for later computational functions that use the handle.
user_managed, preallocate: An environment variable is set before the rocBLAS handle is created, and thereafter there are no more allocations or deallocations.
user_managed, manual: The user calls helper functions to get or set memory size throughout the program, thereby controlling when allocation and deallocation occur.
user_owned: The user allocates workspace and calls a helper function to allow rocBLAS to access the workspace.
The default scheme has the disadvantage that allocation is synchronizing, so if there is not enough memory in the handle, a synchronizing deallocation and allocation occur.
Environment Variable for Preallocating#
The environment variable ROCBLAS_DEVICE_MEMORY_SIZE is used to set how much memory to preallocate:
If > 0, sets the default handle device memory size to the specified size (in bytes)
If == 0 or unset, lets rocBLAS manage device memory, using a default size (like 32MB), and expanding it when necessary
Functions for Manually Setting Memory Size#
rocblas_set_device_memory_size
rocblas_get_device_memory_size
rocblas_is_user_managing_device_memory
Function for Setting User Owned Workspace#
rocblas_set_workspace
Functions for Finding How Much Memory Is Required#
rocblas_start_device_memory_size_query
rocblas_stop_device_memory_size_query
rocblas_is_managing_device_memory
See the API section for information on the above functions.
rocBLAS Function Return Values for Insufficient Device Memory#
If the user preallocates or manually allocates, then that size is used as the limit, and no resizing or synchronizing ever occurs. The following two function return values indicate insufficient memory:
rocblas_status == rocblas_status_memory_error: indicates there is not sufficient device memory for a rocBLAS function
rocblas_status == rocblas_status_perf_degraded: indicates that a slower algorithm was used because of insufficient device memory for the optimal algorithm
Stream-Ordered Memory Allocation#
Stream-ordered device memory allocation is added to rocBLAS. Asynchronous allocators ( hipMallocAsync() and hipFreeAsync() ) are used to allow allocation and free to be stream order.
This is a non-default beta option enabled by setting the environment variable ROCBLAS_STREAM_ORDER_ALLOC.
A user may check if the device supports stream-order allocation by calling hipDeviceGetAttribute() with device attribute hipDeviceAttributeMemoryPoolsSupported.
Environment Variable to Enable Stream-Ordered Memory Allocation#
On supported platforms, environment variable ROCBLAS_STREAM_ORDER_ALLOC is used to enable stream-ordered memory allocation.
if > 0, sets the allocation to be stream-ordered, uses hipMallocAsync/hipFreeAsync to manage device memory.
if == 0 or unset, uses hipMalloc/hipFree to manage device memory.
Supports Switching Streams Without Any Synchronization#
Stream-order memory allocation allows swithcing of streams without the need to call hipStreamSynchronize().
Logging in rocBLAS#
Note that performance will degrade when logging is enabled.
User can set four environment variables to control logging:
ROCBLAS_LAYERROCBLAS_LOG_TRACE_PATHROCBLAS_LOG_BENCH_PATHROCBLAS_LOG_PROFILE_PATH
ROCBLAS_LAYER is a bitwise OR of zero or more bit masks as follows:
If
ROCBLAS_LAYERis not set, then there is no logging.If
(ROCBLAS_LAYER & 1) != 0, then there is trace logging.If
(ROCBLAS_LAYER & 2) != 0, then there is bench logging.If
(ROCBLAS_LAYER & 4) != 0, then there is profile logging.
Trace logging outputs a line each time a rocBLAS function is called. The line contains the function name and the values of arguments.
Bench logging outputs a line each time a rocBLAS function is called. The
line can be used with the executable rocblas-bench to call the
function with the same arguments.
Profile logging, at the end of program execution, outputs a YAML
description of each rocBLAS function called, the values of its
performance-critical arguments, and the number of times it was called
with those arguments (the call_count). Some arguments, such as
alpha and beta in GEMM, are recorded with a value representing
the category that the argument falls in, such as -1, 0, 1,
or 2. The number of categories, and the values representing them,
may change over time, depending on how many categories are needed to
adequately represent all the values that can affect the performance
of the function.
The default stream for logging output is standard error. Three environment variables can set the full path name for a log file:
ROCBLAS_LOG_TRACE_PATHsets the full path name for trace logging.ROCBLAS_LOG_BENCH_PATHsets the full path name for bench logging.ROCBLAS_LOG_PROFILE_PATHsets the full path name for profile logging.
For example, in Bash shell, to output bench logging to the file
bench_logging.txt in your present working directory:
export ROCBLAS_LOG_BENCH_PATH=$PWD/bench_logging.txt
Note that a full path is required, not a relative path. In the above command $PWD expands to the full path of your present working directory. If paths are not set, then the logging output is streamed to standard error.
When profile logging is enabled, memory usage increases. If the program exits abnormally, then it is possible that profile logging will not be outputted before the program exits.
References:
Lawson, R. J. Hanson, D. Kincaid, and F. T. Krogh, Basic Linear Algebra Subprograms for FORTRAN usage, ACM Trans. Math. Soft., 5 (1979), pp. 308–323.
Dongarra, J. Du Croz, S. Hammarling, and R. J. Hanson, An extended set of FORTRAN Basic Linear Algebra Subprograms, ACM Trans. Math. Soft., 14 (1988), pp. 1–17
Dongarra, J. Du Croz, S. Hammarling, and R. J. Hanson, Algorithm 656: An extended set of FORTRAN Basic Linear Algebra Subprograms, ACM Trans. Math. Soft., 14 (1988), pp. 18–32